迈向外存DataFrame
这项工作得到了 Continuum Analytics 和 XDATA 项目的支持,是 Blaze 项目的一部分
本文主要面向开发者。内容涉及仍在实验阶段的代码,尚未准备好供用户使用。
太长不看 (tl;dr) 我们能构建 dask.frame 吗?一种方法涉及索引和大量洗牌(重排)。
Dask 数组进展
在过去的两个月里,我们见证了 dask (一个任务调度规范)和 dask.array (一个旨在使用分块算法实现外存 nd 数组的项目)的创建。(博文:1, 2, 3, 4, 5, 6)。这进展得很顺利。dask.array 已在主要的 conda 通道和 PyPI 上可用,并且在大多数情况下,它是 NumPy 部分操作的愉快直接替代品。我对此非常满意。
conda install dask
or
pip install dask
虽然仍有工作要做,特别是我想与遇到实际问题的人交流,但总的来说,dask.array 感觉已经准备就绪。
接下来是 dask frames
我们能为 Pandas 做我们刚刚为 NumPy 做的事情吗?
问题:我们能否将大型 DataFrame 表示为一系列内存中的 DataFrame,并使用任务调度执行大多数 Pandas 操作?
回答:我不知道。我们来试试。
朴素方法
如果我们将 dask.array 表示为 NumPy ndarray 的 N 维网格,那么也许我们应该将 dask.frame 表示为 Pandas DataFrame 的一维网格;它们有点像数组。
dask.array |
朴素的 dask.frame |
|
 |
 |
这种方法支持以下操作
- 元素级操作
df.a + df.b - 按行过滤
df[df.a > 0] - 聚合操作
df.a.mean() - 一些与标准聚合操作结合的拆分-应用-合并(split-apply-combine)操作,例如
df.groupby('a').b.mean()。本质上,任何你可以用df.groupby(...).agg(...)完成的操作。
聚合操作和拆分-应用-合并操作需要一些巧妙的处理。这就是 Blaze 现在的工作方式,也是它在这些笔记本中进行外存操作的方式:Blaze 和 CSV 文件,Blaze 和二进制存储。
然而,这种方法不支持以下操作
- 连接 (Joins)
- 带有更复杂的
transform或apply合并步骤的拆分-应用-合并操作 - 滑动窗口或重采样操作
- 涉及多个数据集的任何操作
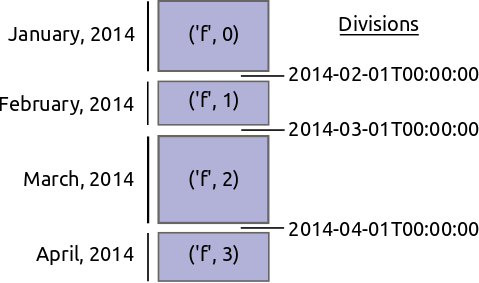
基于索引值进行分区
我们不基于块的大小进行分区,而是基于索引的值范围进行分区。
| 基于块大小进行分区 | 基于索引值进行分区 | |
|
 |
这开启了一些额外的操作可能性
- 当两个表共享相同的索引时,连接操作是可能的。因为我们拥有索引值的信息,所以我们知道一侧的哪些块需要与另一侧的哪些块进行通信。
- 当分组键是索引时,带有 transform/apply 步骤的拆分-应用-合并操作是可能的。在这种情况下,我们保证每个组都在同一个块中。这开启了通用的
df.groupby(...).apply(...)。 - 如果像
dask.array中的 ghosting operations 那样在块之间共享少量信息,那么对索引执行滚动或重采样操作就很简单。
我们注意到以下主题
如果逻辑与索引对齐,复杂操作就变得容易
因此,许多复杂操作的秘诀变成了
- 根据适当的列重新索引数据
- 执行简单的计算
对外存数据重新索引
明确地说,想象我们有一个大型交易时间序列,按时间索引并按天分区。每天的数据都在一个单独的 DataFrame 中。
Block 1
-------
credit name
time
2014-01-01 00:00:00 100 Bob
2014-01-01 01:00:00 200 Edith
2014-01-01 02:00:00 -300 Alice
2014-01-01 03:00:00 400 Bob
2014-01-01 04:00:00 -500 Dennis
...
Block 2
-------
credit name
time
2014-01-02 00:00:00 300 Andy
2014-01-02 01:00:00 200 Edith
...
我们想要重新索引这些数据并洗牌(重排)所有条目,以便现在我们按人的名字进行分区。也许所有名字为 A 的都在一个块中,而所有名字为 B 的都在另一个块中。
Block 1
-------
time credit
name
Alice 2014-04-30 00:00:00 400
Alice 2014-01-01 00:00:00 100
Andy 2014-11-12 00:00:00 -200
Andy 2014-01-18 00:00:00 400
Andy 2014-02-01 00:00:00 -800
...
Block 2
-------
time credit
name
Bob 2014-02-11 00:00:00 300
Bob 2014-01-05 00:00:00 100
...
重新索引和洗牌大型数据是困难且昂贵的。我们需要找到合适的值来对数据进行分区,以便获得大小均匀且能很好地放入内存中的块。我们还需要将所有原始块中的条目洗牌到所有新块中。原则上,每个旧块都对每个新块有所贡献。
我们不能直接调用 DataFrame.sort,因为整个数据可能无法放入内存,而且我们大多数的排序算法都假定可以随机访问。
我们分两步进行
- 找到好的分割值来对数据进行分区。这些值应将数据分割成大小大致相等的块。
- 根据第一步找到的新分区,将旧块洗牌(重排)到新块中。
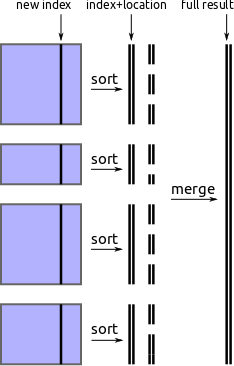
通过外部排序查找分割值
找到新分区值的一种方法是从每个块中提取新的索引列,执行外存排序,然后从该数组中选取间隔均匀的值。
-
从每个块中提取新的索引列
indexes = [block['new-column-index'] for block in blocks] -
对该列执行 外存排序
sorted_index = fancy_out_of_core_sort(indexes) -
选取间隔均匀的值,例如
partition_values = sorted_index[::1000000]
我们使用并行块内排序实现这一点,然后使用 heapq 模块进行流式合并。它有效,但速度较慢。
可能的改进
可以通过以下选项之一来加速此过程
- 一个直接作用于 NumPy 数组迭代器的流式数值解法(有人知道
numtoolz吗?) - 完全不进行排序。我们实际上只需要近似的、间隔均匀的分位数。简短的文献检索表明可能存在一些好的解决方案。
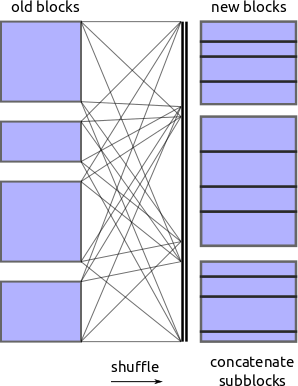
洗牌(重排)
既然我们知道了要基于哪些值进行分区,我们要求每个块将自身分成适当的碎片,并将所有这些碎片放入一个溢出到磁盘的字典中。然后,另一个进程会拾取这些碎片,并调用 pd.concat 将它们合并到新的块中。
对于外存字典,我们目前使用 Chest。事实证明,序列化 DataFrames 并将其写入磁盘可能很棘手。有几种不错的方法,它们之间的性能差异约为一个数量级。
这有效,但我的实现速度较慢
这是一个使用 NYCTaxi 数据片段的示例(这部分数据量很小)
In [1]: import dask.frame as dfr
In [2]: d = dfr.read_csv('/home/mrocklin/data/trip-small.csv', chunksize=10000)
In [3]: d.head(3) # This is fast
Out[3]:
medallion hack_license \
0 89D227B655E5C82AECF13C3F540D4CF4 BA96DE419E711691B9445D6A6307C170
1 0BD7C8F5BA12B88E0B67BED28BEA73D8 9FD8F69F0804BDB5549F40E9DA1BE472
2 0BD7C8F5BA12B88E0B67BED28BEA73D8 9FD8F69F0804BDB5549F40E9DA1BE472
vendor_id rate_code store_and_fwd_flag pickup_datetime \
0 CMT 1 N 2013-01-01 15:11:48
1 CMT 1 N 2013-01-06 00:18:35
2 CMT 1 N 2013-01-05 18:49:41
dropoff_datetime passenger_count trip_time_in_secs trip_distance \
0 2013-01-01 15:18:10 4 382 1.0
1 2013-01-06 00:22:54 1 259 1.5
2 2013-01-05 18:54:23 1 282 1.1
pickup_longitude pickup_latitude dropoff_longitude dropoff_latitude
0 -73.978165 40.757977 -73.989838 40.751171
1 -74.006683 40.731781 -73.994499 40.750660
2 -74.004707 40.737770 -74.009834 40.726002
In [4]: d2 = d.set_index(d.passenger_count, out_chunksize=10000) # This takes some time
In [5]: d2.head(3)
Out[5]:
medallion \
passenger_count
0 3F3AC054811F8B1F095580C50FF16090
1 4C52E48F9E05AA1A8E2F073BB932E9AA
1 FF00E5D4B15B6E896270DDB8E0697BF7
hack_license vendor_id rate_code \
passenger_count
0 E00BD74D8ADB81183F9F5295DC619515 VTS 5
1 307D1A2524E526EE08499973A4F832CF VTS 1
1 0E8CCD187F56B3696422278EBB620EFA VTS 1
store_and_fwd_flag pickup_datetime dropoff_datetime \
passenger_count
0 NaN 2013-01-13 03:25:00 2013-01-13 03:42:00
1 NaN 2013-01-13 16:12:00 2013-01-13 16:23:00
1 NaN 2013-01-13 15:05:00 2013-01-13 15:15:00
passenger_count trip_time_in_secs trip_distance \
passenger_count
0 0 1020 5.21
1 1 660 2.94
1 1 600 2.18
pickup_longitude pickup_latitude dropoff_longitude \
passenger_count
0 -73.986900 40.743736 -74.029747
1 -73.976753 40.790123 -73.984802
1 -73.982719 40.767147 -73.982170
dropoff_latitude
passenger_count
0 40.741348
1 40.758518
1 40.746170
In [6]: d2.blockdivs # our new partition values
Out[6]: (2, 3, 6)
In [7]: d.blockdivs # our original partition values
Out[7]: (10000, 20000, 30000, 40000, 50000, 60000, 70000, 80000, 90000)
一些问题
-
首先,我们必须在执行过程中不断评估 dask。每个
set_index操作(以及因此产生的许多 groupbys 和 joins)都会强制进行评估。我们不能再像在dask.array的情况下那样,无休止地组合高级操作以形成越来越复杂的图,然后只在最后进行评估。我们需要边执行边评估。 -
排序/洗牌(重排)速度慢。这有几个原因,包括 DataFrames 的序列化以及排序本身就很困难。
-
频繁地对大量数据进行重新索引的可行性如何?我们何时会达到“直接使用数据库”的阶段?
-
Pandas 尚未释放 GIL,所以这完全是单核操作。请参阅关于 PyData 和 GIL 的文章。
-
我当前的解决方案缺乏基本功能。我跳过了容易的部分,以便首先确保困难的部分是可行的。
求助
我表格方面的知识不如数组多。我对这个领域的文献和常用解决方案并不了解。如果这里的任何内容看起来可疑,那么请务必提出。我非常需要您的帮助。
此外,Pandas API 比 NumPy 的复杂得多。如果有经验的开发者愿意介入并以分块的方式实现一些相当直接的 Pandas 功能,我将不胜感激。
博客评论由 Disqus 提供