Dask、Pandas 和 XGBoost 在分布式系统之间良好协作
这项工作得到了 Continuum Analytics、XDATA 项目以及来自 Moore 基金会的数据驱动发现倡议的支持。
总结
本文讨论了如何使用 Dask 分布 Pandas Dataframes,然后将其交给分布式 XGBoost 进行训练。
更普遍地说,本文讨论了在同一个共享内存进程中启动多个分布式系统并平滑地在它们之间来回传递数据的价值。
引言
XGBoost 是一个备受喜爱的库,用于一类流行的机器学习算法——梯度提升树。它在商业中广泛使用,也是 Kaggle 竞赛中最受欢迎的解决方案之一。对于大型数据集或更快的训练,XGBoost 还自带其分布式计算系统,使其能够在集群中的多台机器上进行扩展。太棒了。分布式梯度提升树需求量很大。
然而,在使用分布式 XGBoost 之前,我们需要做三件事
- 准备和清洗我们可能很大的数据,这可能涉及大量的 Pandas 数据处理
- 设置 XGBoost 主节点和工作节点
- 将我们清洗好的数据从一组分布式 Pandas dataframes 交给集群上的 XGBoost 工作节点
结果发现这出奇地容易。这篇博客文章提供了一个快速示例,展示如何使用 Dask.dataframe 进行分布式 Pandas 数据处理,然后使用新的 dask-xgboost 包在 Dask 集群内设置 XGBoost 集群并执行数据交接。
在这个例子之后,我们将讨论通用设计以及这对其他分布式系统意味着什么。
示例
我们有一个十个节点的集群,每个节点有八个核心(EC2 上的 m4.2xlarges)
import dask
from dask.distributed import Client, progress
>>> client = Client('172.31.33.0:8786')
>>> client.restart()
<Client: scheduler='tcp://172.31.33.0:8786' processes=10 cores=80>
我们使用 dask.dataframe 加载 Airlines 数据集(只是分布在集群上的一组 Pandas dataframes),并做了一些预处理
import dask.dataframe as dd
# Subset of the columns to use
cols = ['Year', 'Month', 'DayOfWeek', 'Distance',
'DepDelay', 'CRSDepTime', 'UniqueCarrier', 'Origin', 'Dest']
# Create the dataframe
df = dd.read_csv('s3://dask-data/airline-data/20*.csv', usecols=cols,
storage_options={'anon': True})
df = df.sample(frac=0.2) # XGBoost requires a bit of RAM, we need a larger cluster
is_delayed = (df.DepDelay.fillna(16) > 15) # column of labels
del df['DepDelay'] # Remove delay information from training dataframe
df['CRSDepTime'] = df['CRSDepTime'].clip(upper=2399)
df, is_delayed = dask.persist(df, is_delayed) # start work in the background
这从 S3 上的 CSV 数据加载了几百个 pandas dataframes。然后我们不得不进行下采样,因为未来我们如何使用 XGBoost 似乎需要大量的 RAM。我不是 XGBoost 专家。请原谅我的无知。最后我们得到两个 dataframes
df:用于学习航班是否延误的数据is_delayed:这些航班是否延误。
熟悉 Pandas 的数据科学家可能会熟悉上面的代码。Dask.dataframe 与 Pandas 非常相似,但它在集群上运行。
>>> df.head()
| 年 | 月 | 星期几 | CRSDepTime | UniqueCarrier | 出发地 | 目的地 | 距离 | |
|---|---|---|---|---|---|---|---|---|
| 182193 | 2000 | 1 | 2 | 800 | WN | LAX | OAK | 337 |
| 83424 | 2000 | 1 | 6 | 1650 | DL | SJC | SLC | 585 |
| 346781 | 2000 | 1 | 5 | 1140 | AA | ORD | LAX | 1745 |
| 375935 | 2000 | 1 | 2 | 1940 | DL | PHL | ATL | 665 |
| 309373 | 2000 | 1 | 4 | 1028 | CO | MCI | IAH | 643 |
>>> is_delayed.head()
182193 False
83424 False
346781 False
375935 False
309373 False
Name: DepDelay, dtype: bool
分类并进行独热编码
XGBoost 不想处理像 destination=”LAX” 这样的文本数据。相反,我们为每个已知的机场和航空公司创建新的指示列。这会将我们的数据扩展成许多布尔列。幸运的是,Dask.dataframe 内置了所有这些便利函数(感谢 Pandas!)。
>>> df2 = dd.get_dummies(df.categorize()).persist()
这极大地扩展了我们的数据,但也使其更容易进行训练。
>>> len(df2.columns)
685
拆分和训练
很好,现在我们准备好拆分我们的分布式 dataframes 了
data_train, data_test = df2.random_split([0.9, 0.1],
random_state=1234)
labels_train, labels_test = is_delayed.random_split([0.9, 0.1],
random_state=1234)
启动一个分布式 XGBoost 实例,并在这个数据上进行训练
%%time
import dask_xgboost as dxgb
params = {'objective': 'binary:logistic', 'nround': 1000,
'max_depth': 16, 'eta': 0.01, 'subsample': 0.5,
'min_child_weight': 1, 'tree_method': 'hist',
'grow_policy': 'lossguide'}
bst = dxgb.train(client, params, data_train, labels_train)
CPU times: user 355 ms, sys: 29.7 ms, total: 385 ms
Wall time: 54.5 s
很好,所以我们能够在十分钟内使用我们的十台机器在该数据上训练一个 XGBoost 模型。我们得到的结果只是一个普通的 XGBoost Booster 对象。
>>> bst
<xgboost.core.Booster at 0x7fa1c18c4c18>
我们可以在本地的普通 Pandas 数据上使用它
import xgboost as xgb
pandas_df = data_test.head()
dtest = xgb.DMatrix(pandas_df)
>>> bst.predict(dtest)
array([ 0.464578 , 0.46631625, 0.47434333, 0.47245741, 0.46194169], dtype=float32)
或者我们可以再次使用 dask-xgboost 在我们的分布式保留数据上进行训练,得到另一个 Dask series。
>>> predictions = dxgb.predict(client, bst, data_test).persist()
>>> predictions
Dask Series Structure:
npartitions=93
None float32
None ...
...
None ...
None ...
Name: predictions, dtype: float32
Dask Name: _predict_part, 93 tasks
评估
我们可以将这些预测结果带到本地进程,并使用普通的 Scikit-learn 操作来评估结果。
>>> from sklearn.metrics import roc_auc_score, roc_curve
>>> print(roc_auc_score(labels_test.compute(),
... predictions.compute()))
0.654800768411
fpr, tpr, _ = roc_curve(labels_test.compute(), predictions.compute())
# Taken from
http://scikit-learn.org/stable/auto_examples/model_selection/plot_roc.html#sphx-glr-auto-examples-model-selection-plot-roc-py
plt.figure(figsize=(8, 8))
lw = 2
plt.plot(fpr, tpr, color='darkorange', lw=lw, label='ROC curve')
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
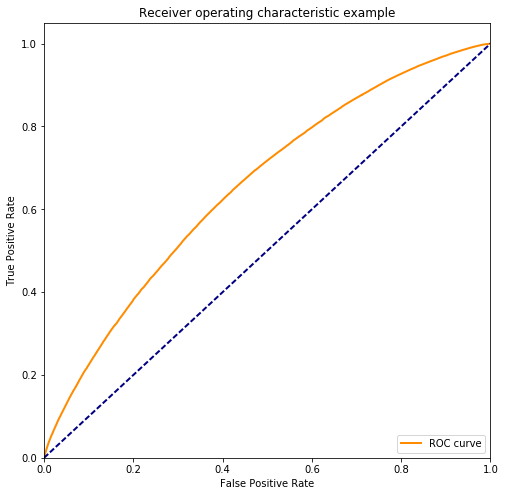
我们可能想调整上面的参数或尝试不同的数据来改进我们的解决方案。这里的重点不是我们很好地预测了航班延误,而是如果你是一个了解 Pandas 和 XGBoost 的数据科学家,我们上面所做的一切看起来都相当熟悉。上面的例子中没有太多新内容。我们使用的工具和以前一样,只是规模更大了。
分析
好的,既然我们已经证明了这一点有效,现在让我们来谈谈刚才发生的事情,以及这对于分布式服务之间的协作通常意味着什么。
dask-xgboost 的作用
dask-xgboost 项目相当小巧简单(200 TLOC)。给定一个由一个中央调度器和几个分布式工作节点组成的 Dask 集群,它会在运行 Dask 调度器的同一个进程中启动一个 XGBoost 调度器,并在每个 Dask 工作节点中启动一个 XGBoost 工作节点。它们共享相同的物理进程和内存空间。Dask 的构建就是为了支持这种情况,所以这相对容易。
然后我们要求 Dask.dataframe 在 RAM 中完全实现,并询问所有组成它的 Pandas dataframes 位于何处。我们告诉每个 Dask 工作节点将其拥有的所有 Pandas dataframes 交给其本地的 XGBoost 工作节点,然后就让 XGBoost 自己完成工作。Dask 不为 XGBoost 提供动力,它只是进行设置,提供数据,然后让它在后台工作。
人们经常问 Dask 提供哪些机器学习能力,以及它们如何与 H2O 或 Spark 的 MLLib 等其他分布式机器学习库进行比较。对于梯度提升树,200 行的 dask-xgboost 包就是答案。Dask 没有必要创建这样的算法,因为 XGBoost 已经存在,运行良好,并为 Dask 用户提供了一个功能齐全且高效的解决方案。
由于 Dask 和 XGBoost 可以同处于同一个 Python 进程中,它们之间可以无代价地共享字节,可以相互监控等等。这两个分布式系统在多个进程中共同存在,就像 NumPy 和 Pandas 在单个进程中协同操作一样。如果您想轻松使用多个专业服务并避免大型单体框架,与多个系统共享分布式进程可能会非常有益。
连接到其他分布式系统
不久前,我写了 一篇类似的博客文章,讲述了如何以与此处完全相同的方式从 Dask 托管 TensorFlow。同样容易的是,可以在 Dask 旁边设置 TensorFlow,给它提供数据,然后让 TensorFlow 自己完成工作。
一般来说,这种“服务其他库”的方法是 Dask 在可能的情况下运行的方式。我们今天能够覆盖如此广泛的功能,是因为我们严重依赖现有的开源生态系统。Dask.arrays 使用 Numpy 数组,Dask.dataframes 使用 Pandas,现在 Dask 处理梯度提升树的答案就是使其使用分布式 XGBoost 变得非常非常容易。瞧!我们得到一个功能齐全的解决方案,由其他敬业的开发人员维护,并且整个连接过程在一个周末内就完成了(详情请参阅 dmlc/xgboost #2032)。
自从这出现以来,我们收到了支持其他分布式系统(如 Elemental)以及进行通用 MPI 计算交接的请求。如果我们可以用同一组进程启动两个系统,那么所有这些都是相当可行的。当您可以在同一进程中将一个系统的工作节点中的 numpy 数组传递给另一个系统的工作节点时,许多系统间协作的挑战就消失了。
致谢
感谢 陈天奇 和 Olivier Grisel 在 构建和测试 dask-xgboost 时提供的帮助。感谢 Will Warner 帮助编辑本文。
博客评论由 Disqus 提供支持