Dask 开发日志
这项工作得到了 Continuum Analytics、XDATA 项目以及 Moore 基金会 数据驱动发现倡议的支持。
为了提高透明度,我每周撰写博客,介绍 Dask 及相关项目前一周完成的工作。这篇日志涵盖了 2016-12-11 至 2016-12-18 期间完成的工作。这里的内容都未准备好投入生产。这篇博文写得匆忙,因此请勿期待精雕细琢。
上周的主题
- 清理负载均衡
- 找到工作进程延迟的原因
- 初步的 Spark/Dask Dataframe 比较
- 使用 asv 进行基准测试
负载均衡清理
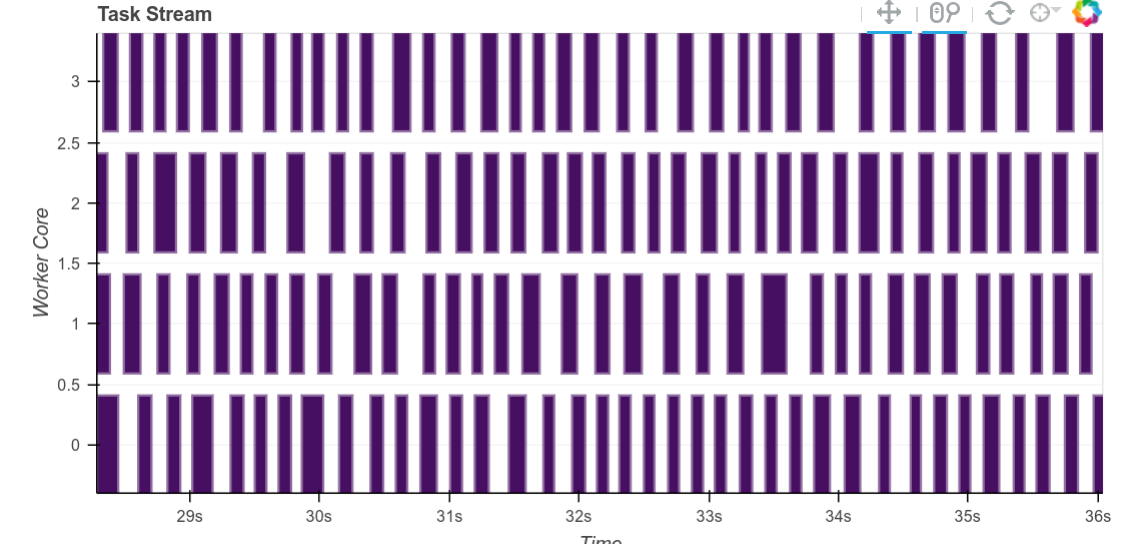
过去两周,调度器和工作进程经历了几次破坏性变更。这导致在处理混乱的工作负载时,整体性能相比最新版本有所下降,使得前沿用户无法使用最新的开发版本。这个问题现已解决,前沿的 git-master 版本已经恢复到旧的速度甚至更快。
作为视觉辅助,这就是糟糕(或在本例中是随机)的负载均衡的样子

识别并消除了工作进程延迟
一段时间以来,工作进程中连续任务之间存在显著的间隔,通常在 100 毫秒或更长,尤其在使用 Pandas 时。这非常奇怪,因为工作进程有很多积压的工作要处理(多亏了之前的良好负载均衡)。罪魁祸首是计算对象 dtype 数据帧中间结果的大小的过程。
更深入地解释这一点,回想一下,为了智能调度,工作进程会计算它们产生的每个中间结果的字节大小。对于 numpy 数组来说,这通常很快,例如我们可以直接将元素数量乘以 dtype 的 itemsize。然而,对于对象 dtype 数组或数据帧(通常用于文本),计算准确结果可能需要很长时间。现在我们不再计算准确结果,而是进行一个相当悲观的估计。任务之间的间隔显著缩小。
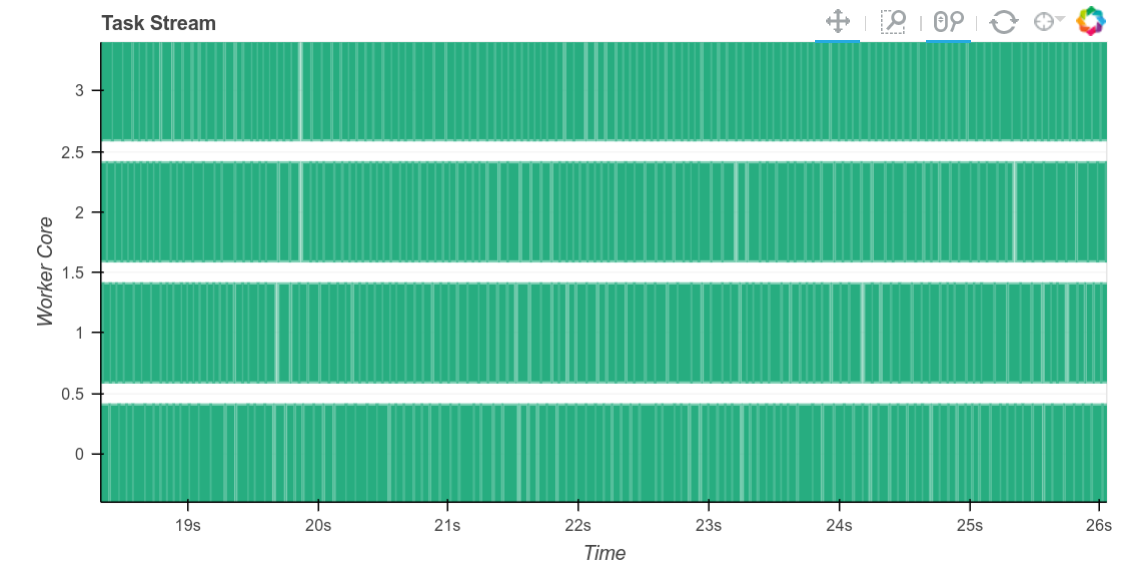
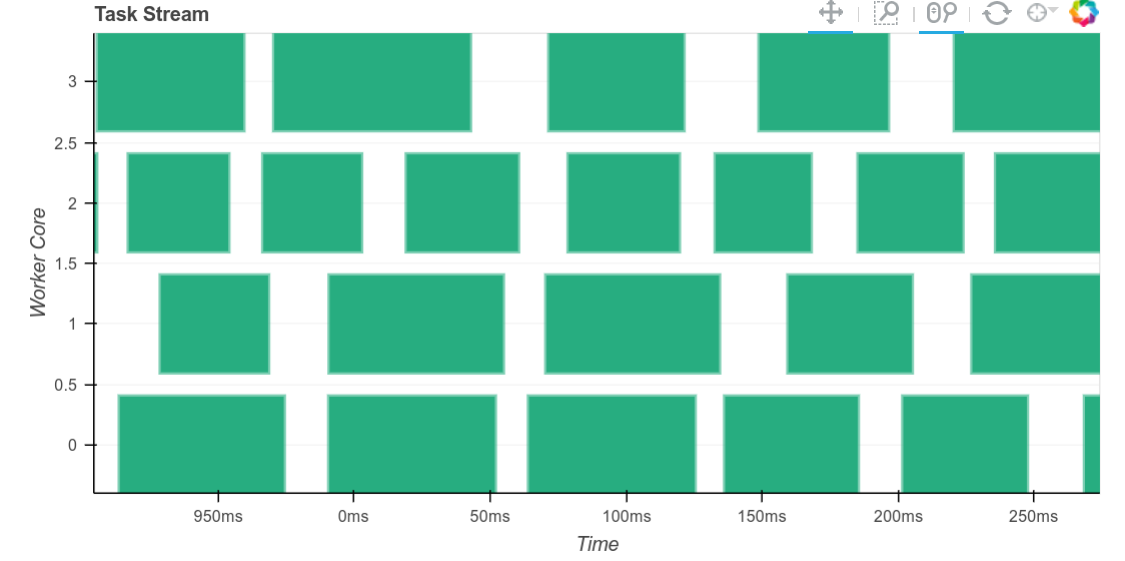
尽管在这些工作负载上,任务之间仍然存在约 10 毫秒的显著延迟(参见右侧放大版本)。在其他工作负载上,我们可以将任务间延迟降低到几十微秒级别。虽然 10 毫秒听起来不长,但当我们执行大量非常短的任务时,这很快就会成为瓶颈。
总之,这项改动将 shuffle 开销降低了一半。对于许多小任务的工作负载来说,性能开始变得相当出色。
初步的 Spark/Dask Dataframe 比较
我想运行一个小型基准测试,比较 Dask 和 Spark DataFrames。我过去几天花了一些时间在本地使用 Spark 处理 NYC Taxi 数据,并捣鼓集群部署工具,以便在 EC2 上搭建 Spark 集群进行基本基准测试。我偶然发现了 flintrock,这个工具之前被多人强烈推荐给我。
我一直在思考如何以公正的方式进行基准测试。比较性基准测试很有用,可以激励项目成长并相互学习。然而,在当今开源软件开发者拥有既得利益的环境下,基准测试往往侧重于项目的优势而隐藏其不足。即使怀有最好的意图和实践,开发者也很可能在测试过程中即时修正自己项目的不足。他们为自己的项目做这一点要比为其他项目容易得多。最终,基准测试看起来更像是销售文件,而不是值得信赖的研究。
我暂定的计划是联系几位 Spark 开发者,看看我们是否可以在运行计算和比较结果之前,就问题集和硬件进行合作。
使用 airspeed velocity 进行基准测试
Rich Postelnik 正在 Tom Augspurger 工作的基础上,在 dask-benchmarks 项目中使用 airspeed velocity 为 Dask 构建基准测试。如果有人感兴趣,构建基准测试是参与贡献的好方法。
预-预发布版本
我计划在下周某个时候发布 dask/dask 和 dask/distributed 的 0.X.0 版本升级的预发布版本。
博客评论由 Disqus 提供支持