在集群上使用 Dask 的自定义并行算法
这项工作由 Continuum Analytics、XDATA 项目以及来自 Moore Foundation 的数据驱动发现计划支持。
摘要
本文将 Dask 描述为一种计算任务调度器,它介于 Hadoop/Spark 等大数据计算框架和 Airflow/Celery/Luigi 等任务调度器之间。我们看到,通过结合这两类系统的优点,Dask 能够特别好地处理复杂的数据科学问题。
本文与最近关于结构化并行集合的两篇文章形成对比
大数据集合
大多数分布式计算系统,如 Hadoop、Spark 或 SQL 数据库,都实现了一小组强大而简单的并行操作,如 map、reduce、groupby 和 join。只要你使用这些操作来编写程序,平台就能理解你的程序并很好地为你服务。大多数时候这很棒,因为大多数大数据问题都相当简单。
然而,当我们探索新的复杂算法或更棘手的数据科学问题时,这些大型并行操作开始变得不够灵活。例如,考虑以下数据加载和清洗问题
- 从 100 个不同文件加载数据(这是一个简单的
map操作) - 同时从 SQL 数据库加载一个参考数据集(这完全不是并行操作,但可以与上面的 map 同时运行)
- 根据参考数据集对这 100 个数据集中的每一个进行归一化处理(有点像 map,但多了一个输入)
- 考虑每三个归一化数据集的滑动窗口(或许可以通过一个非常巧妙的 join 来实现?不确定。)
- 在上一阶段的所有 98 个输出中,考虑所有对。(Join 或笛卡尔积)然而,由于我们不想计算所有大约 10000 种可能性,我们只评估这些对中的一个随机样本
- 找到所有这些可能性中最好的(reduction)
在顺序的 for 循环代码中,这可能看起来像这样
filenames = ['mydata-%d.dat' % i for i in range(100)]
data = [load(fn) for fn in filenames]
reference = load_from_sql('sql://mytable')
processed = [process(d, reference) for d in data]
rolled = []
for i in range(len(processed) - 2):
a = processed[i]
b = processed[i + 1]
c = processed[i + 2]
r = roll(a, b, c)
rolled.append(r)
compared = []
for i in range(200):
a = random.choice(rolled)
b = random.choice(rolled)
c = compare(a, b)
compared.append(c)
best = reduction(compared)
这段代码显然可以并行化,但尚不清楚如何将其写成 MapReduce 程序、Spark 计算或 SQL 查询。当要求表达复杂或棘手的问题时,这些工具通常会失效。我们仍然可以使用 Hadoop/Spark 来解决这个问题,但常常不得不稍微改变和简化我们的目标。(这个问题并非特别复杂,我怀疑有巧妙的方法可以做到,但这并不简单且往往效率低下。)
任务调度器
所以人们改用 Celery、Luigi 或 Airflow 等任务调度器。这些系统跟踪数百个任务,每个任务都只是一个运行在普通 Python 数据上的普通 Python 函数。任务调度器跟踪任务之间的依赖关系,因此如果它们不相互依赖,就可以同时运行尽可能多的任务。
与 MapReduce 和 Spark 的大数据块集合方法相比,这是一种更细粒度的方法。然而,Celery、Luigi 和 Airflow 等系统通常效率也较低。这既是因为它们对计算了解较少(map 比任意图更容易调度),也是因为它们缺乏工作节点间通信、自定义数据类型的有效序列化等机制。
Dask 融合了任务调度与高效计算
Dask 既是像 Hadoop/Spark 一样了解容错性、工作节点间通信、实时状态等方面的大数据系统,也是像 Celery、Luigi 或 Airflow 一样能够执行任意任务的通用任务调度器。
许多 Dask 用户使用 Dask dataframe 等工具,它们会自动生成这些图,因此从未真正注意到 Dask 的任务调度器方面。然而,这正是 Dask 与 Hadoop 和 Spark 等其他系统的核心区别所在。Dask 在能运行的算法种类方面极其灵活。这是因为,其核心在于,它可以运行任意任务图,而不仅仅是 map、reduce、groupby、join 等。用户可以直接进行此操作,无需继承任何类或扩展 Dask 来获得额外的能力。
这带来了显著的性能优势。例如
- Dask.dataframe 可以轻松表示用于快速时间序列算法的最近邻计算
- Dask.array 可以实现来自最新研究的复杂线性代数求解器或 SVD 算法
- 复杂的机器学习算法通常更容易在 Dask 中实现,通过更智能的算法以及可伸缩的计算,使其效率更高。
- 定制化数据存储解决方案的复杂层次结构可以显式建模并加载到其他 Dask 系统中
但这并非没有代价。Dask 的调度器必须非常智能,才能平滑地调度任意图,同时优化数据本地性、工作节点故障、最小化通信、负载均衡、GPU 等稀缺资源等等。这是一项艰巨的任务。
Dask.delayed
那么,让我们继续使用 Dask 来运行描述的数据摄取作业。
我们创建一些模拟实际工作的虚函数
import random
from time import sleep
def load(address):
sleep(random.random() / 2)
def load_from_sql(address):
sleep(random.random() / 2 + 0.5)
def process(data, reference):
sleep(random.random() / 2)
def roll(a, b, c):
sleep(random.random() / 5)
def compare(a, b):
sleep(random.random() / 10)
def reduction(seq):
sleep(random.random() / 1)
我们使用 dask.delayed 来标注这些函数,这会改变函数,使其不是立即运行,而是捕获其输入并将所有内容放入任务图中以供将来执行。
from dask import delayed
load = delayed(load)
load_from_sql = delayed(load_from_sql)
process = delayed(process)
roll = delayed(roll)
compare = delayed(compare)
reduction = delayed(reduction)
现在我们只需调用之前正常的 Python for 循环代码。然而,现在我们的函数不是立即运行,而是捕获一个可以在其他地方运行的计算图。
filenames = ['mydata-%d.dat' % i for i in range(100)]
data = [load(fn) for fn in filenames]
reference = load_from_sql('sql://mytable')
processed = [process(d, reference) for d in data]
rolled = []
for i in range(len(processed) - 2):
a = processed[i]
b = processed[i + 1]
c = processed[i + 2]
r = roll(a, b, c)
rolled.append(r)
compared = []
for i in range(200):
a = random.choice(rolled)
b = random.choice(rolled)
c = compare(a, b)
compared.append(c)
best = reduction(compared)
下图是输入较小(只有 10 个文件和 20 个随机对)时的图示
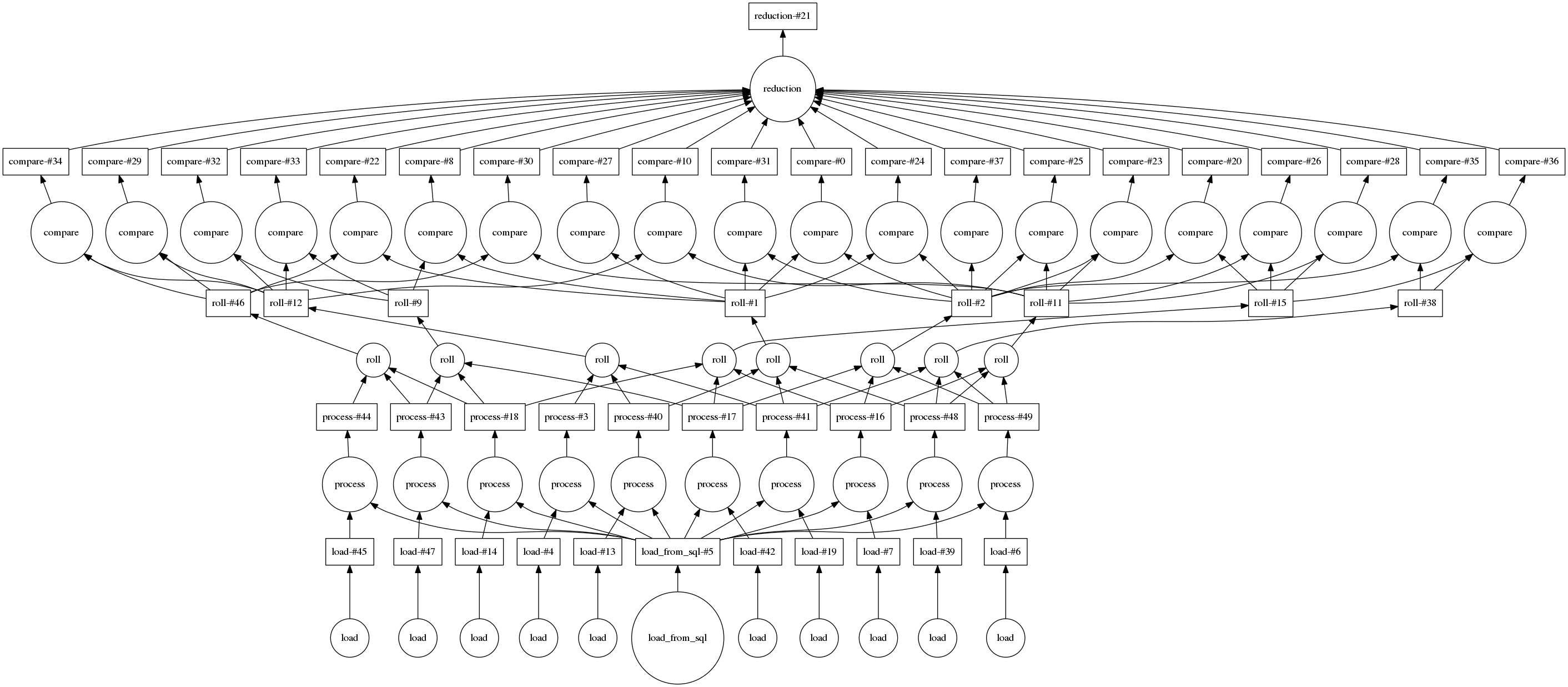
我们可以连接到具有 20 个核心的小型集群
from dask.distributed import Client
client = Client('scheduler-address:8786')
我们计算结果并实时查看计算的轨迹。
result = best.compute()
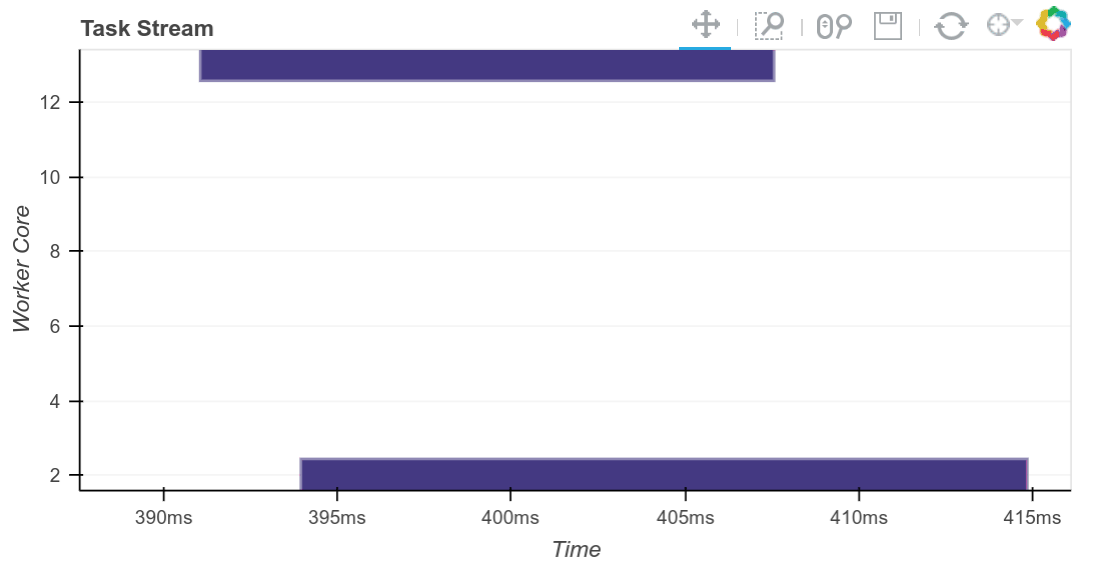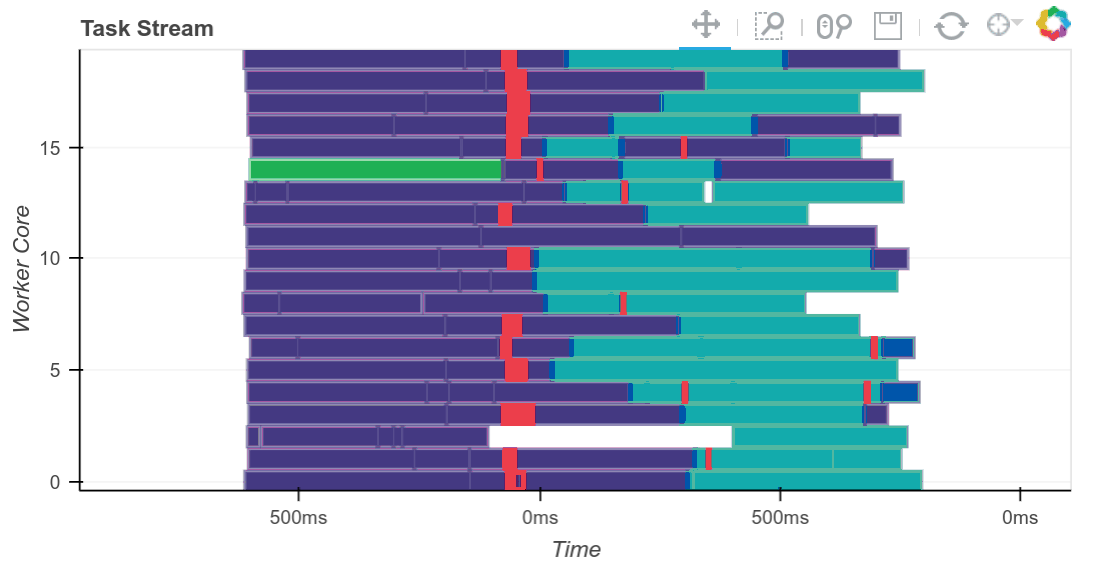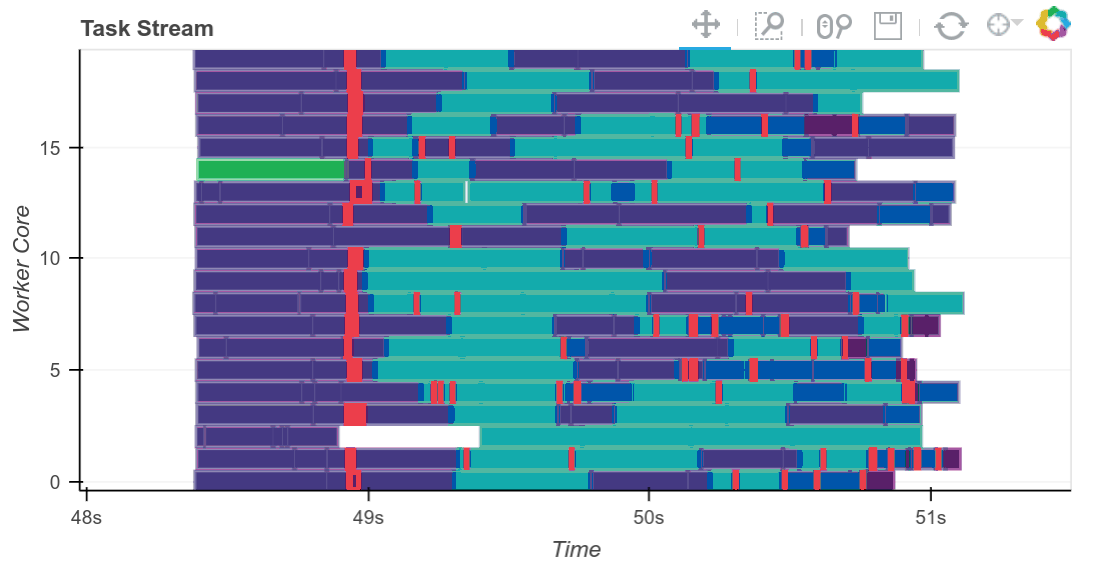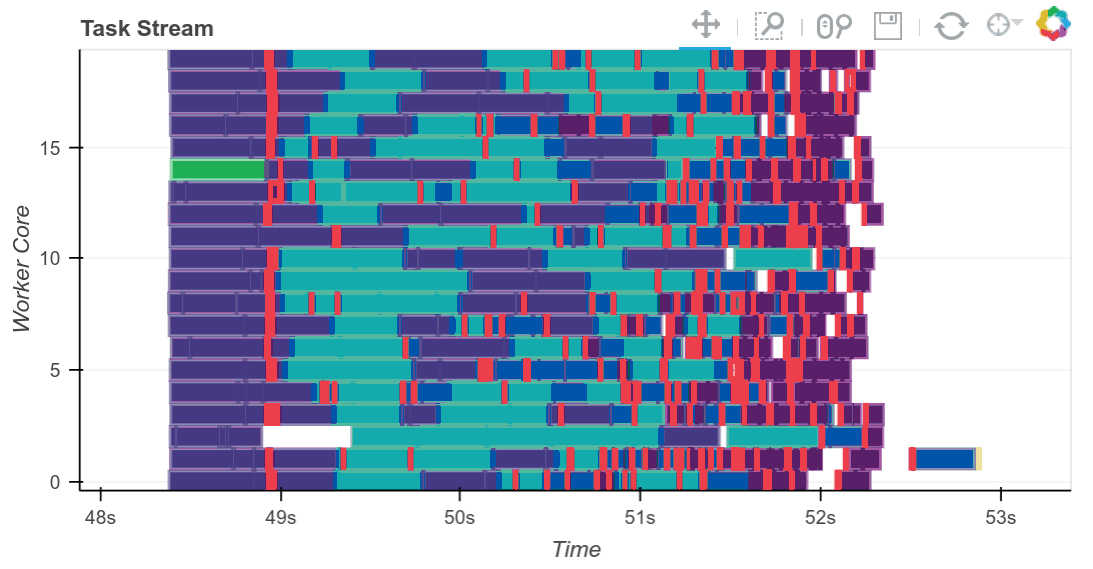
下方完成的 Bokeh 图像是交互式的。您可以通过选择右上角的工具进行平移和缩放。将鼠标悬停在矩形上,即可看到每个任务、它在哪一个工作节点上运行以及耗时多久。
我们看到我们充分利用了全部 20 个核心。必要时,中间结果会在工作节点之间传输(这些是红色矩形)。我们可以根据需要进行扩展。Dask 可以扩展到数千个核心。
结语
Dask 能够以 Celery/Luigi/Airflow 风格编写任意计算图,并以 Hadoop/Spark 承诺的可伸缩性来运行它们,这带来了一种愉快的自由度,可以舒适地编写代码,同时仍然能够进行可伸缩的计算。这种能力开辟了新的可能性,既支持更复杂的算法,又能处理现实世界中出现的复杂情况(企业数据系统有时确实很乱),同时仍保持在“正常和受支持的” Dask 操作范围内。
博客评论由 Disqus 提供支持