分布式调度
这项工作得到了 Continuum Analytics 和 XDATA Program 的支持,作为 Blaze Project 的一部分。
总结:我们使用各种调度器评估 dask 图,并引入了一个新的分布式内存调度器。
Dask.distributed 是新的,尚未经过实战检验。请自行承担风险,并相应地调整期望。
评估 dask 图
大多数 dask 用户使用 dask 集合,如 Array、Bag 和 DataFrame。这些集合是生成 dask 图的便捷方式。dask 图是任务的字典。任务是一个包含函数和参数的元组。
包含 dask 集合(如 dask.array)的图可以通过其 .dask 属性获得。
>>> import dask.array as da
>>> x = da.arange(15, chunks=(5,)) # 0..14 in three chunks of size five
>>> x.dask # dask array holds the graph to create the full array
{('x', 0): (np.arange, 0, 5),
('x', 1): (np.arange, 5, 10),
('x', 2): (np.arange, 10, 15)}
对 x 的进一步操作会创建更复杂的图。
>>> z = (x + 100).sum()
>>> z.dask
{('x', 0): (np.arange, 0, 5),
('x', 1): (np.arange, 5, 10),
('x', 2): (np.arange, 10, 15),
('y', 0): (add, ('x', 0), 100),
('y', 1): (add, ('x', 1), 100),
('y', 2): (add, ('x', 2), 100),
('z', 0): (np.sum, ('y', 0)),
('z', 1): (np.sum, ('y', 1)),
('z', 2): (np.sum, ('y', 2)),
('z',): (sum, [('z', 0), ('z', 1), ('z', 2)])}
手工制作的 dask 图
我们可以手工制作 dask 图,而无需使用 dask 集合。这需要创建一个由函数元组组成的字典。
>>> def add(a, b):
... return a + b
>>> # x = 1
>>> # y = 2
>>> # z = add(x, y)
>>> dsk = {'x': 1,
... 'y': 2,
... 'z': (add, 'x', 'y')}
我们使用 dask 调度器之一来评估这些图。
>>> from dask.threaded import get
>>> get(dsk, 'z') # Evaluate graph with multiple threads
3
>>> from dask.multiprocessing import get
>>> get(dsk, 'z') # Evaluate graph with multiple processes
3
我们将图的评估与其构建分离开来。
分布式调度
将图与评估分离使我们能够创建新的调度器。特别地,存在一个可以在多台机器上并行运行并使用 ZeroMQ 进行通信的调度器。
该系统有一个中心化的调度器、多个工作节点以及可能多个客户端。
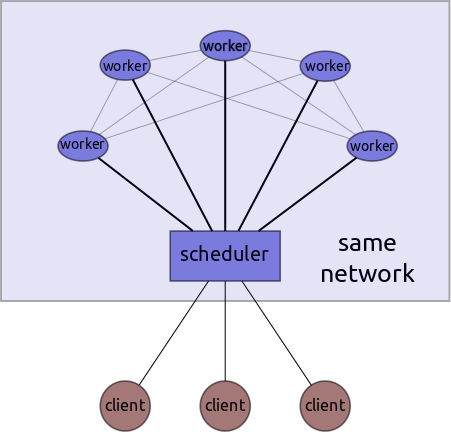
客户端将图发送到中心调度器,调度器将任务分发给工作节点并协调图的执行。调度器集中存储元数据,而工作节点本身以点对点方式处理中间数据的传输。一旦图执行完成,工作节点将数据发送给调度器,调度器再将其传递给相应的用户/客户端。
示例
这样一来,我们就可以在多台机器上并行执行 dask 图了。
$ ipython # On your laptop $ ipython # Remote Process #1: Scheduler
>>> def add(a, b): >>> from dask.distributed import Scheduler
... return a + b >>> s = Scheduler(port_to_workers=4444,
... port_to_clients=5555,
>>> dsk = {'x': 1, ... hostname='notebook')
... 'y': 2,
... 'z': (add, 'x', 'y')} $ ipython # Remote Process #2: Worker
>>> from dask.distributed import Worker
>>> from dask.threaded import get >>> w = Worker('tcp://notebook:4444')
>>> get(dsk, 'z') # use threads
3 $ ipython # Remote Process #3: Worker
>>> from dask.distributed import Worker
>>> w = Worker('tcp://notebook:4444')
>>> from dask.distributed import Client
>>> c = Client('tcp://notebook:5555')
>>> c.get(dsk, 'z') # use distributed network
3
选择您的调度器
这个图很小。我们不需要一个分布式机器网络来计算它(单个线程会快得多),但这个简单的示例可以很容易地扩展到更重要的用例,包括与 dask 集合(Array、Bag、DataFrame)的通用使用。您可以通过任何 compute 调用中的关键字参数来控制调度器。
>>> import dask.array as da
>>> x = da.random.normal(10, 0.1, size=(1000000000,), chunks=(1000000,))
>>> x.mean().compute(get=get) # use threads
>>> x.mean().compute(get=c.get) # use distributed network
或者,您可以使用 dask.set_options 设置 dask 中的默认调度器。
>>> import dask
>>> dask.set_options(get=c.get) # use distributed scheduler by default
已知限制
我们有意设计了我们能想到的最简单、最“笨”的分布式调度器。因为 dask 将图与调度器分开,我们可以多次迭代解决这个问题;在了解重要因素后构建更好的调度器。当前的调度器借鉴了我们的单内存系统,但它是第一个需要考虑分布式内存的 dask 调度器。因此,它具有以下已知限制:
- 它不考虑数据局部性。虽然线性任务链将在同一台机器上执行,但我们没有过多考虑在数据只有部分在本地的节点上执行多输入任务。
- 特别是,这个调度器没有针对 HDFS 等数据本地文件系统进行优化。它仍然乐于从 HDFS 读取数据,但这会导致不必要的网络通信。我们发现它与 S3 配合使用时效果很好。
- 这个调度器是新的,尚未经过充分测试。欢迎积极反馈的 Beta 用户。
- 我们还没有过多考虑部署问题。例如,您需要通过某种方式 SSH 连接到多台机器并启动工作节点,然后在完成后将其关闭。Dask.distributed 可以从 IPython Parallel 集群引导启动,并且我们已将其集成到 anaconda-cluster 中,但部署仍然是一个棘手的问题。
模块 dask.distributed 在最新版本中可用,但我建议使用开发中的 master 分支。七月初将会有另一个版本发布。
更多信息
Blake Griffith 一直在使用 dask.distributed 和 dask.bag 处理来自 http://githubarchive.org 的数据。他计划撰写一篇博文,以更好地演示如何在实际问题中使用 dask.distributed。请在未来一两周内留意该博文。
您可以在 dask 文档中阅读更多关于 dask.distributed 内部设计的详细信息。
致谢
特别感谢 Min Regan-Kelley、John Jacobsen、Ben Zaitlen 和 Hugo Shi 在构建分布式系统方面提供的建议。
还要感谢 Blake Griffith 作为最初的用户/开发者并优化了用户体验。
博客评论由 Disqus 提供支持