Dask Distributed 版本 1.13.0
我很高兴宣布发布 Dask 的分布式调度器 dask.distributed,版本 1.13.0。
conda install dask distributed -c conda-forge
or
pip install dask distributed --upgrade
过去几个月,我们推出了一些重要的面向用户的功能
- Executor 已重命名为 Client
- 当 worker 内存不足时,可以将多余的数据溢出到磁盘
- 用于处理 dask 集合(如 dask.dataframe 或 dask.delayed)的 Client.compute 和 Client.persist 方法获得了使用
workers=关键字参数将计算的子组件限制在集群不同部分的能力。 - 可以在 worker 和调度器上部署 IPython 内核,用于交互式调试。
- Bokeh Web 界面新增了图表,并改进了原有图表的视觉样式。
此外,目前正在开发一些 beta 功能。这些功能现在可用,但在未来版本中可能会发生变化,恕不另行通知。我们非常欢迎乐于尝试前沿技术的用户进行实验并提供反馈。
- 客户端可以在调度器上发布命名数据集以便相互共享
- 任务可以启动其他任务
- worker 可以在用户提供的新软件环境中自行重启
此外,内部也发生了重大变化。除了性能提升之外,这些变化应该不会直接体现出来。
本文的其余部分将非常简要地解释上述主题。其中一些主题未来可能会成为单独的博客文章。在此之前,我建议大家查阅与 dask 的常规文档分开的 分布式调度器的文档,其中可能包含一些读者可能不知道的新信息(Google Analytics 报告显示,https://docs.dask.org.cn 的读者数量大约是 https://distributed.dask.org.cn 的 5-10 倍)。
主要变更和功能
将 Executor 重命名为 Client
https://distributed.dask.org.cn/en/latest/api.html
术语 Executor 最初的选择是为了与 concurrent.futures Executor 接口保持一致,该接口定义了作为主要接口使用的 .submit、.map、.result 方法和 Future 对象的行为。
不幸的是,这是 Spark 和 Mesos 等项目用来指代“在每个 worker 上执行任务的底层事物”的相同术语,这在与其他社区交流或用户过渡时造成了很大的困惑。
作为回应,我们将 Executor 重命名为一个稍微更通用的术语 Client,以指代其作为 用户用来控制计算的交互对象 的角色。
>>> from distributed import Executor # Old
>>> e = Executor() # Old
>>> from distributed import Client # New
>>> c = Client() # New
Executor 仍然是 Client 的别名,并在一段时间内保持有效,但对于方法内部使用 executor= 关键字的内部用法可能存在一些向后不兼容的变更。较新的示例和材料将全部使用术语 Client。
Worker 将多余数据溢出到磁盘
https://distributed.dask.org.cn/en/latest/worker.html#spill-excess-data-to-disk
当 worker 内存即将耗尽时,它们可以将多余数据发送到磁盘。此功能默认不开启,需要向 dask-worker 添加 --memory-limit=auto 选项来启用。
dask-worker scheduler:8786 # Old
dask-worker scheduler:8786 --memory-limit=auto # New
这最终将成为默认设置(使用 LocalCluster 时现在就是默认),但我们希望观察进展并逐步推广。
总的来说,此功能应该能提高健壮性,并允许在较小的集群上解决更大的问题,尽管会牺牲一些性能。Dask 通过巧妙调度来减少内存使用的策略仍然有效,因此在通常情况下您应该不需要此功能,但作为故障保护措施有它也很好。
启用对 compute 和 persist 方法的有效 worker 限制
https://distributed.dask.org.cn/en/latest/locality.html#user-control
分布式调度器的专家用户会了解将特定任务限制在特定计算机上运行的功能。这在处理 GPU 或仅在某些机器上可用的特殊数据库或仪器时非常有用。
之前此选项仅在 submit、map 和 scatter 方法上可用,迫使用户使用更直接的接口。现在 dask 集合接口函数 compute 和 persist 也支持此关键字。
IPython 集成
https://distributed.dask.org.cn/en/latest/ipython.html
您可以在 worker 或调度器上启动 IPython 内核,然后使用 IPython magic 命令或 QTConsole 直接访问它们。这在出现问题并希望直接在 worker 节点上进行交互式调试时非常有用。
在调度器上启动 IPython
>>> client.start_ipython_scheduler() # Start IPython kernel on the scheduler
>>> %scheduler scheduler.processing # Use IPython magics to inspect scheduler
{'127.0.0.1:3595': ['inc-1', 'inc-2'],
'127.0.0.1:53589': ['inc-2', 'add-5']}
在 Worker 上启动 IPython
>>> info = e.start_ipython_workers() # Start IPython kernels on all workers
>>> list(info)
['127.0.0.1:4595', '127.0.0.1:53589']
>>> %remote info['127.0.0.1:3595'] worker.active # Use IPython magics
{'inc-1', 'inc-2'}
Bokeh 界面
https://distributed.dask.org.cn/en/latest/web.html
集群的 Bokeh Web 界面持续发展,既改进了现有图表,又添加了新的图表和页面。
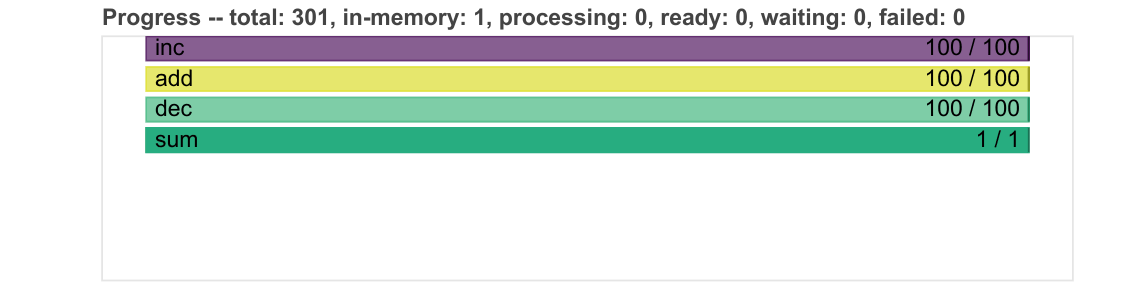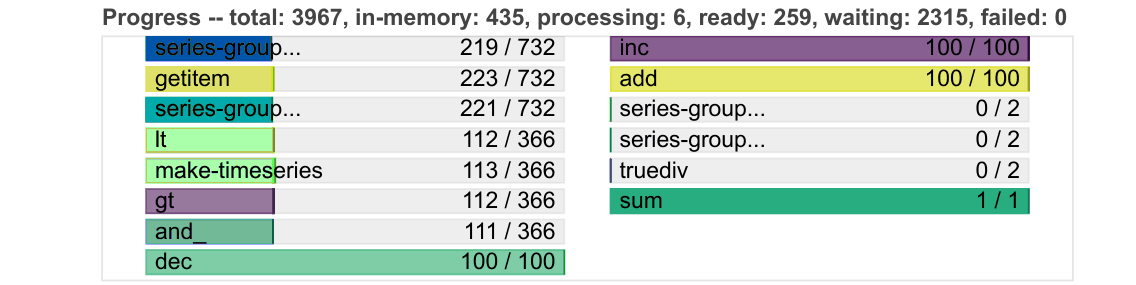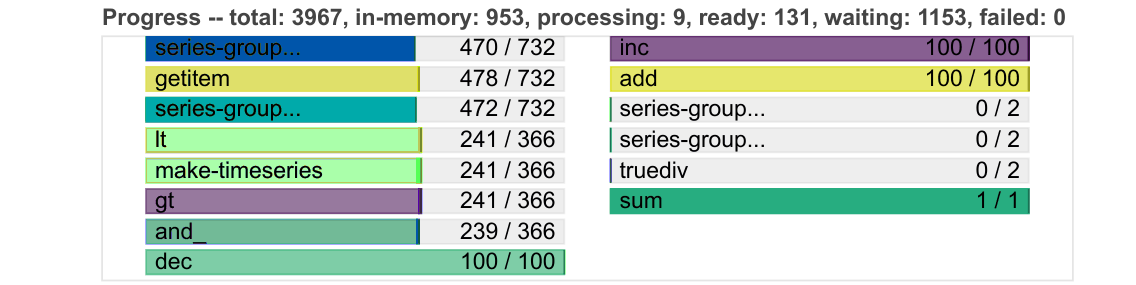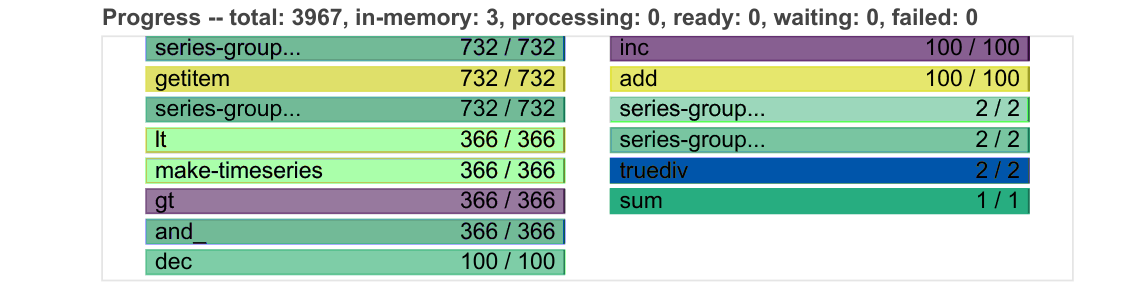
例如,进度条变得更加紧凑,并且可以根据新增的进度条动态缩小。
我们还添加了额外的表格和图表来监控 worker,例如它们的内存使用情况和当前积压的任务。
实验性功能
下面描述的功能是实验性的,可能会在不通知的情况下发生变化。请不要在稳定代码中依赖它们。
发布数据集
https://distributed.dask.org.cn/en/latest/publish.html
您现在可以在调度器上保存集合,这样您以后可以回到相同的计算结果,或者允许协作者查看和使用您的结果。这在以下情况下非常有用
- 有一个您经常以此为基础进行所有计算的数据集,并且您希望该数据集始终在内存中且易于访问,而无需每次开始工作时重新计算,即使您断开连接也是如此。
- 您想将结果发送给在同一 Dask 集群上工作的同事,并让他们立即访问您的计算结果,而无需发送脚本,也无需他们在集群上重复工作。
示例:客户端一
from dask.distributed import Client
client = Client('scheduler-address:8786')
import dask.dataframe as dd
df = dd.read_csv('s3://my-bucket/*.csv')
df2 = df[df.balance < 0]
df2 = client.persist(df2)
>>> df2.head()
name balance
0 Alice -100
1 Bob -200
2 Charlie -300
3 Dennis -400
4 Edith -500
client.publish_dataset(accounts=df2)
示例:客户端二
>>> from dask.distributed import Client
>>> client = Client('scheduler-address:8786')
>>> client.list_datasets()
['accounts']
>>> df = client.get_dataset('accounts')
>>> df.head()
name balance
0 Alice -100
1 Bob -200
2 Charlie -300
3 Dennis -400
4 Edith -500
从任务中启动任务
https://distributed.dask.org.cn/en/latest/task-launch.html
您现在可以向集群提交任务,这些任务本身又可以提交更多任务。这允许提交高度动态的工作负载,这些工作负载可以根据未来计算的值自行调整,而无需与原始客户端进行交互。
这是通过在任务内部启动新的本地 Client 实例来实现的,这些实例可以与调度器交互。
def func():
from distributed import local_client
with local_client() as c2:
future = c2.submit(...)
c = Client(...)
future = c.submit(func)
这有一些直接的使用场景,比如带有停止标准的迭代算法,但也包括许多新颖的用例,例如流处理和监控系统。
在可重新部署的 Python 环境中重启 Worker
您现在可以将完整的 Conda 环境打包并分发,并让 dask-worker 在该环境中“实时”重启。这包括以下步骤
- 在本地创建 Conda 环境(或任何包含
python可执行文件的可重新部署目录) - 打包该环境,并使用现有的 dask.distributed 网络将其复制到所有 worker
- 关闭所有 worker,并在新环境中重启它们
这有助于用户以更快的周转时间(通常为几十秒)试验不同的软件环境,而不是请求 IT 安装库或构建和部署 Docker 容器(后两者也是不错的解决方案)。请注意,上传单独的 python 脚本或 egg 文件的典型解决方案已经存在一段时间了,请参阅 upload_file 的 API 文档。
致谢
自 8 月 18 日发布的 1.12.0 版本以来,以下人员为 dask/distributed 仓库贡献了提交:
- Dave Hirschfeld
- dsidi
- Jim Crist
- Joseph Crail
- Loïc Estève
- Martin Durant
- Matthew Rocklin
- Min RK
- Scott Sievert
博客评论由 Disqus 提供支持