迈向核外 ND 数组 -- 溢写到磁盘
这项工作得到了 Continuum Analytics 和 XDATA 项目 的支持,作为 Blaze 项目 的一部分
tl;dr 我们实现了一个在内存不足时会将数据溢写到磁盘的字典。我们将它连接到了我们的调度器。
引言
这是关于使用 NumPy、Blaze 和 dask 构建核外 nd 数组的系列文章中的第五篇。你可以在这里查看这些文章:
现在我们介绍 chest,这是一种在内存不足时会将数据溢写到磁盘的 dict 类型。我们将展示它如何防止大型计算淹没内存。
中间数据
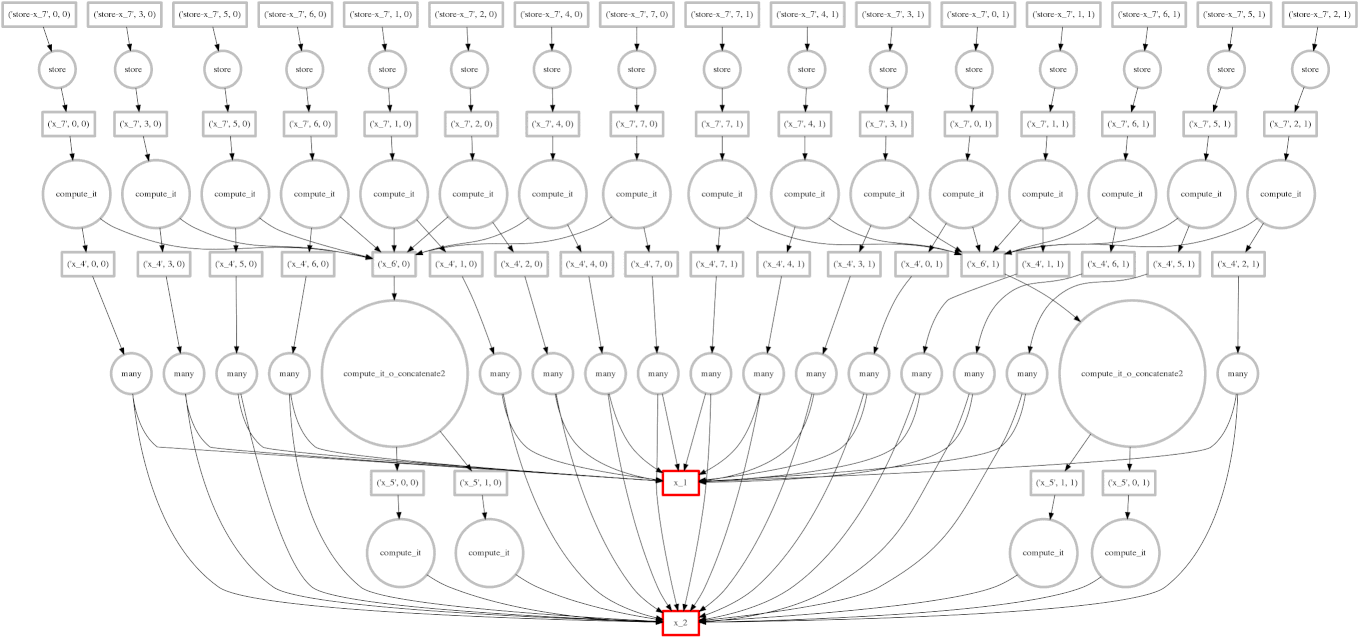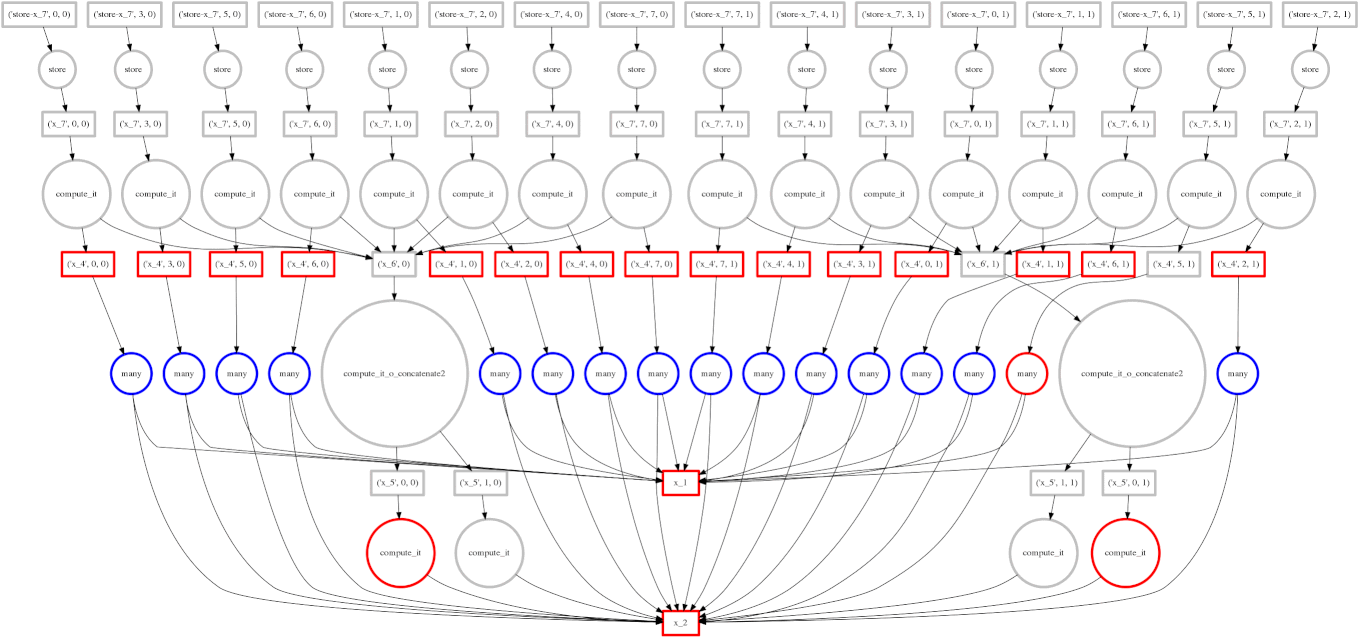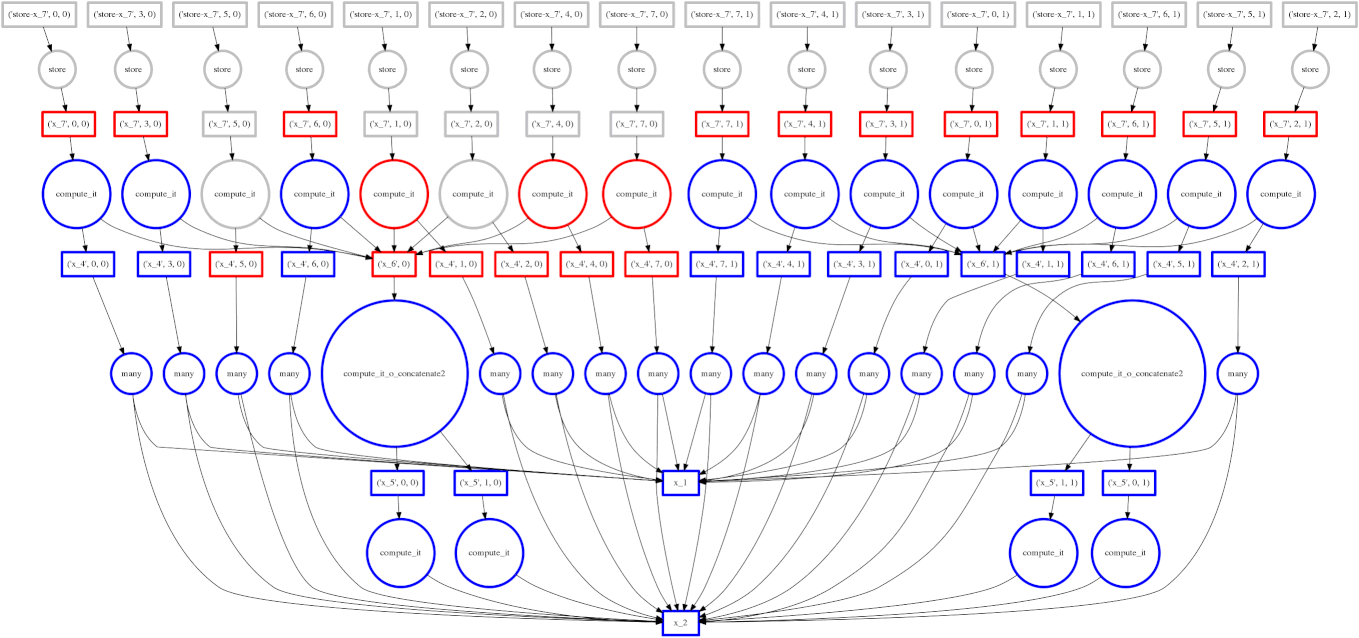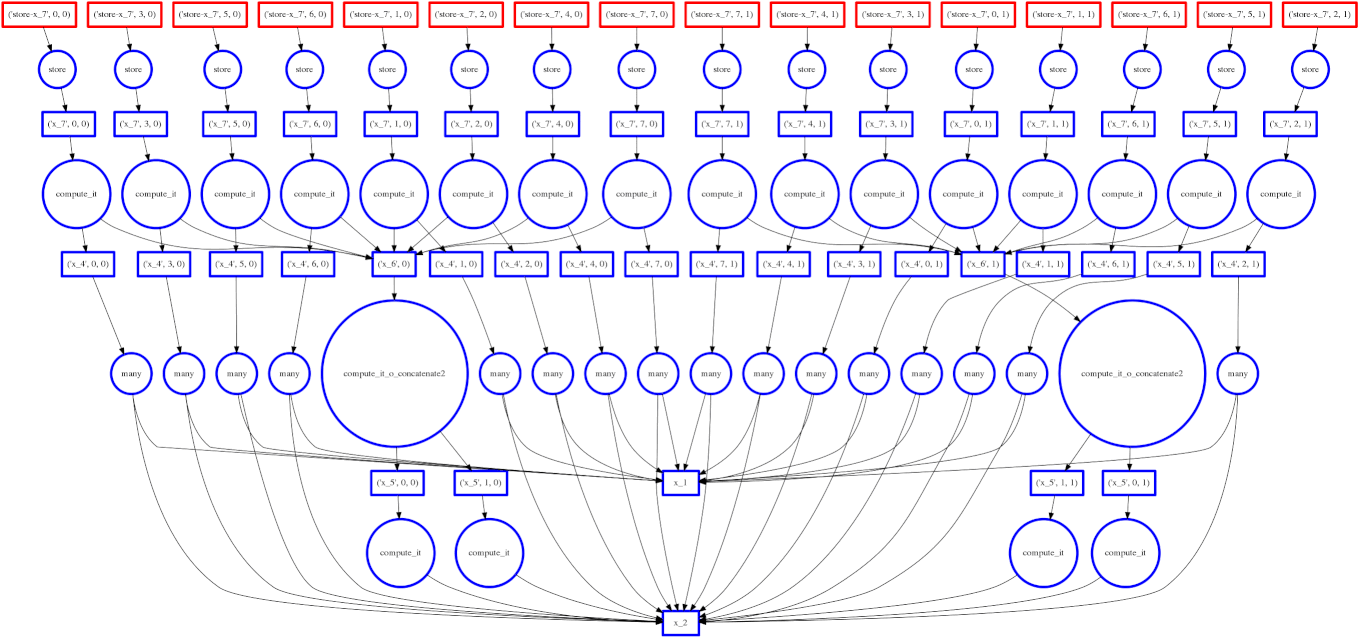
如果你阅读了关于调度的文章,你可能还记得我们的目标是在多工作器计算期间尽量减少中间存储。右边的图像显示了我们的调度器遍历任务依赖图的轨迹。我们希望快速计算整个图,同时只在内存中保留少量数据。
有时我们失败了,我们的调度器存储了许多大型中间结果。在这些情况下,我们希望将多余的中间数据溢写到磁盘,而不是淹没本地内存。
Chest
Chest 是一个类似 dict 的对象,在内存不足时会将数据写入磁盘。
>>> from chest import Chest
>>> d = Chest(available_memory=1e9) # Only use a GigaByte
它满足 MutableMapping 接口,因此它的外观和感觉与 dict 完全一样。下面我们展示一个使用 chest 的示例,它在内存中只存储一个 Python 整数所需的数据。
>>> d = Chest(available_memory=24) # enough space for one Python integer
>>> d['one'] = 1
>>> d['two'] = 2
>>> d['three'] = 3
>>> d['three']
3
>>> d.keys()
['one', 'two', 'three']
我们将一些数据保存在内存中
>>> d.inmem
{'three': 3}
而其余的数据则保存在磁盘上
>>> d.path
'/tmp/tmpb5ouAb.chest'
>>> os.listdir(d.path)
['one', 'two']
默认情况下,我们使用 pickle 存储数据,但 chest 支持任何具有 dump/load 接口的协议(pickle、json、cbor、joblib 等)
关于 pickle 的一个快速提示。我的博客的常客可能知道我对于这个库如何序列化函数以及其对多处理的 crippling 影响感到悲伤。这种悲伤不适用于普通数据。如果你使用 pickle.dump 的 protocol= 关键字正确地使用 pickle,它对于数据来说是很好的。Pickle 不是一个好的跨语言解决方案,但这在我们临时将 numpy 数组存储到磁盘的应用中并不重要。
近期调整
为了在 dask 中成功地使用 chest,我对原始实现进行了以下改进:
- 一个基本的 LRU 机制,只写入不经常使用的数据
- 一个策略,避免将未更改的相同数据写入磁盘两次
- 线程安全
现在我们可以执行更多的 dask 工作流程,而不会有内存溢出的风险
A = ...
B = ...
expr = A.T.dot(B) - B.mean(axis=0)
cache = Chest(available_memory=1e9)
into('myfile.hdf5::/result', expr, cache=cache)
现在,即使我们调度不佳并遇到大量中间数据,也只会产生中等的性能下降。
结论
Chest 仅在我们调度不佳时有用。我们仍然可以改进调度算法以避免将数据保留在内存中,但是有 chest 作为这些算法失败时的备份是很好的。弹性让人放心。
博客评论由 Disqus 提供支持