迈向外存多维数组 -- 多核调度
这项工作由 Continuum Analytics 和 XDATA 项目 提供支持,作为 Blaze 项目 的一部分
太长不看 我们展示了一个多线程共享内存任务调度器。我们分享了两种用于空间受限计算的技术。最后展示了一些漂亮的 GIF。
免责声明:本文基于实验性代码,可能包含错误。尚未准备好供公众使用。
免责声明 2:本文是技术性的,面向关心任务调度的人,不适用于传统用户。
设置
我的前两篇文章(文章 1, 文章 2)基于一个简单的任务调度器、NumPy 和 Blaze 构建了一个多维数组库。
在本文中,我们将讨论一个更复杂的调度器。我们将概述一个不那么优雅但更有效的调度器,它使用多线程和缓存,在一类有趣的数组操作上实现了性能提升。
我们创建调度策略,以最大程度地减少计算的内存占用。
示例
首先,我们通过做好一件困难的事情来确立价值。假设有两个存储在 HDF5 中的大型数组
import h5py
f = h5py.File('myfile.hdf5')
A = f.create_dataset(name='A', shape=(4000, 2000000), dtype='f8',
chunks=(250, 250), fillvalue=1.0)
B = f.create_dataset(name='B', shape=(4000, 4000), dtype='f8',
chunks=(250, 250), fillvalue=1.0)
f.close()
我们进行转置和点积运算。
from blaze import Data, into
from dask.obj import Array
f = h5py.File('myfile.hdf5')
a = into(Array, f['A'], blockshape=(1000, 1000), name='A')
b = into(Array, f['B'], blockshape=(1000, 1000), name='B')
A = Data(a)
B = Data(b)
expr = A.T.dot(B)
result = into('myfile.hdf5::/C', expr)
这利用了我们所有的核心,并且只需要大约 100MB 内存即可完成。这令人印象深刻,因为输入、输出或计算的任何中间阶段都无法全部装入内存。
我们未能完全实现这一点(见底部注释),但尽管如此,理论上,我们很棒!
避免中间数据
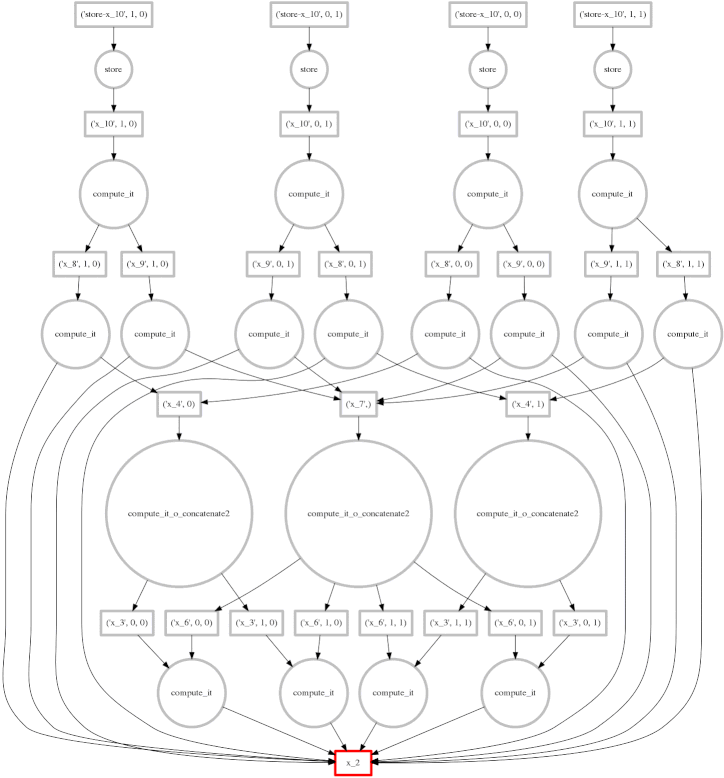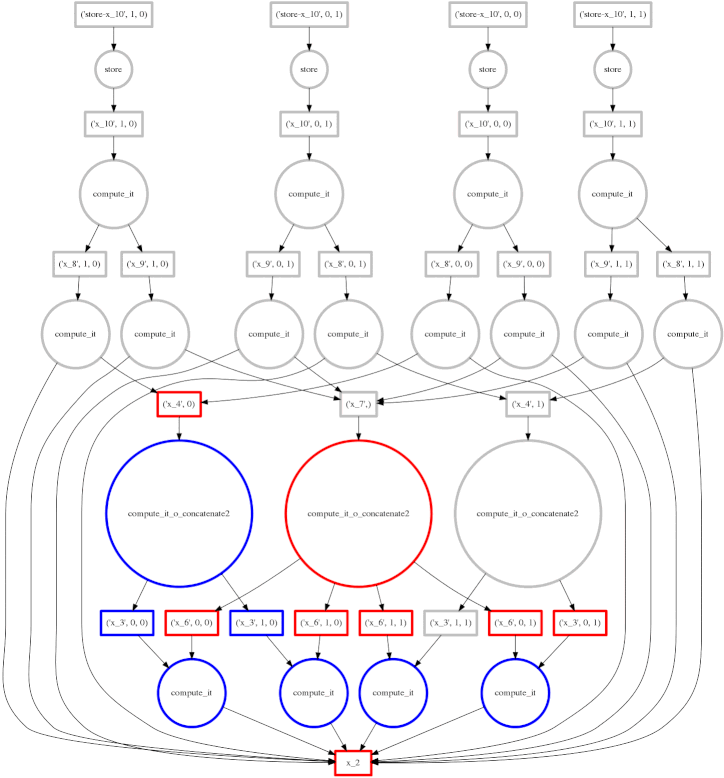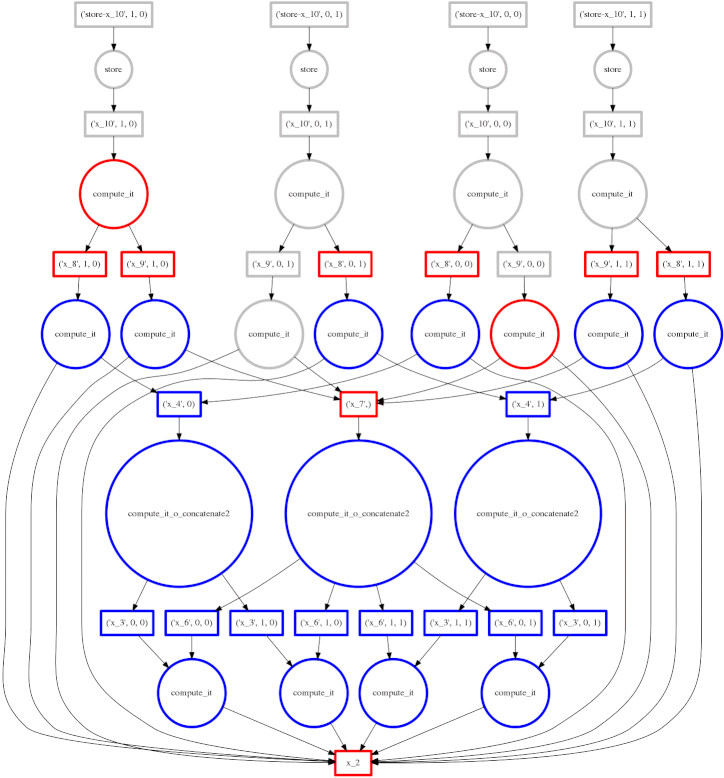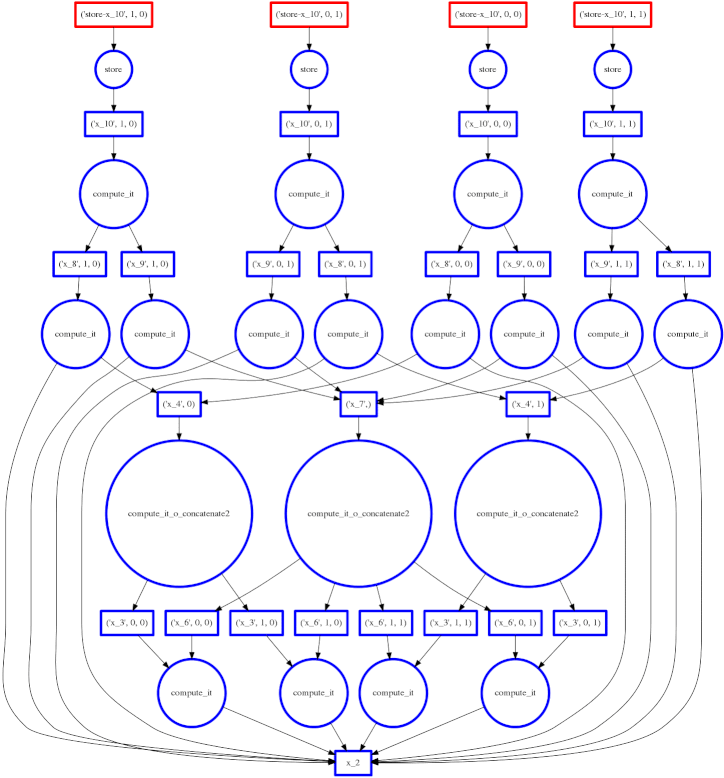
为了保持较小的内存占用,我们避免保留不必要的中间数据。一个较小问题的完整计算图可能如下所示
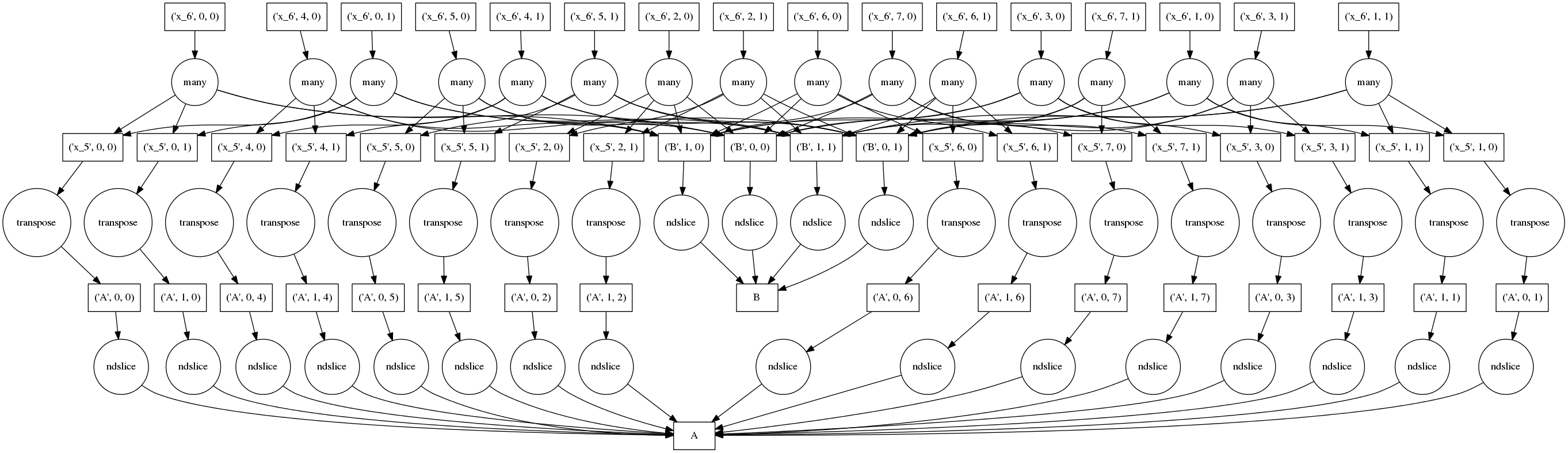
方框代表数据,圆圈代表对该数据运行的函数,箭头表示哪些函数产生/消费哪些数据。
顶部的圆圈代表实际的分块点积运算(注意从它们发出的许多数据依赖箭头)。底部的圆圈代表将 A HDF5 数据集中的数据块提取到内存中的 numpy 数组。第二行对第一行的数据块进行转置,并添加来自 B 的更多数据块。
天真地执行这个图可能非常糟糕;我们在这里复制了四次数据,每一行一次。我们提取所有的块,对每个块进行转置,然后最后进行点积运算。如果我们无法将原始数据全部装入内存,那么这种方式将无法奏效。
函数内联
我们通过两种方式解决这个问题。首先,我们不缓存运行快的函数(如 np.transpose)的中间值。相反,我们将运行快的函数内联到包含开销大的函数(如 np.dot)的任务中。我们最终可能运行同一个快速函数两次,但至少我们不必存储结果。我们以计算换取内存。
将上述图中的所有访问和转置操作内联后的结果如下所示

现在我们的任务是嵌套的(见下文)。我们将嵌套任务中的所有函数作为单一操作运行。(非 LISP 用户请回避)
('x_6', 6, 0): (dotmany, [(np.transpose, (ndslice, 'A', (1000, 1000), 0, 6)),
(np.transpose, (ndslice, 'A', (1000, 1000), 1, 6))],
[(ndslice, 'B', (1000, 1000), 0, 0),
(ndslice, 'B', (1000, 1000), 1, 0)]),
这有效地将所有存储责任推回到 HDF5 存储中。我们最终会多次提取相同的块,但在大型复杂问题上,重复的磁盘访问是不可避免的。
这是自动的。Dask 现在包含一个名为 inline 的函数,可以为你完成此操作。你只需要给它一组要忽略的“快”函数,例如
dsk2 = inline(dsk, [np.transpose, ndslice, add, mul, ...])
调度器
现在我们有了一个不错的 dask 图来计算,我们使用多个工作线程来运行这些任务。这是调度器的职责。

我们在这里构建并文档化了这样一个调度器。它针对共享内存的单进程多线程环境。它取代了优雅的 20 行参考解决方案,变成了一大坨充满锁和可变状态的丑陋代码。尽管如此,它仍然理智地管理计算,执行了一些关键优化,并利用了我们所有的硬件核心(摩尔定律已死!摩尔定律万岁!)
许多 NumPy 操作会释放 GIL,因此非常适合多线程。NumPy 程序不受大多数 Python 代码的单进程单活跃核心限制。
方法
我们遵循一个相当标准的模型。我们创建一个固定数量工作线程的 ThreadPool。我们分析 dask 图以确定“准备运行”的任务。我们将一个任务发送给每个工作线程。它们完成后会更新运行状态,将作业标记为已完成,将结果插入共享缓存,然后根据新可用的数据将新作业标记为准备就绪。这个更新过程完全由工作线程自己进行索引和处理(带有适当的锁),使得开销可以忽略不计,并有望扩展到复杂工作负载。
当一个新可用的工作线程选择一个新的准备就绪的任务时,通常有几个可供选择。我们有一个选择。我们在这里做出的选择非常重要。下一节将讨论我们的选择策略
选择完成后立即释放数据资源的任务
优化
我们偏好释放资源的任务的策略使我们能够在非常小的空间内运行许多计算。我们现在展示三个表达式、它们产生的调度,以及一个动画展示调度器如何遍历这些调度。这些取自实际运行过程。
示例:易并行计算
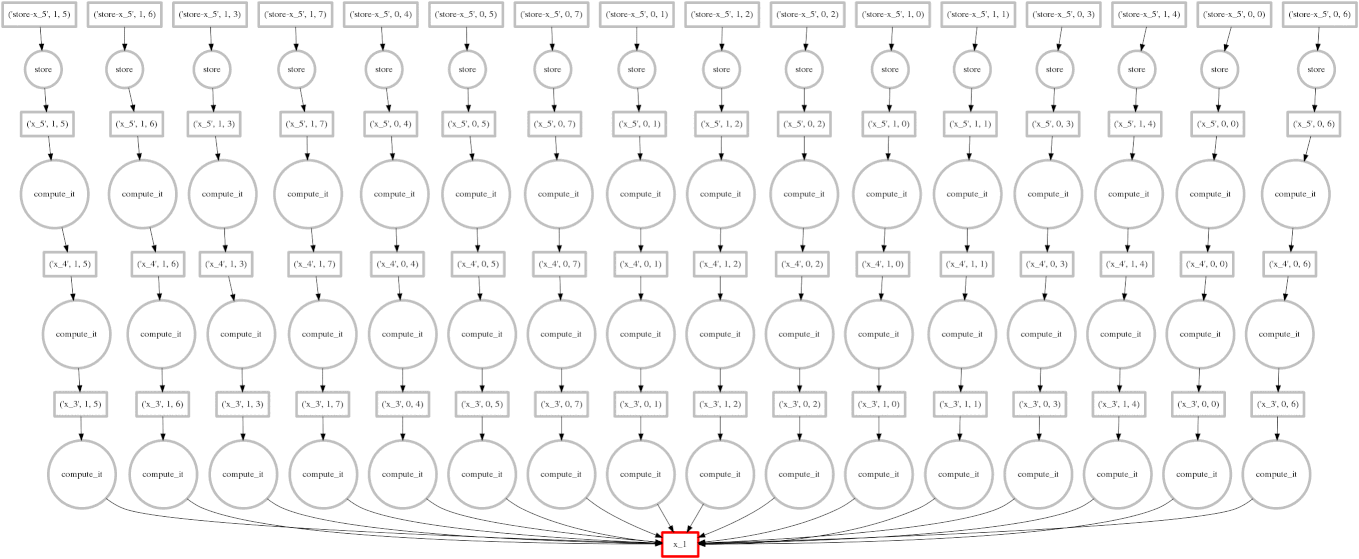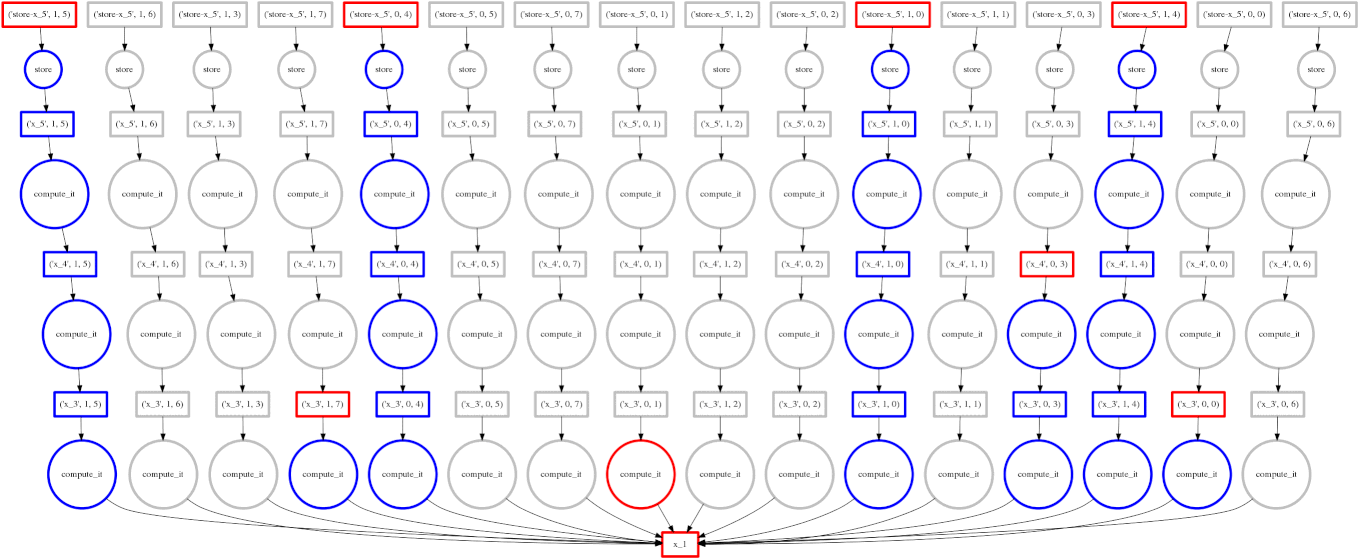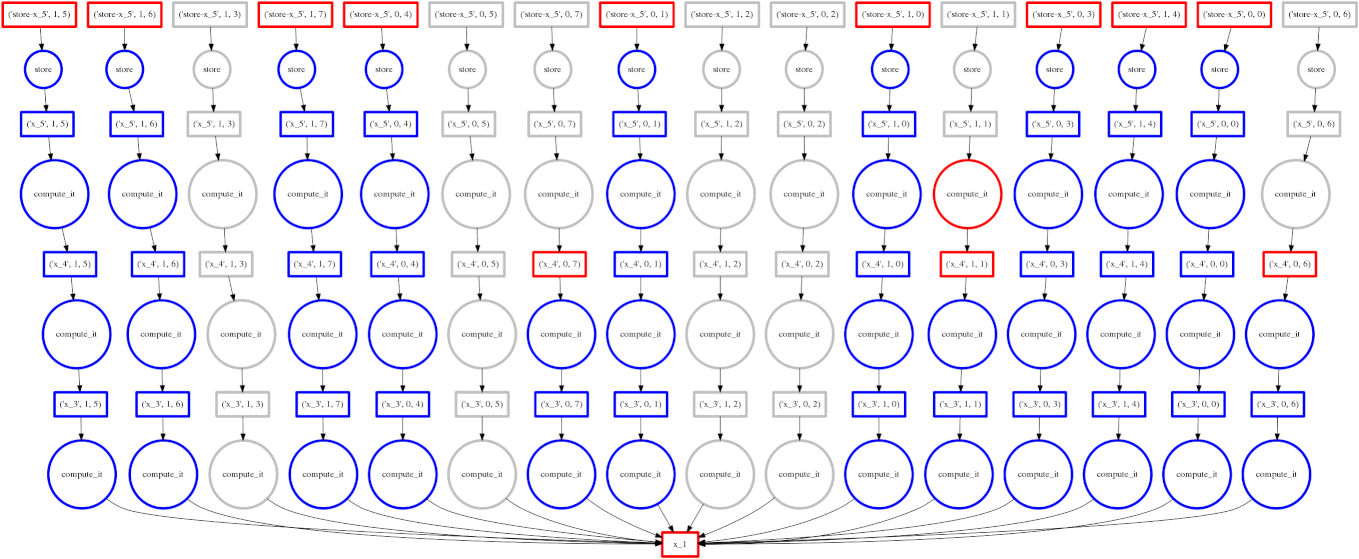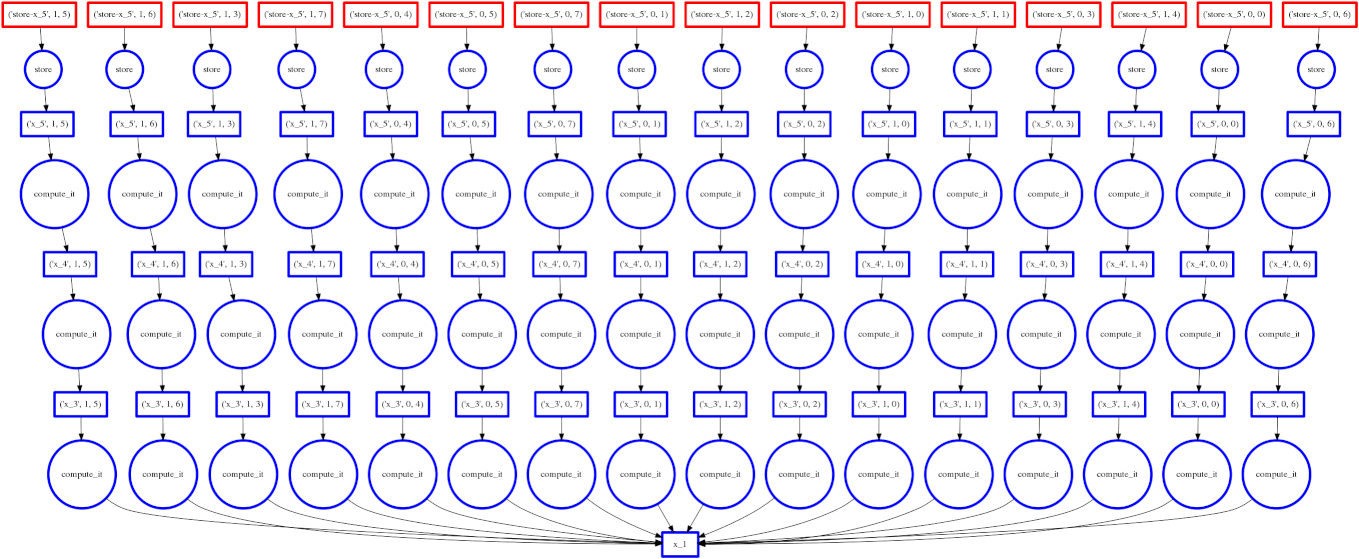
在右侧,我们展示了如下所示的易并行计算的进程动画 GIF
expr = (((A + 1) * 2) ** 3)
圆圈代表计算,方框代表数据。
红色意味着正在占用资源。红色是不好的。
- 红色圆圈:当前在线程中执行的任务
- 红色方框:当前驻留在缓存中并占用宝贵内存的数据
蓝色意味着已完成或已释放。蓝色是好的。
- 蓝色圆圈:已完成的任务
- 蓝色方框:已从内存释放的数据,因为任何任务都不再需要它
我们希望将所有节点变为蓝色,同时最大限度地减少在任何给定时间存在的红色方框数量。
执行释放资源任务的策略可能时导致“垂直”执行。在这个示例中,我们的方法是最优的,因为在整个计算过程中,红色方框的数量保持在较低水平。我们的四个线程每个只有一个红色方框。
示例:包含规约的更复杂计算
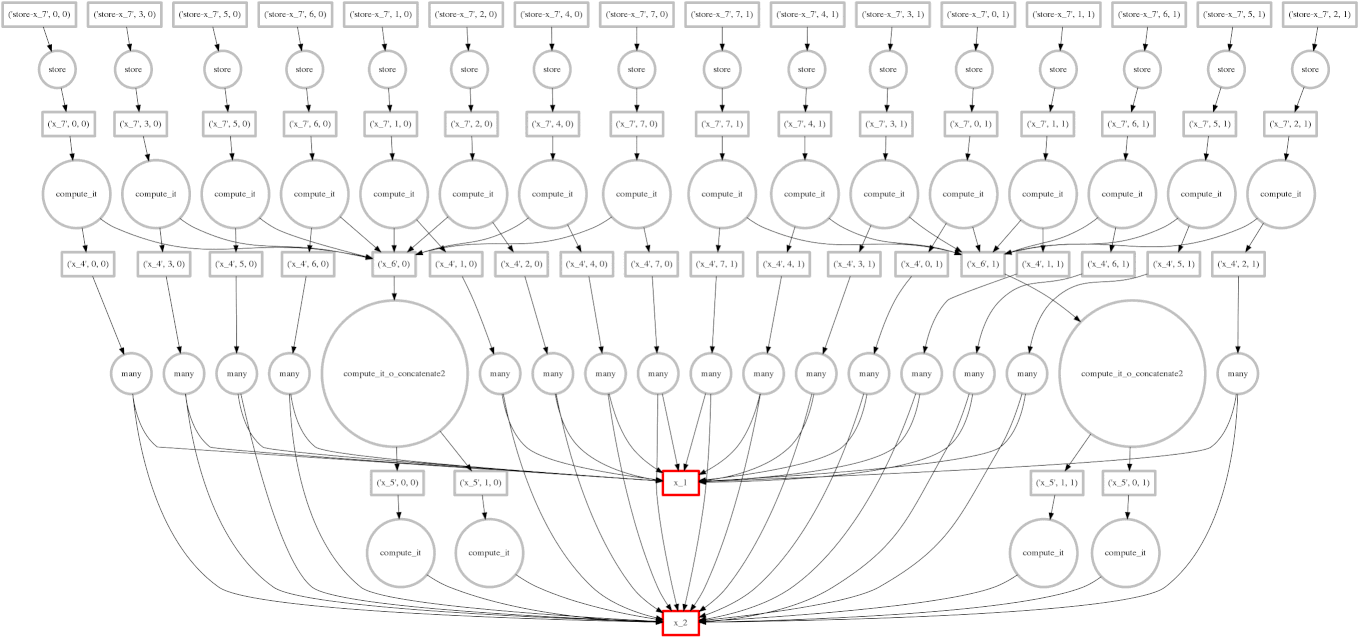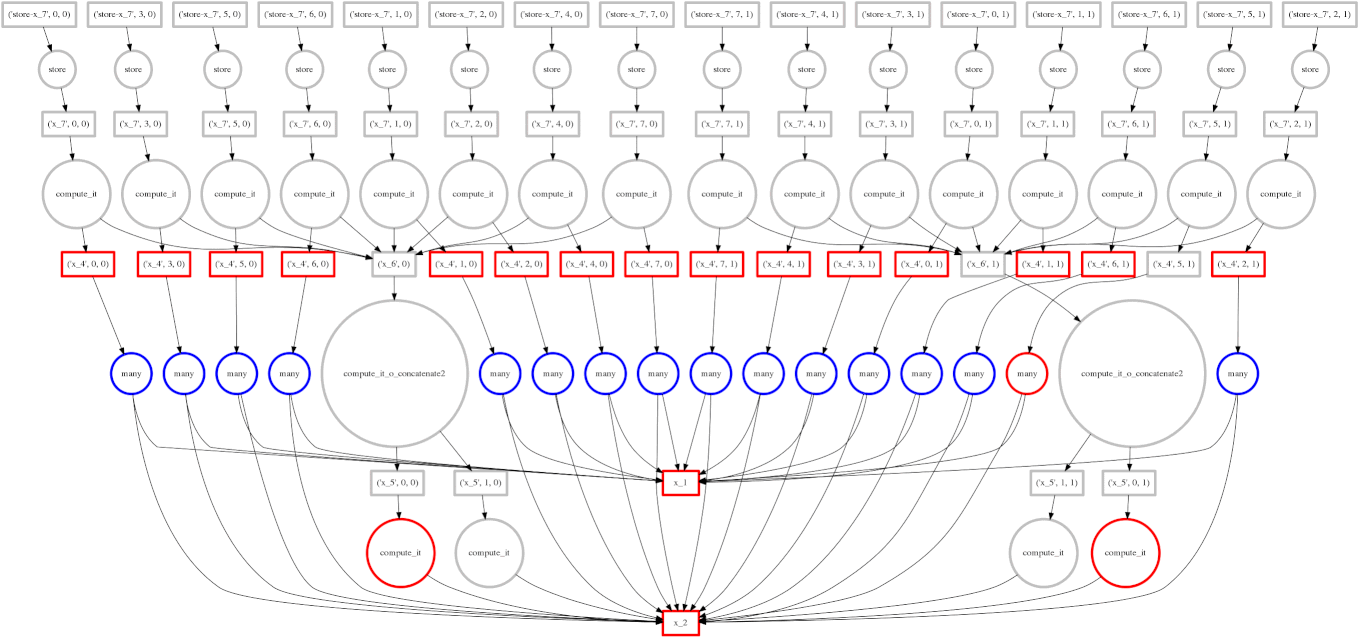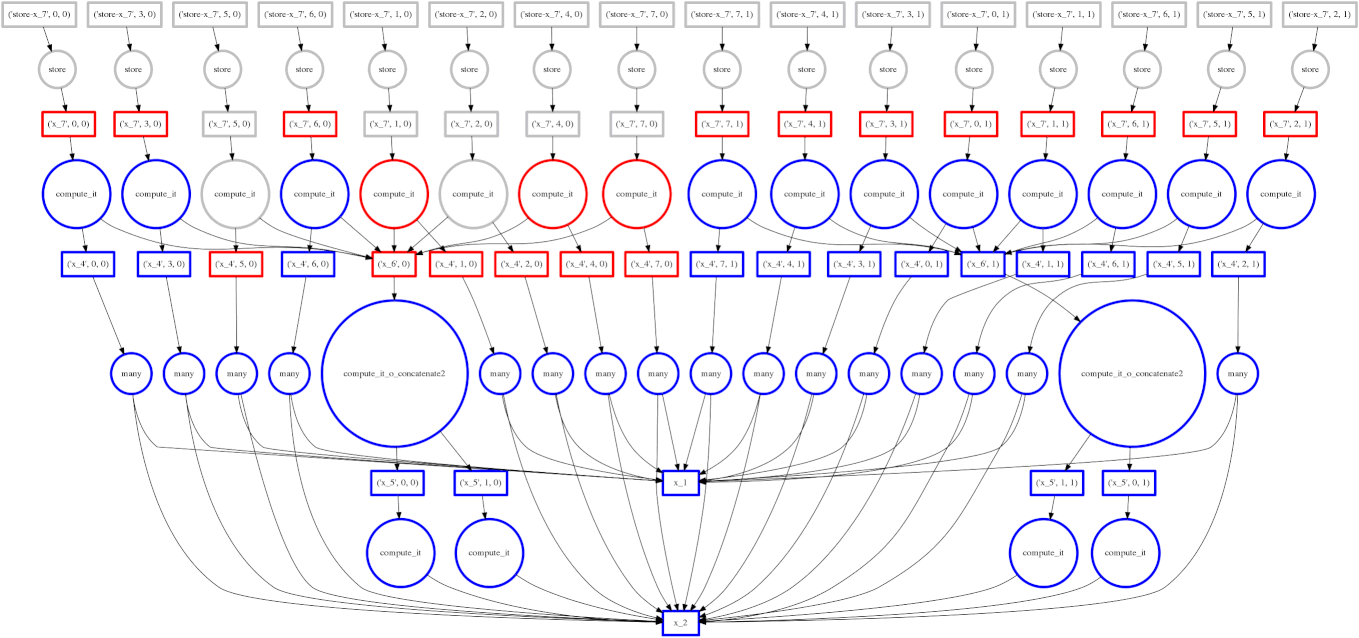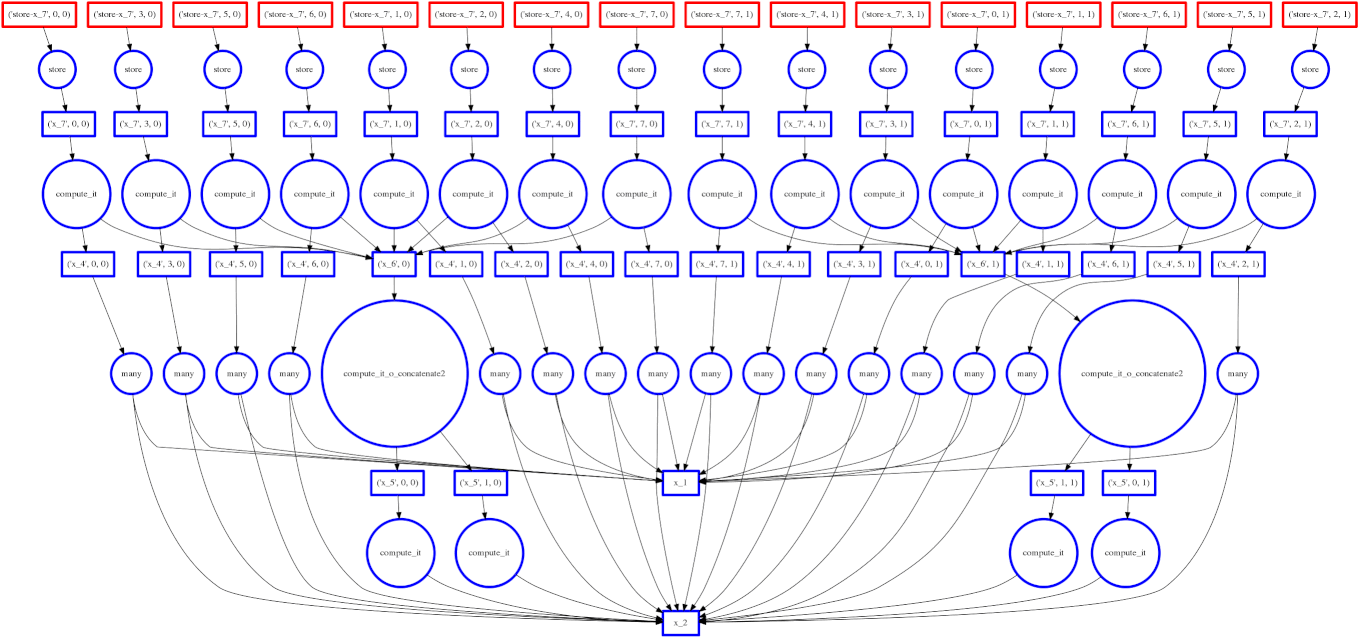
我们展示一个更复杂的表达式
expr = (B - B.mean(axis=0)) + (B.T / B.std())
这把我们迄今为止看到的表达式类别扩展到规约和沿轴的规约。每块的规约从底部开始,只依赖于它们来自的块。然后将这些每块的结果连接在一起,并用大的圆圈(放大看看里面的 concatenate 文本)再次进行规约。下一层采用这些(小)结果和原始数据(注意连接到底部数据资源的的长边),这会产生每块的减法和除法。
从那里开始,工作变得易并行,类似于上面的计算。在这种情况下,我们的并行性相对较低,因此红色方框的前沿覆盖了整个图像;幸运的是数据集很小。
示例:失败案例
我们展示一个我们的贪婪解彻底失败的案例
expr = (A.T.dot(B) - B.mean(axis=0))
从底部数第二层上的两个大函数是计算 mean(平均值)的函数。这些开销很低,完成后,使得点积的每个块都能快速终止并释放内存。
悲剧的是,这些 mean 计算在最后可能的时刻才执行,使点积的所有结果都困在缓存中。在计算的某个时刻,我们几乎有一整行的红色方框。
在这种情况下,我们的贪婪解是短视的;一个稍微更全局性的解决方案会快速选择这些大的圆圈以快速运行。也许中介中心性可以解决这个问题。
磁盘缓存
我们永远无法构建一个足够好的调度器。我们需要能够回退到磁盘缓存。实际上这并不糟糕。高性能 SSD 的吞吐量接近 1 GB/秒,而在数据感知调度失败的复杂情况下,我们的计算速度可能本身就比这慢。
我为此有一个小的磁盘支持的字典项目,chest,但它还不成熟。总的来说,我希望看到更多项目以有趣的策略实现 dict 接口。
二进制数据存储的问题
我得承认,第一个计算,那个非常大的点积运算,有时会让我的机器崩溃。虽然调度器很好地管理了内存,但我某个地方有内存泄漏。我怀疑我错误地使用了 HDF5。
我也尝试使用 bcolz 来做这件事。可惜 n维分块支持得不好。邮件讨论 1 和 邮件讨论 2。
表达式范围
Blaze 目前为以下内容生成 dask 计算图
- 逐元素操作(如
+,*,exp,log, …) - 维度重排,如
np.transpose - 张量收缩,如
np.tensordot - 规约,如
np.mean(..., axis=...) - 以上所有组合
我们也符合这些操作的 NumPy API。截至撰写本文时,显著缺失的元素包括以下内容
- 切片(尽管这应该很容易添加)
- 求解、SVD 或任何更复杂的线性代数运算。其他线性代数软件(Plasma, Flame, Elemental, …)中已经实现了很好的解决方案,但在很多人开始要求之前,我不打算走这条路。
- 任何 NumPy 做不到的事情。
我很想听听社区认为什么重要。重新实现整个 NumPy 是困难的,重新实现 NumPy 的几个精选部分相对来说是直观的。知道那几个精选部分是什么需要社区参与。
更大的想法
我构建动态调度器的经验有限,我的方法可能不是最优的。很高兴看到其他方法。本文中的逻辑并非 Blaze 或 NumPy 特有。要构建一个调度器,你只需要理解带有数据依赖关系的计算图模型。
如果我们有更大的野心,我们可能会考虑一个分布式调度器,用于在分布式内存环境(如集群)中的许多节点上执行这些任务图。这是一个难题,但它将开启另一类计算解决方案。Blaze 生成 dask 计算图的代码不会改变;我们生成的图与我们选择的调度器是无关的。
帮助
我需要这方面的帮助,可以是开源工作(见下方链接),也可以是付费合作。Continuum 有雇员资金和充足的有趣问题。
链接
博客评论由 Disqus 提供支持