使用 Dask Dataframe 在 HDFS 上使用 Pandas
这项工作由 Continuum Analytics 和 XDATA Program 提供支持,作为 Blaze Project 的一部分
在这篇文章中,我们在 HDFS 集群上并行使用 Pandas 来读取 CSV 数据。我们使用 dask.dataframe 协调这些计算。这篇博文的截屏版本可在此处查看:此处,本系列前一篇博文可在此处查看:此处。
首先,我们连接到调度器,从 distributed 库导入 hdfs 模块,然后从 HDFS 读取我们的 CSV 数据。
>>> from distributed import Executor, hdfs, progress
>>> e = Executor('127.0.0.1:8786')
>>> e
<Executor: scheduler=127.0.0.1:8786 workers=64 threads=64>
>>> nyc2014 = hdfs.read_csv('/nyctaxi/2014/*.csv',
... parse_dates=['pickup_datetime', 'dropoff_datetime'],
... skipinitialspace=True)
>>> nyc2015 = hdfs.read_csv('/nyctaxi/2015/*.csv',
... parse_dates=['tpep_pickup_datetime', 'tpep_dropoff_datetime'])
>>> nyc2014, nyc2015 = e.persist([nyc2014, nyc2015])
>>> progress(nyc2014, nyc2015)
我们的数据来自纽约市出租车和豪华轿车委员会,该委员会发布了各年份的纽约市所有黄出租车乘车记录。这是一个很好的计算表格数据模型数据集,因为它既大到足以令人烦恼,又深到足以广泛吸引人。每年数据约占磁盘空间的 25GB,作为 Pandas DataFrame 在内存中约占 60GB。
HDFS 将我们的 CSV 文件分解成 128MB 的块,分散在集群的各个硬盘上。dask.distributed 工作节点读取本地的字节块,并在这些字节上调用 pandas.read_csv 函数,从而在我们的八个工作节点的内存中生成 391 个独立的 Pandas DataFrame 对象。返回的对象 nyc2014 和 nyc2015 是 dask.dataframe 对象,它们向用户提供 Pandas API 的子集,但将所有工作分派给它们通过网络控制的许多 Pandas dataframes。
使用分布式数据
如果我们等待数据完全加载到内存中,就可以以交互式速度执行 pandas 风格的分析。
>>> nyc2015.head()
| 供应商 ID | 上车日期时间 | 下车日期时间 | 乘客人数 | 行程距离 | 上车经度 | 上车纬度 | 费率代码 ID | 存储转发标记 | 下车经度 | 下车纬度 | 支付类型 | 车费金额 | 额外费用 | MTA 税 | 小费金额 | 过路费金额 | 附加费 | 总金额 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 2015-01-15 19:05:39 | 2015-01-15 19:23:42 | 1 | 1.59 | -73.993896 | 40.750111 | 1 | 记录数 | -73.974785 | 40.750618 | 1 | 12.0 | 1.0 | 0.5 | 3.25 | 0 | 0.3 | 17.05 |
| 1 | 1 | 2015-01-10 20:33:38 | 2015-01-10 20:53:28 | 1 | 3.30 | -74.001648 | 40.724243 | 1 | 记录数 | -73.994415 | 40.759109 | 1 | 14.5 | 0.5 | 0.5 | 2.00 | 0 | 0.3 | 17.80 |
| 2 | 1 | 2015-01-10 20:33:38 | 2015-01-10 20:43:41 | 1 | 1.80 | -73.963341 | 40.802788 | 1 | 记录数 | -73.951820 | 40.824413 | 2 | 9.5 | 0.5 | 0.5 | 0.00 | 0 | 0.3 | 10.80 |
| 3 | 1 | 2015-01-10 20:33:39 | 2015-01-10 20:35:31 | 1 | 0.50 | -74.009087 | 40.713818 | 1 | 记录数 | -74.004326 | 40.719986 | 2 | 3.5 | 0.5 | 0.5 | 0.00 | 0 | 0.3 | 4.80 |
| 4 | 1 | 2015-01-10 20:33:39 | 2015-01-10 20:52:58 | 1 | 3.00 | -73.971176 | 40.762428 | 1 | 记录数 | -74.004181 | 40.742653 | 2 | 15.0 | 0.5 | 0.5 | 0.00 | 0 | 0.3 | 16.30 |
>>> len(nyc2014)
165114373
>>> len(nyc2015)
146112989
有趣的是,去年纽约出租车行业似乎略有萎缩。2015 年的乘车次数比 2014 年要少。
当我们查询整个 dask.dataframe 的长度时,实际上是查询所有数百个 Pandas dataframes 的长度,然后将它们求和。这个联系所有工作节点的过程在大约 200-300 毫秒内完成,这通常足够快,在交互式会话中感觉很流畅。
dask.dataframe API 看上去就像 Pandas API 一样,只是当我们想要实际结果时,需要调用 .compute()。
>>> nyc2014.passenger_count.sum().compute()
279997507.0
>>> nyc2015.passenger_count.sum().compute()
245566747
Dask.dataframes 会构建一个获取结果的计划,而分布式调度器会在组成我们数据集的工作节点上的所有小 Pandas dataframes 上协调该计划。
Pandas 用于元数据
让我们花点时间体会一下我们不必为 CSV 处理所做的所有工作,因为 Pandas 奇迹般地为我们处理了它。
>>> nyc2015.dtypes
VendorID int64
tpep_pickup_datetime datetime64[ns]
tpep_dropoff_datetime datetime64[ns]
passenger_count int64
trip_distance float64
pickup_longitude float64
pickup_latitude float64
RateCodeID int64
store_and_fwd_flag object
dropoff_longitude float64
dropoff_latitude float64
payment_type int64
fare_amount float64
extra float64
mta_tax float64
tip_amount float64
tolls_amount float64
improvement_surcharge float64
total_amount\r float64
dtype: object
我们不必查找列或指定数据类型。我们不必根据需要使用 int 或 float 函数解析每个值。我们不必解析日期时间,而只需指定一个 parse_datetimes= 关键字。CSV 解析的速度与这种格式预期的一样快,网络总速度略低于 1 GB/秒。
Pandas 备受喜爱,因为它消除了分析师生活中的所有这些小障碍。如果我们尝试重新发明一个新的“大数据框架”,我们将不得不重新实现 Pandas 内部已经完成的所有工作。相反,dask.dataframe 只是协调并重用 Pandas 库中的代码。它的成功很大程度上归功于核心 Pandas 开发者的工作,特别是 Masaaki Horikoshi (@sinhrks),他们为使 API 与 Pandas 核心库精确对齐做出了巨大贡献。
分析小费和支付类型
为了展示 dask.dataframe 的能力,我们对数据提出了一个简单的问题:“纽约人如何给小费?”。2015 年的纽约出租车数据显示,每趟乘车的总费用被很好地分解为车费金额、小费金额以及各种税费。这尤其使我们能够衡量每位乘客决定支付的小费百分比。
>>> nyc2015[['fare_amount', 'tip_amount', 'payment_type']].head()
| 车费金额 | 小费金额 | 支付类型 | |
|---|---|---|---|
| 0 | 12.0 | 3.25 | 1 |
| 1 | 14.5 | 2.00 | 1 |
| 2 | 9.5 | 0.00 | 2 |
| 3 | 3.5 | 0.00 | 2 |
| 4 | 15.0 | 0.00 | 2 |
在前两行中,我们看到了支持美国常见的 15-20% 小费标准的证据。接下来的三行有趣地显示零小费。仅凭这前五行(一个非常小的样本)判断,我们在这里看到了与支付类型的强烈相关性。我们通过计算 payment_type 列在完整数据集和零小费过滤数据集中的出现次数来进一步分析这一点。
>>> %time nyc2015.payment_type.value_counts().compute()
CPU times: user 132 ms, sys: 0 ns, total: 132 ms
Wall time: 558 ms
1 91574644
2 53864648
3 503070
4 170599
5 28
Name: payment_type, dtype: int64
>>> %time nyc2015[nyc2015.tip_amount == 0].payment_type.value_counts().compute()
CPU times: user 212 ms, sys: 4 ms, total: 216 ms
Wall time: 1.69 s
2 53862557
1 3365668
3 502025
4 170234
5 26
Name: payment_type, dtype: int64
我们发现几乎所有零小费的乘车都对应于支付类型 2,并且几乎所有支付类型 2 的乘车都没有给小费。我在这里的非科学假设是支付类型 2 对应现金支付,我们观察到司机倾向于不记录现金小费。然而,我们需要更多关于我们数据的领域知识才能真正有权威地提出这一主张。
分析小费比例
让我们创建一个新列 tip_fraction,然后查看此列按周几分组和按小时分组的平均值。
首先,我们需要过滤掉不良行,包括那些奇怪支付类型的行和零车费的行(纽约竟然有数量惊人的免费出租车乘车)。其次,我们创建一个新列,等于 tip_amount / fare_amount 的比率。
>>> df = nyc2015[(nyc2015.fare_amount > 0) & (nyc2015.payment_type != 2)]
>>> df = df.assign(tip_fraction=(df.tip_amount / df.fare_amount))
接下来,我们选择按上车日期时间列进行分组,以查看平均小费比例如何按周几和按小时变化。Pandas 的 groupby 和日期时间处理使得这些操作变得微不足道。
>>> dayofweek = df.groupby(df.tpep_pickup_datetime.dt.dayofweek).tip_fraction.mean()
>>> hour = df.groupby(df.tpep_pickup_datetime.dt.hour).tip_fraction.mean()
>>> dayofweek, hour = e.persist([dayofweek, hour])
>>> progress(dayofweek, hour)
按周几分组在我看来没有显示出任何特别显著的现象。不过我想指出纽约出租车乘客似乎非常慷慨。23-25% 的小费相当不错。
>>> dayofweek.compute()
tpep_pickup_datetime
0 0.237510
1 0.236494
2 0.236073
3 0.246007
4 0.242081
5 0.232415
6 0.259974
Name: tip_fraction, dtype: float64
但按小时分组显示,深夜和凌晨的乘客更有可能慷慨地给小费。
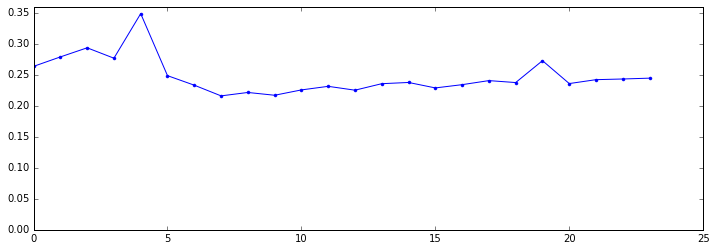
>>> hour.compute()
tpep_pickup_datetime
0 0.263602
1 0.278828
2 0.293536
3 0.276784
4 0.348649
5 0.248618
6 0.233257
7 0.216003
8 0.221508
9 0.217018
10 0.225618
11 0.231396
12 0.225186
13 0.235662
14 0.237636
15 0.228832
16 0.234086
17 0.240635
18 0.237488
19 0.272792
20 0.235866
21 0.242157
22 0.243244
23 0.244586
Name: tip_fraction, dtype: float64
In [24]:
我们用 matplotlib 绘制了这张图,可以看到工作时间有一个不错的低谷,而凌晨有一个高峰,在凌晨 4 点达到了惊人的 34%。
性能
让我们深入研究一些在不同时间尺度上运行的操作。这有助于很好地理解调度器的优点和局限性。
>>> %time nyc2015.head()
CPU times: user 4 ms, sys: 0 ns, total: 4 ms
Wall time: 20.9 ms
这个 head 计算速度大约和电影放映机一样快。你可以在电影的每一连续帧之间执行这个往返计算;对人眼来说,这看起来是流畅的。在上一篇博文中,我们讨论了可以将延迟降低到多低。在那篇文章中,我们是从我在加州的笔记本电脑运行计算,因此受到跨大陆 200 毫秒延迟的限制。这次,因为我们是从集群操作,所以可以将延迟降低到 20 毫秒。我们能这么快仅仅是因为我们只触及一个数据元素,即第一个分区。当我们触及整个数据集时,情况就不同了。
>>> %time len(nyc2015)
CPU times: user 48 ms, sys: 0 ns, total: 48 ms
Wall time: 271 ms
长度计算需要 200-300 毫秒。这个计算花费更长时间,因为我们触及数据的每一个独立分区,共有 178 个分区。调度器每个任务产生约 1 毫秒的开销,加上一些延迟,总共约为 200 毫秒。这意味着当计算速度非常快时,例如计算 len 的情况,调度器很可能是瓶颈。实际上,这是个好消息;这意味着通过改进调度器,我们可以进一步缩短这些时间。
如果您查看上面的 groupby 计算,您可以将进度条中的数字相加,看到我们在大约 7 秒内计算了大约 3000 个任务。看起来这个计算大约一半是调度器开销,一半受实际计算的限制。
结论
我们在集群上使用了 dask+distributed,从 HDFS 读取 CSV 数据到 dask dataframe 中。然后我们使用了 dask.dataframe(它看起来与 Pandas dataframe 相同),直观且高效地操作了我们的分布式数据集。
我们稍微研究了一些简单计算的性能特征。
哪些方面不足
像往常一样,我将有一个类似的部分,诚实地说明哪些方面做得不好,以及如果时间更充裕我会做什么。
-
Dask dataframe 实现了 Pandas 功能中常用的子集,而不是全部。向用户准确传达这个子集的界限出人意料地困难。值得注意的是,在分布式环境中,我们还没有洗牌(shuffle)算法,因此
groupby(...).apply(...)和一些连接操作尚不可能实现。 -
如果您想使用线程,您需要 Pandas 0.18.0,截至本文撰写时,该版本仍处于发布候选阶段。此 Pandas 版本修复了一些重要的 GIL 相关问题。
-
每个任务 1 毫秒的开销限制是显著的。虽然我们仍然可以扩展到比这里更大的集群,但在减少这个数字之前,我们可能无法显著加速非常快速的操作。
-
我们使用 hdfs3 库从 HDFS 读取数据。这个库似乎工作得很好,但它是新的,需要更多的活跃用户来发现和报告错误。
链接
- dask,原始项目
- dask.distributed,驱动集群计算的分布式内存调度器
- dask.dataframe,本文中使用的用户 API。
- 纽约出租车数据下载
- hdfs3:我们用于 HDFS 交互的 Python 库。
- 本系列博文的上一篇。
设置和数据
您可以在此处获取纽约市出租车和豪华轿车委员会的公共数据。我将数据下载到主节点,并使用如下命令将其导入 HDFS:
wget https://storage.googleapis.com/tlc-trip-data/2015/yellow_tripdata_2015-{01..12}.csv
hdfs dfs -mkdir /nyctaxi
hdfs dfs -mkdir /nyctaxi/2015
hdfs dfs -put yellow*.csv /nyctaxi/2015/
集群托管在 EC2 上,由九个 m3.2xlarge 实例组成,每个实例有 8 个核心和 30GB 内存。其中八个节点用作工作节点;它们使用进程进行并行计算,而不是线程。
博客评论由 Disqus 提供支持