Dask 版本 0.13.0
这项工作得到了 Continuum Analytics、XDATA 项目以及 Moore 基金会数据驱动发现计划的支持
摘要
Dask 刚刚升级到 0.13.0 版本。对于 arrays、dataframes 和分布式调度器来说,这是一个重要版本。这篇博文概述了自 11 月 4 日上次发布以来的一些主要变化。
- 支持 Python 3.6
- DataFrames 的算法和 API 改进
- 用于机器学习的 Dataframe 到 Array 转换
- 支持 Parquet
- 调度性能和 Worker 重写
- 使用嵌入式 Bokeh 服务器进行普适可视化诊断
- Windows 持续集成
- 自定义序列化
您可以使用 Conda 或 Pip 安装新版本
conda install -c conda-forge dask distributed
或
pip install dask[complete] distributed --upgrade
Python 3.6 支持
Dask 和所有必需的依赖项现已在 Conda Forge 上提供,支持 Python 3.6。
DataFrames 的算法和 API 改进
在过去几个月里,千核 Dask 部署变得更加普遍。这突显了 Dask.array 和 Dask.dataframe 中一些算法的扩展性问题,这些算法最初是为单工作站设计的。算法和 API 更改可以分为以下两类
- 完善 Pandas API
- 需要因扩展性问题而更改或添加的算法
Dask Dataframes 现在包含更完整的 Pandas API 集,包括以下内容
- 原地操作,例如
df['x'] = df.y + df.z - 完整的 Groupby-aggregate 语法,例如
df.groupby(...).aggregate({'x': 'sum', 'y': ['min', max']}) - Dataframes 和 series 上的重采样 (Resample)
- Pandas 的新 rolling 语法
df.x.rolling(10).mean() - 等等
此外,与一些大型 Dask 部署的合作也突显了一些算法中的扩展性问题,带来了以下改进
- groupbys、aggregations 等的树状归约
- 针对具有数百万个分组的 groupby-aggregations、drop_duplicates 等的多输出分区聚合
- nunique 的近似算法
- 等等
同样的合作还带来了对打开文件描述符的更好处理、对 Tornado 的上游更改,以及对 conda-forge CPython 配方本身的进一步上游更改,将 Windows 上的默认文件描述符限制从 512 增加。
Dataframe 到 Array 的转换
您现在可以将 Dask dataframes 转换为 Dask arrays。这主要是为了支持构建统计和机器学习应用程序的团队,在这种应用中这种转换很常见。例如,您可以加载数 TB 的 CSV 或 Parquet 数据,进行一些基本的过滤和操作,然后转换为 Dask array 进行更多数值计算工作,如 SVDs、回归等。
import dask.dataframe as dd
import dask.array as da
df = dd.read_csv('s3://...') # Read raw data
x = df.values # Convert to dask.array
u, s, v = da.linalg.svd(x) # Perform serious numerics
这应该对机器学习和统计开发者普遍有所帮助,因为许多更复杂的算法使用 Dask array 模型更容易实现,而分布式 dataframes 则不然。这项更改是专门为支持 Capital One 的 Chris White 发起的、正在发展的第三方项目 dask-glm 而进行的。
之前这很困难,因为 Dask.array 需要知道每个数据块的大小,而 Dask dataframes 无法提供(例如,在不实际查看 CSV 文件的情况下,不可能懒惰地知道其中有多少行)。现在 Dask.arrays 放宽了这一要求,它们也可以支持其他未知形状的操作,例如使用另一个 array 对 array 进行索引。
y = x[x > 0]
支持 Parquet
Dask.dataframe 现在支持 Parquet,这是一种用于表格数据的列式二进制存储格式,常用于分布式集群和 Hadoop 生态系统。
import dask.dataframe as dd
df = dd.read_parquet('myfile.parquet') # Read from Parquet
df.to_parquet('myfile.parquet', compression='snappy') # Write to Parquet
这是通过新的 fastparquet 库实现的,它是 Pure Python parquet-python 的一个 Numba 加速版本。Fastparquet 由 Martin Durant 构建和维护。看到 Parquet-cpp 项目通过 Arrow 以及 Wes McKinney 和 Uwe Korn 的工作获得 Python 支持也令人兴奋。Parquet 在 Python 中从难以访问到拥有多个竞争性的实现,这对“大数据”Python 生态系统来说是一个美妙而令人兴奋的变化。
调度性能和 Worker 重写
分布式调度器和 workers 的内部结构得到了显著修改。除了整体性能提升、更多即将推出的功能以及通过 Bokeh 服务器提供的更深入的可视化诊断外,用户不应该在这里体验到太大变化。
我们将一些调度逻辑从调度器推到了 workers 上。这使我们能够做到两件事
- 我们在 workers 上保留了更大的任务积压。这使得 workers 能够更有效地优化和充分利用其硬件。因此,复杂的计算最终会显著加快。
- 我们可以更容易地满足日益增长的对复杂调度功能的需求。例如,GPU 用户会很高兴地了解到,您现在可以指定抽象资源约束,比如“此任务需要一个 GPU”和“此 worker 有四个 GPU”,调度器和 workers 将相应地分配任务。这只是调度器/worker 重新设计后易于实现并现已可用的一个功能示例。
使用嵌入式 Bokeh 服务器进行普适可视化诊断
在优化调度器性能的同时,我们使用 Bokeh 构建了一些新的可视化诊断工具。现在有一个 Bokeh Server 运行在调度器 内部 以及每个 worker 内部。
当前的 Dask.distributed 用户应该熟悉现有的诊断仪表盘
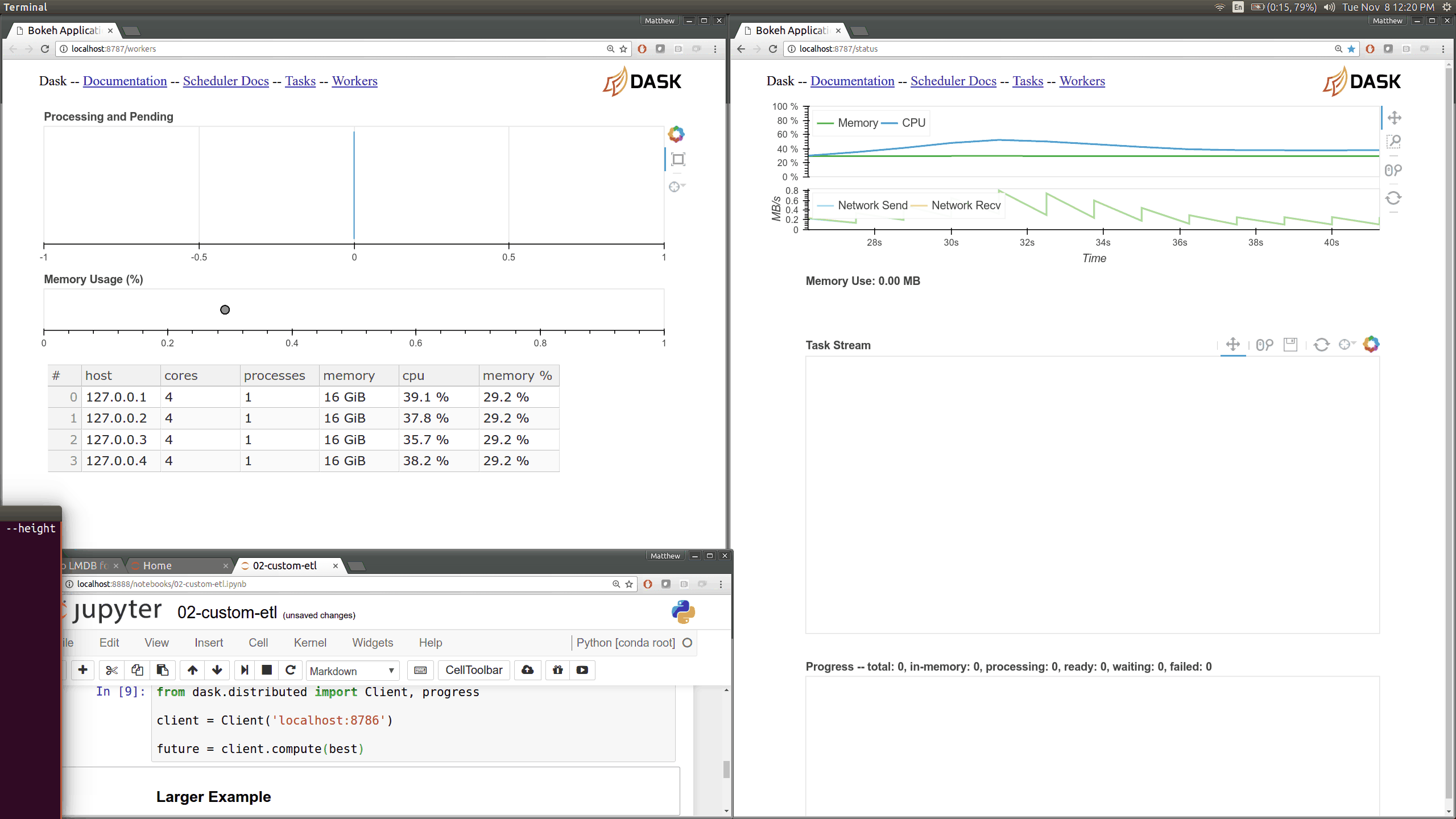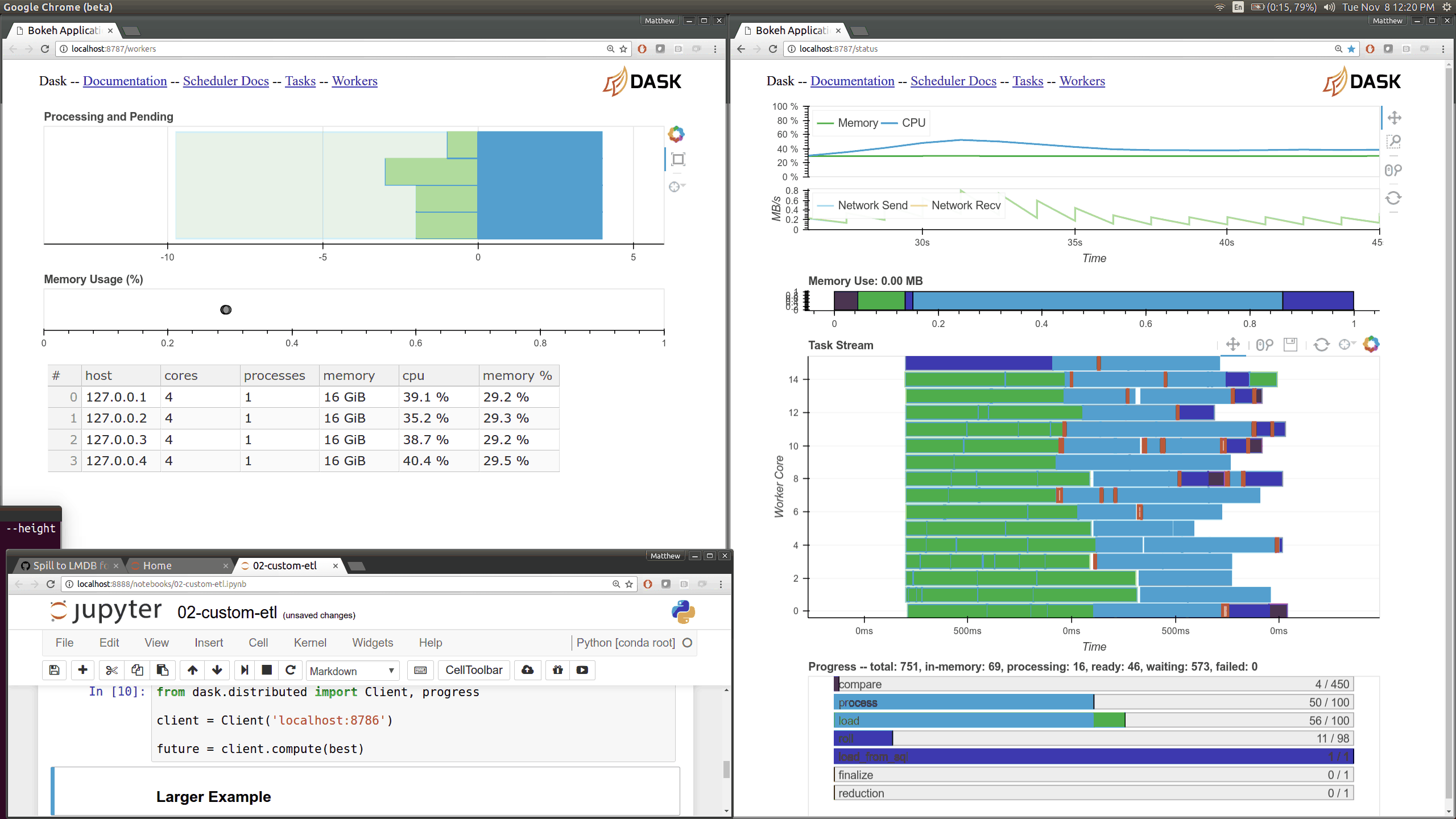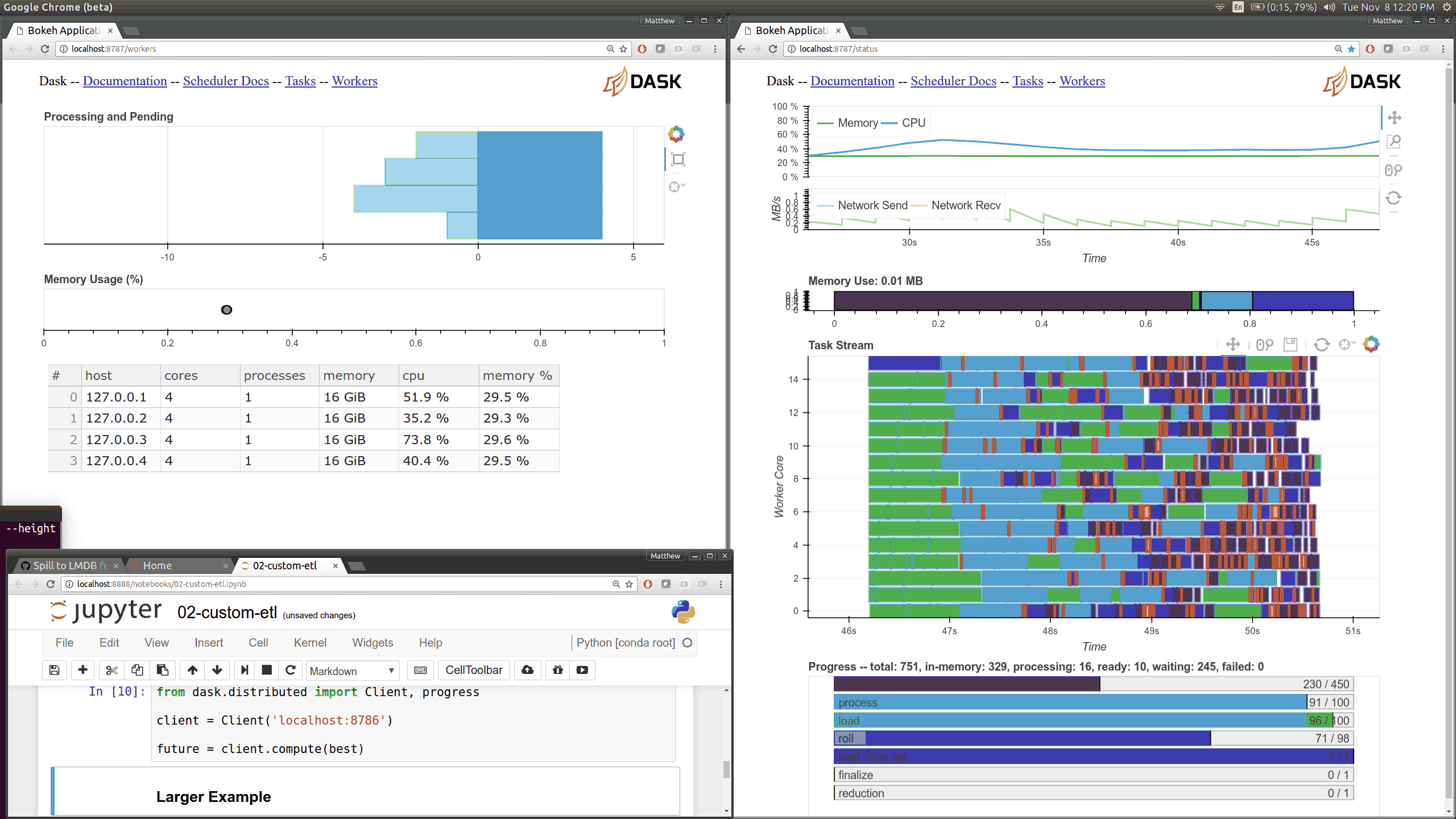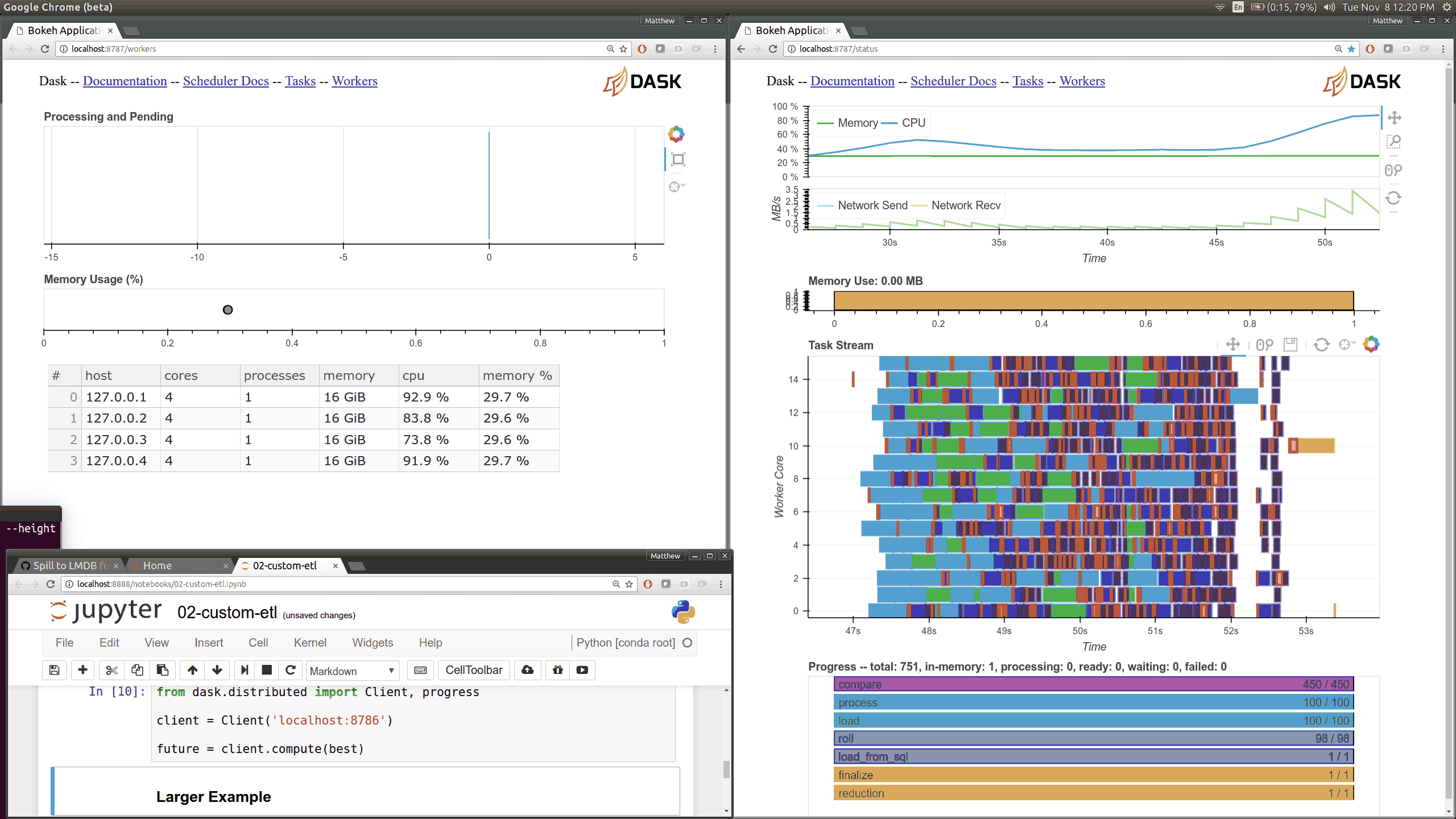
这些图表直观地展示了集群的状态以及当前正在进行的计算。这些仪表盘普遍受到好评。
现在有了更多这样的仪表盘,尽管它们更侧重于内部状态和时序,这对于开发者和高级用户来说更感兴趣,而不是典型用户。这里有几个新页面(共有七个),它们展示了 worker 和调度器内部各个部分的各种时序和计数器。
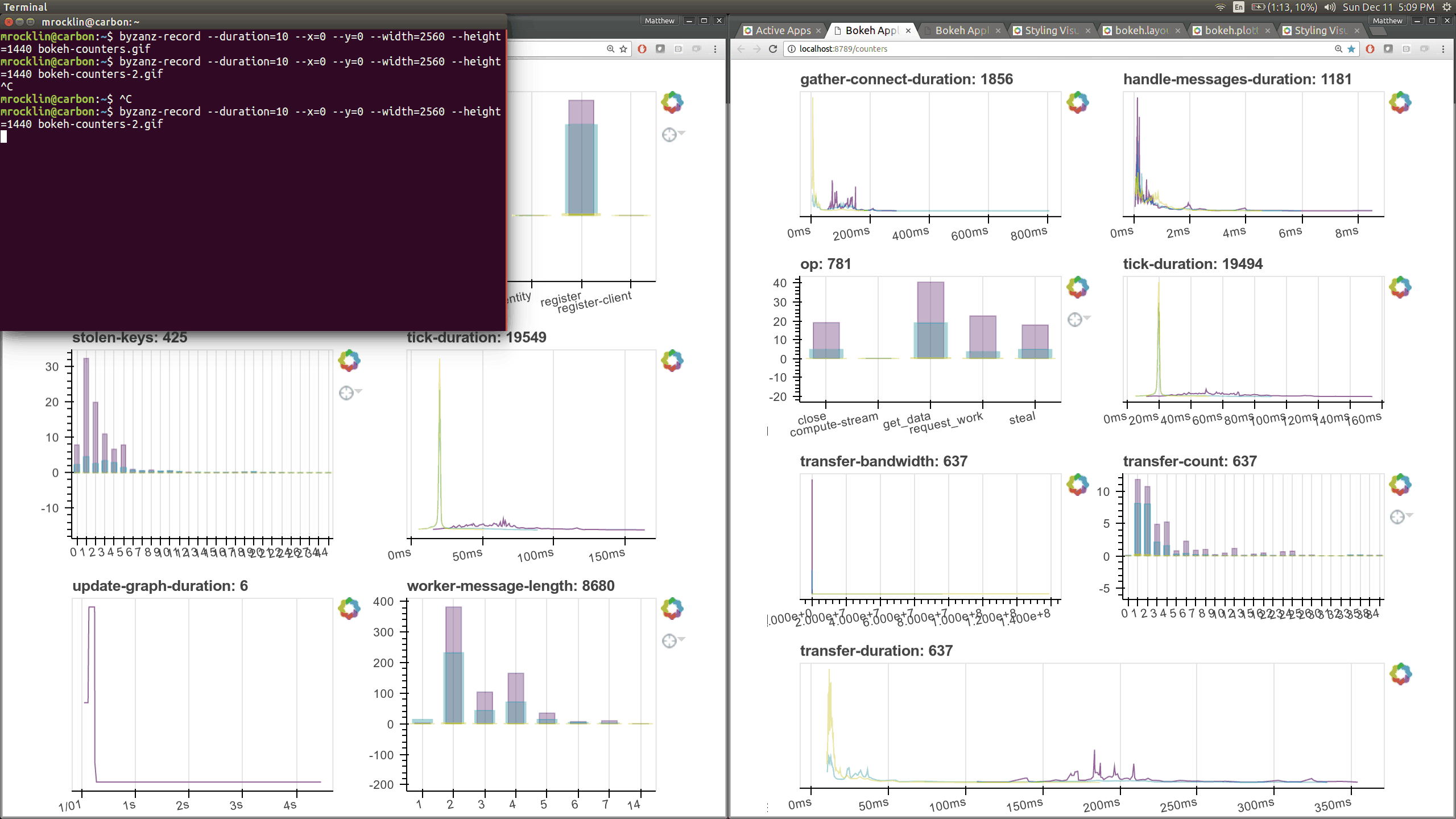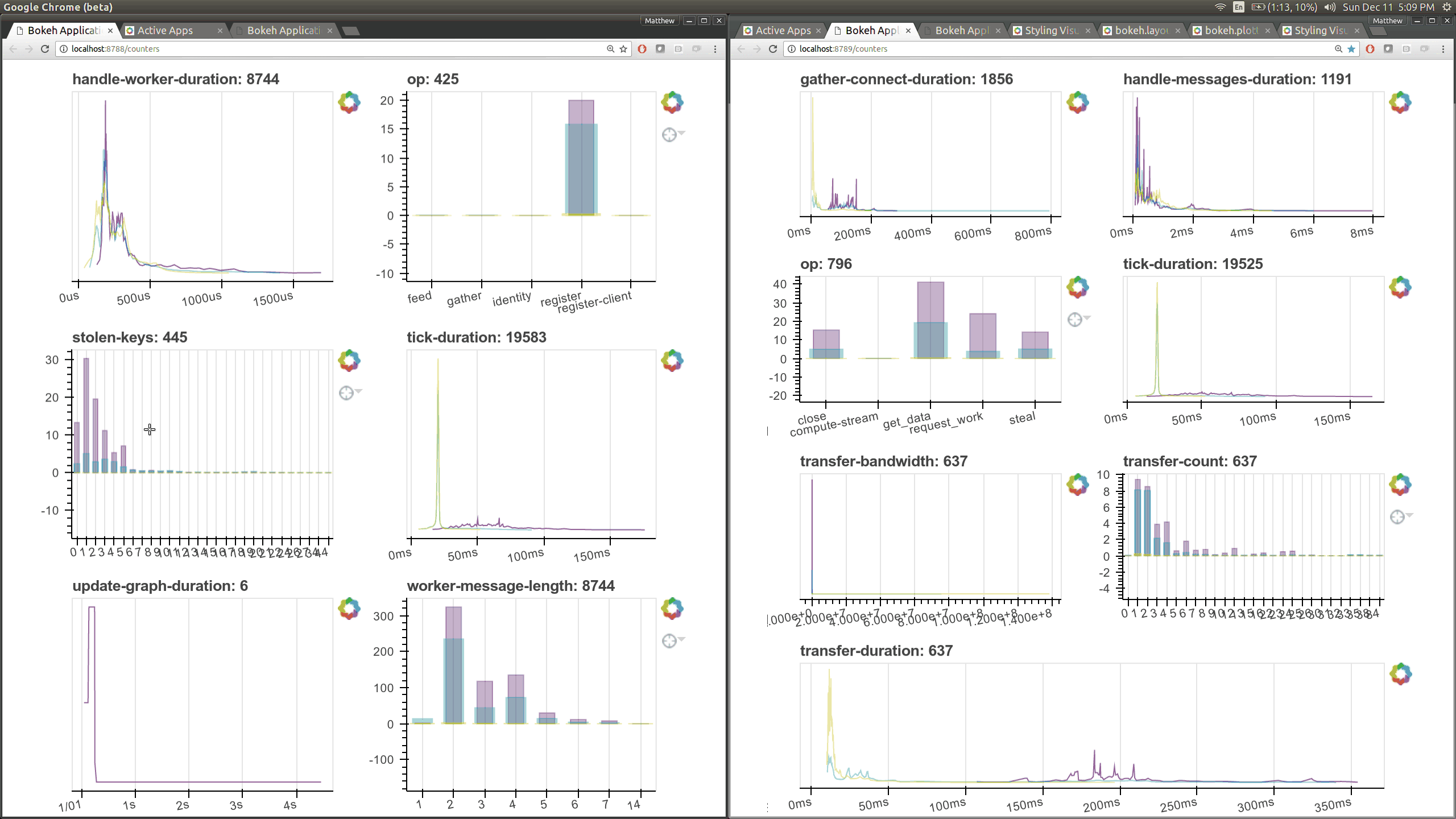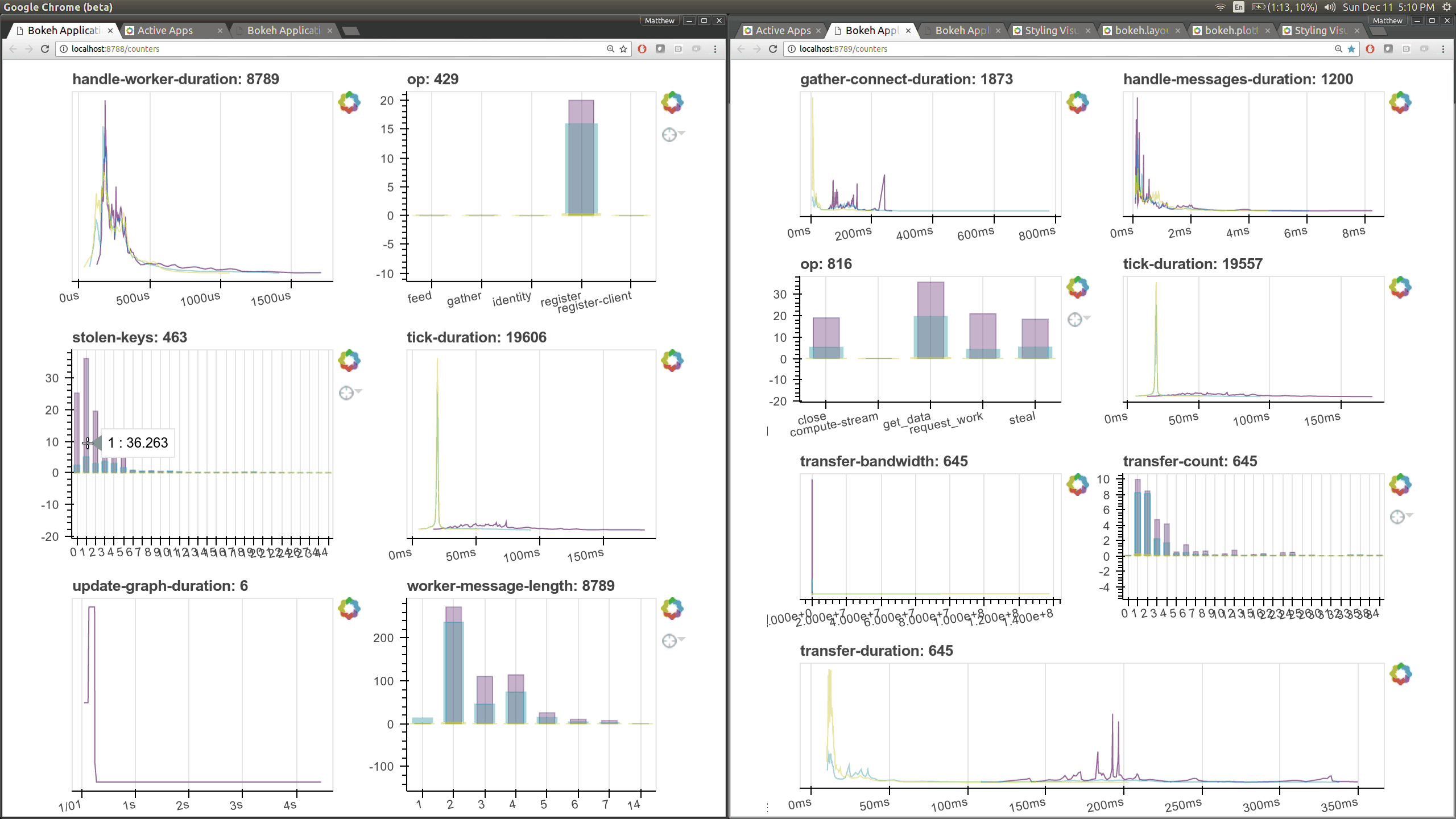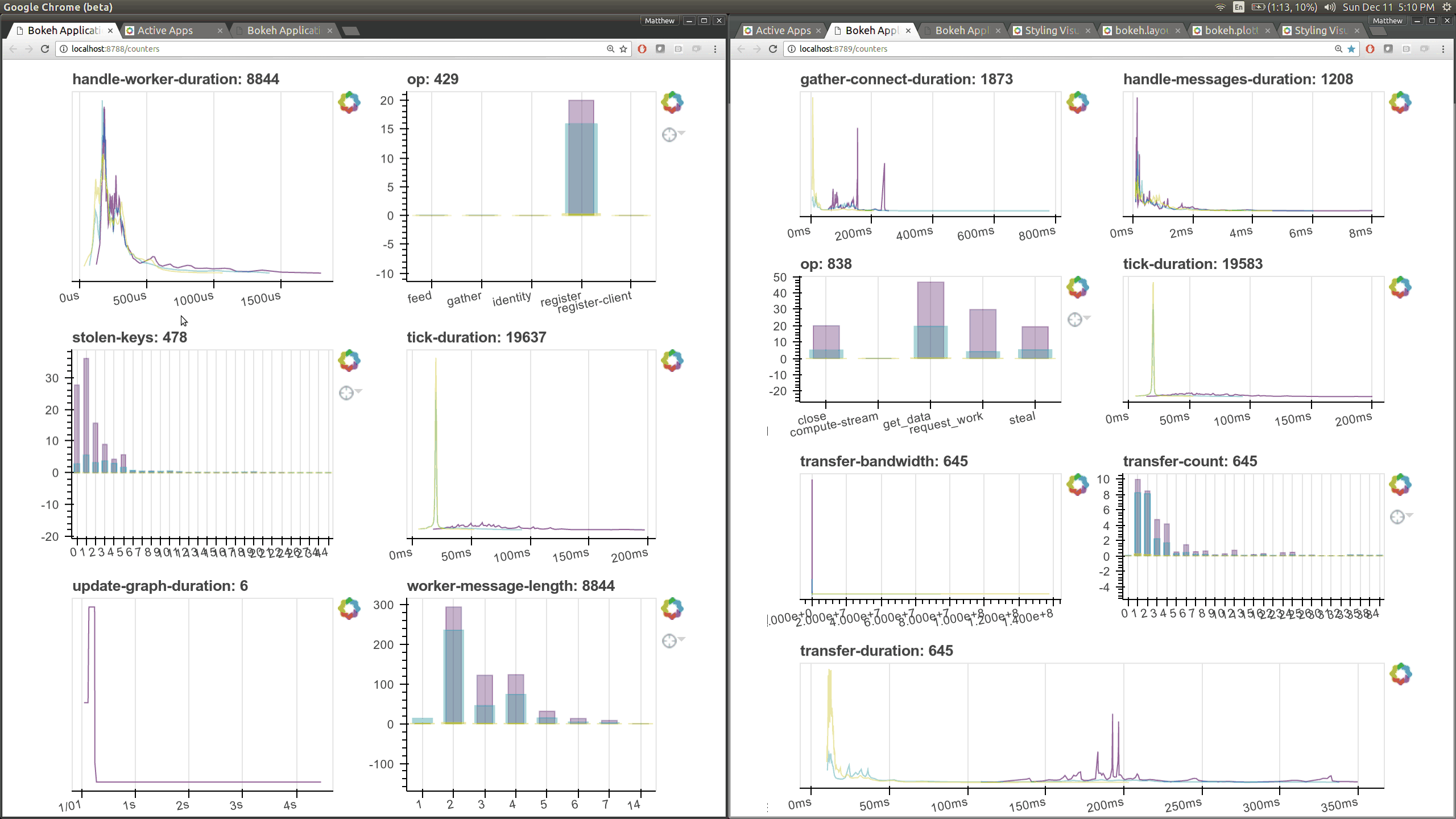
之前的 Bokeh 仪表盘是从一个单独的进程提供的,该进程定期(每 100 毫秒)查询调度器。现在,每个 worker 内部都有新的 Bokeh 服务器,并且调度器进程 内部 也有新的 Bokeh 服务器,而不是一个单独的进程。由于这些服务器是嵌入式的,它们可以直接访问调度器和 workers 的状态,这显著降低了我们构建新可视化工具的障碍。然而,这也会给调度器增加一些负载,调度器通常是计算密集型的。默认情况下,这些页面可在新端口访问,调度器端口为 8788,worker 端口为 8789。
自定义序列化
这实际上是上一个版本中发生的更改,但我还没有写过它,而且它很重要,所以我在这里包含了它。
以前 worker 之间的数据通信是使用 Pickle/Cloudpickle 以及可选的通用压缩(如 LZ4/Snappy)完成的。这很健壮,并且大部分时间工作正常,但遗漏了一些特殊数据类型,并且没有提供最佳性能。
现在我们可以对不同类型进行特殊考虑的序列化。这允许像 NumPy arrays 这样的特殊类型无需不必要的内存拷贝即可通过,也允许我们使用更特殊的数据类型特定的压缩技术,例如 Blosc。
它还允许 Dask 序列化一些以前无法序列化的类型。特别是,此更改旨在解决 Dask.array 气候科学社区对 HDF5 和 NetCDF 文件的担忧,这些文件(正确地)不可 pickle 化,因此仅限于单机使用。
这也是朝着两个经常被请求的功能迈出的第一步(这两个功能目前都还没有)
- 更好地支持 GPU-GPU 特定的序列化选项。我们现在离摆脱将 TCP Sockets 作为通用通信机制的假设迈进了一大步。
- 在不同运行时语言的 workers 之间传递数据。通过采用 Pickle 以外的其他协议,我们开始允许在不同软件环境的 workers 之间进行数据通信。
接下来是什么
那么,未来 Dask 有什么值得期待的呢?
- 通信:现在 workers 更加充分饱和,我们发现通信问题越来越频繁地成为瓶颈。这可能是因为其他一切都接近最优状态,也可能是因为 workers 现在空闲时间减少,导致竞争加剧。我们许多新的诊断工具旨在测量通信管道的各个组件。
- 第三方工具:我们看到像用于在 DRMAA 作业调度器(SGE、SLURM、LSF)上启动集群的 dask-drmaa 以及用于 GLM 类机器学习算法求解器的 dask-glm 等工具正在良好发展。我希望随着 Dask 渗透到新领域,像这些外部项目能成为 Dask 未来开发的主要重点。
- 博客:我将在接下来的几周内发布几篇有趣的博文。敬请期待。
了解更多
您可以使用 Conda 或 Pip 进行安装或升级
conda install -c conda-forge dask distributed
或
pip install dask[complete] distributed --upgrade
您可以在以下网站了解更多关于 Dask 及其分布式调度器的信息
致谢
自上次主要发布以来,以下开发者为核心 Dask 仓库(并行算法、arrays、dataframes 等)做出了贡献
- Alexander C. Booth
- Antoine Pitrou
- Christopher Prohm
- Frederic Laliberte
- Jim Crist
- Martin Durant
- Matthew Rocklin
- Mike Graham
- Rolando (Max) Espinoza
- Sinhrks
- Stuart Archibald
以下开发者为 Dask/distributed 仓库(分布式调度、网络通信等)做出了贡献
- Antoine Pitrou
- jakirkham
- Jeff Reback
- Jim Crist
- Martin Durant
- Matthew Rocklin
- rbubley
- Stephan Hoyer
- strets123
- Travis E. Oliphant
由 Disqus 提供的博客评论