迈向核外ND数组 -- 切片与堆叠
这项工作由 Continuum Analytics 和 XDATA 项目 支持,是 Blaze 项目 的一部分
tl;dr Dask.arrays 可以进行切片和堆叠。这对于气象数据很有用。
引言
这是关于使用 NumPy 和 Dask 构建核外 nd-array 的系列文章的第六篇。你可以在这里查看这些文章:
现在我们讨论切片和堆叠。我们使用气象数据作为示例用例。
切片
Dask.array 现在支持大多数 NumPy 的切片语法。特别是它支持以下方式:
- 按整数和切片进行切片
x[0, :5] - 按整数
list/np.ndarray进行切片x[[1, 2, 4]] - 按布尔值
list/np.ndarray进行切片x[[False, True, True, False, True]]
它目前不支持以下方式:
- 用一个
dask.array对另一个进行切片x[x > 0] - 在多个轴上使用列表进行切片
x[[1, 2, 3], [3, 2, 1]]
堆叠与连接 (Stack and Concatenate)
我们经常将大型数组存储在磁盘上的许多不同文件中。我们希望将这些数组堆叠或连接在一起形成一个逻辑数组。Dask 通过 stack 和 concatenate 函数解决了这个问题,它们将多个数组缝合在一起形成一个单一数组,stack 创建一个新的维度,而 concatenate 沿现有维度进行连接。
堆叠 (Stack)
我们将许多现有的 dask 数组堆叠成一个新数组,在此过程中创建一个新的维度。
>>> import dask.array as da
>>> arrays = [from_array(np.ones((4, 4)), blockshape=(2, 2))
... for i in range(3)] # A small stack of dask arrays
>>> da.stack(arrays, axis=0).shape
(3, 4, 4)
>>> da.stack(arrays, axis=1).shape
(4, 3, 4)
>>> da.stack(arrays, axis=2).shape
(4, 4, 3)
这创建了一个新维度,其长度等于切片数量。
连接 (Concatenate)
我们将现有数组连接成一个新数组,沿现有维度扩展它们。
>>> import dask.array as da
>>> arrays = [from_array(np.ones((4, 4)), blockshape=(2, 2))
... for i in range(3)] # small stack of dask arrays
>>> da.concatenate(arrays, axis=0).shape
(12, 4)
>>> da.concatenate(arrays, axis=1).shape
(4, 12)
气象数据案例研究
为了测试这项新功能,我们从 欧洲中期天气预报中心 下载了 气象数据。特别是我们拥有 2014 年全年每六小时的地球温度数据,空间分辨率为四分之一度。我们使用 这个脚本 下载了这些数据(请不要不必要地轰炸他们的服务器)(感谢 Stephan Hoyer 指引我找到这个数据集)。
结果,我现在有一堆 netCDF 文件!
$ ls
2014-01-01.nc3 2014-03-18.nc3 2014-06-02.nc3 2014-08-17.nc3 2014-11-01.nc3
2014-01-02.nc3 2014-03-19.nc3 2014-06-03.nc3 2014-08-18.nc3 2014-11-02.nc3
2014-01-03.nc3 2014-03-20.nc3 2014-06-04.nc3 2014-08-19.nc3 2014-11-03.nc3
2014-01-04.nc3 2014-03-21.nc3 2014-06-05.nc3 2014-08-20.nc3 2014-11-04.nc3
... ... ... ... ...
>>> import netCDF4
>>> t = netCDF4.Dataset('2014-01-01.nc3').variables['t2m']
>>> t.shape
(4, 721, 1440)
形状对应于每天四次测量(24小时/6小时),南北方向 720 次测量(180/0.25),东西方向 1440 次测量(360/0.25)。共有 365 个文件。
太好了!我们将这些文件收集到一个逻辑 dask 数组下,沿着时间轴进行连接。
>>> from glob import glob
>>> filenames = sorted(glob('2014-*.nc3'))
>>> temps = [netCDF4.Dataset(fn).variables['t2m'] for fn in filenames]
>>> import dask.array as da
>>> arrays = [da.from_array(t, blockshape=(4, 200, 200)) for t in temps]
>>> x = da.concatenate(arrays, axis=0)
>>> x.shape
(1464, 721, 1440)
现在我们可以像使用 NumPy 数组一样使用 x 进行操作。
avg = x.mean(axis=0)
diff = x[1000] - avg
如果我们想实际计算这些结果,我们有几种选择:
>>> diff.compute() # compute result, return as array, float, int, whatever is appropriate
>>> np.array(diff) # compute result and turn into `np.ndarray`
>>> diff.store(anything_that_supports_setitem) # For out-of-core storage
另一种方法是,由于许多科学计算 Python 库会对其输入调用 np.array,我们可以直接将 da.Array 对象输入到 matplotlib 中(__array__ 协议万岁!)
>>> from matplotlib import imshow
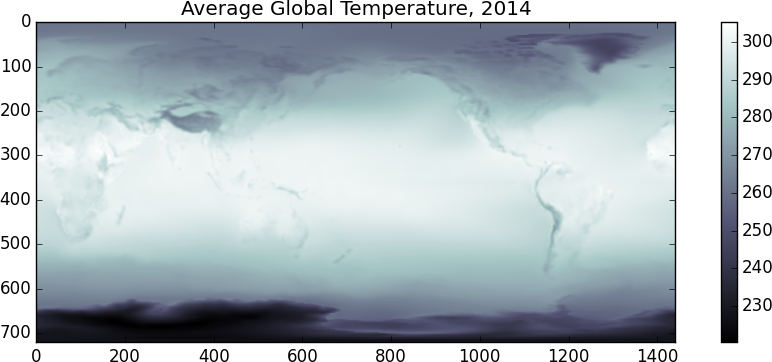
>>> imshow(x.mean(axis=0), cmap='bone')
>>> imshow(x[1000] - x.mean(axis=0), cmap='RdBu_r')
 |
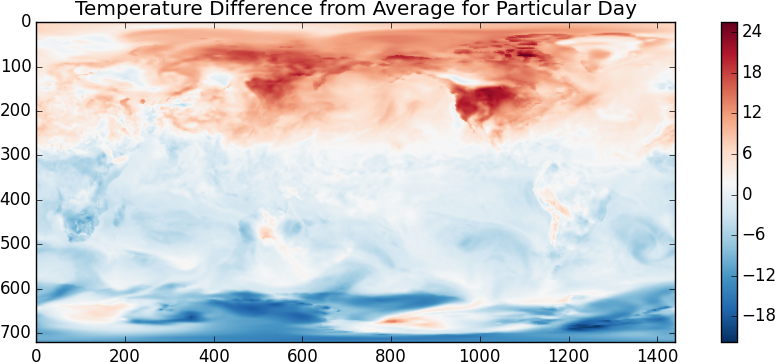 |
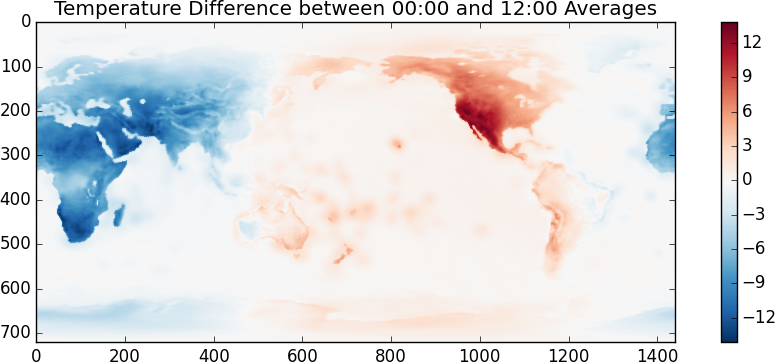
我怀疑温度单位是开尔文。看来随机选择的这一天是在北半球夏季。另一个有趣的事情是,我们来看看 00:00 和 12:00 的温度差异。
>>> imshow(x[::4].mean(axis=0) - x[2::4].mean(axis=0), cmap='RdBu_r')
尽管这看起来和用起来都像 NumPy,但我们实际上是使用分块算法在磁盘上进行操作。我们执行这些操作时只需要少量内存。如果这些操作计算密集(它们不是),那么我们也将受益于多核并行。
刚才发生了什么
为了完全清楚,刚才发生了以下步骤:
- 打开一堆 netCDF 文件,并在每个文件中找到一个温度变量。这很廉价。
- 对于每个温度变量,创建一个
da.Array对象,指定我们如何对该变量进行分块。这也很廉价。 - 通过连接每天所有的
da.Array对象,创建一个新的da.Array。这一步和其他步骤一样,只是簿记工作。我们还没有加载数据或进行任何计算。 - 编写 NumPy 风格的代码
x[::2].mean(axis=0) - x[2::2].mean(axis=0)。这创建了另一个具有更复杂任务图的da.Array。创建这个字典需要几百毫秒。 - 在我们的
da.Array对象上调用imshow imshow会对其输入调用np.array,这会启动多核任务调度器。- 大量数据块从所有的 netCDF 文件中涌出。这些数据块经过各种 NumPy 函数处理,并创建新的数据块。精心组织的“魔法”发生,一个
np.ndarray就出现了。 - Matplotlib 生成了一张漂亮的图。
遇到的问题
线程调度器在其规划中引入了显著的开销。对于这个工作流程,单线程朴素调度器实际上要快得多。我们将不得不寻找更好的解决方案来减少调度开销。
结论
我希望这展示了 dask.array 在处理磁盘上存储的数组集合时是如何有用的。一如既往,我非常乐意听取关于如何使这个项目对您的工作更有帮助的建议。如果您有大型 n 维数据集,我很想了解您是如何处理的,以及 dask.array 如何提供帮助。您可以在下面的评论区或通过 [email protected] 联系我。
致谢
首先,其他项目已经可以做到这一点。特别是如果这看起来对您的工作有用,那么您可能还应该了解由英国气象局开发的 Biggus,它比 dask.array 存在的时间长得多,并且已在生产中使用。
其次,这篇文章展示了以下人员的工作:
- Erik Welch (Continuum) 编写了优化 passes,用于在执行前清理 dask 图。
- Wesley Emeneker (Continuum) 编写了大量的切片代码。
- Stephan Hoyer (Climate Corp) 向我讲解了应用,并指引我找到了数据。如果您想看到 dask 与
xray集成,那么您应该去“烦扰”Stephan :)
博客评论由 Disqus 提供