Dask 在 HPC 上的应用 - 初步工作
这项工作得到了 Anaconda 公司 和 NSF EarthCube 项目的支持。
我们最近宣布了与美国国家大气研究中心 (NCAR)、哥伦比亚大学以及 Anaconda 公司的一项合作,旨在利用 XArray 和 Dask 在高性能计算机 (HPC) 上加速大气和海洋数据的分析。这项拟议工作的全文可在此处获取。我们非常感谢 NSF EarthCube 项目资助这项工作,考虑到最近发生的(以及持续存在的威胁)哈维、艾尔玛和何塞等主要风暴,这项工作在今天显得尤为重要。
这是由学术科学家(哥伦比亚大学)、基础设施管理人员(NCAR)以及软件开发者(Anaconda、哥伦比亚大学和 NCAR)组成的合作,旨在将使用 XArray 和 Jupyter 的现有工作流程扩展到大型 HPC 系统和拍字节级数据集上。在资助项目启动的第一周,我们中的一些人专注于最快的方法,让科研团队能够在这些 HPC 系统上使用 XArray、Dask 和 Jupyter。这篇博客文章详细介绍了我们取得的成就以及在那第一周发现的一些新挑战。我们希望将来能有更多类似的博客文章。今天我们将涵盖以下主题:
- 使用 MPI 部署 Dask
- 在批处理作业调度程序上进行交互式部署,此处以 PBS 为例
- 在远程系统中 JupyterLab 的优势
- 网络性能与 3GB/s 的 InfiniBand
- 现代化 XArray 与 Dask 分布式调度程序的交互
关于如何在 HPC 系统上将 Dask 部署到 XArray 上的视频演练可在 YouTube 上获取,而拥有Cheyenne 超级计算机访问权限的大气科学家可在此处获取说明。
现在让我们从技术问题开始
使用 MPI 部署 Dask
HPC 系统使用 SGE、SLURM、PBS、LSF 等作业调度程序。Dask 以前曾被学术团体或金融公司部署在所有这些系统上。然而,每次这样做时都会略有不同,并且通常是为特定的集群量身定制的。
我们希望做得更通用一些。这始于一个关于 PBS 脚本的 GitHub issue,该 issue 试图创建一个简单的通用模板,供人们复制和修改。不幸的是,这方面存在显著的挑战。HPC 系统及其作业调度程序似乎主要关注并易于支持两种常见的使用场景:
- 极度并行的“运行此脚本 1000 次”的作业。这对于我们需要做的事情来说太简单了。
- MPI 作业。这似乎有点大材小用,但最终是我们采取的方法。
部署 Dask 介于这两者之间。它属于主-从模式(或者更恰当地说是协调者-工作者模式)。我们最终构建了一个启动 Dask 的MPI4Py程序。MPI 得到了所有 HPC 作业调度程序的良好支持,更重要的是持续支持,因此依赖 MPI 提供了跨机器的稳定性。现在 dask.distributed 附带了一个新的 dask-mpi 可执行文件。
mpirun --np 4 dask-mpi
需要澄清的是,Dask 不使用 MPI 进行进程间通信。它仍然使用 TCP。我们只是使用 MPI 来启动一个调度程序和几个工作者,并将它们连接起来。在伪代码中,dask-mpi 可执行文件大致如下所示:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
if rank == 0:
start_dask_scheduler()
else:
start_dask_worker()
从社交层面来看,这非常有用,因为每个集群管理团队都知道如何支持 MPI,所以任何能访问此类集群的人都有可以寻求帮助的对象。我们成功地将“如何启动 Dask?”这个问题转化为了“如何运行这个 MPI 程序?”,后者是超级计算机设施的技术人员通常更擅长处理的问题。
在批处理调度程序上进行交互式工作
我们的合作专注于大数据的交互式分析。这意味着人们期望打开 Jupyter 笔记本,连接到由多台机器组成的集群,并在他们坐在电脑前时在这些机器上进行计算。
不幸的是,大多数作业调度程序是为批处理调度而设计的。它们会尝试快速运行你的作业,但也不介意等待几个小时,以便超级计算机上出现一套可用的机器。当你请求更多时间或更多机器时,等待时间可能会急剧增加。对于大多数 MPI 作业来说,这没问题,因为人们并不期望立即获得结果,而且他们肯定不会与程序进行交互,但在我们的案例中,我们确实希望立即获得一些结果,即使它们只是我们请求的一部分。
长期解决这个问题需要技术工作和策略决策。短期内,我们利用了两个事实:
- 许多小作业可以比少数大作业更快启动。这些作业利用了调度中那些对大作业来说太小的空隙。
- Dask 不需要一次性全部启动。工作者可以随时加入或离开。
因此我发现,如果我申请几个单机作业,我就可以很容易地拼凑出一个规模可观且启动非常快的集群。实际上,这看起来如下:
qsub start-dask.sh # only ask for one machine
qsub add-one-worker.sh # ask for one more machine
qsub add-one-worker.sh # ask for one more machine
qsub add-one-worker.sh # ask for one more machine
qsub add-one-worker.sh # ask for one more machine
qsub add-one-worker.sh # ask for one more machine
qsub add-one-worker.sh # ask for one more machine
我们的主作业的墙钟时间(wall time)大约为一个小时。工作者的墙钟时间较短。随着计算需求的变化,它们可以在整个计算过程中按需加入或离开。
Jupyter Lab 和 Web 前端
我们的科研协作者喜欢用 Jupyter 笔记本记录他们的工作。这使他们能够同时管理代码、科学思考和可视化输出,并且对他们来说,这是一个可以与他们的科研团队和协作者分享的成果。为了帮助他们,我们在他们分配到的、运行 Dask 调度程序的同一台机器上启动一个 Jupyter 服务器。然后,我们为他们提供 SSH 隧道命令,他们可以复制粘贴这些命令,以便从个人计算机访问 Jupyter 服务器。
我们一直在使用新的 Jupyter Lab,而不是传统的笔记本。这对我们来说特别方便,因为它提供了他们在不使用本地机器工作时失去的大部分交互体验。他们无需反复 SSH 进入 HPC 系统,即可获得文件浏览器、终端、方便的文本文件可视化等功能。我们在一个连接上通过直观的 Jupyter 界面获得了所有这些功能。
目前,我们提供了一个脚本来设置所有这些。它使用 Dask 启动 Jupyter Lab,然后打印出 SSH 隧道命令。
from dask.distributed import Client
client = Client(scheduler_file='scheduler.json')
import socket
host = client.run_on_scheduler(socket.gethostname)
def start_jlab(dask_scheduler):
import subprocess
proc = subprocess.Popen(['jupyter', 'lab', '--ip', host, '--no-browser'])
dask_scheduler.jlab_proc = proc
client.run_on_scheduler(start_jlab)
print("ssh -N -L 8787:%s:8787 -L 8888:%s:8888 -L 8789:%s:8789 cheyenne.ucar.edu" % (host, host, host))
从长远来看,我们希望切换到完全的点击式界面(也许像 JupyterHub 那样),但这需要额外考虑如何将分布式资源与 Jupyter 服务器实例一起部署。
InfiniBand 上的网络性能
预期的计算需要在集群中移动几个 TB 的数据。在这个集群上,使用高速 InfiniBand 网络时,Dask 在每台机器上获得了大约 1GB/s 的同时读/写网络带宽。对于任何商品或基于云的系统来说,这都是非常快的(大约是我在 Amazon 上观察到的 10 倍)。然而,对于超级计算机来说,这仅是可能性能的大约 30%(参见硬件规格)。
我怀疑这是由于 Dask 底层使用的网络库 Tornado 在字节处理方面的问题。下图显示了一台工作者在通信密集型工作负载后的诊断仪表盘。我们看到读写速度都达到了 1GB/s。我们还看到 CPU 使用率达到了 100%。
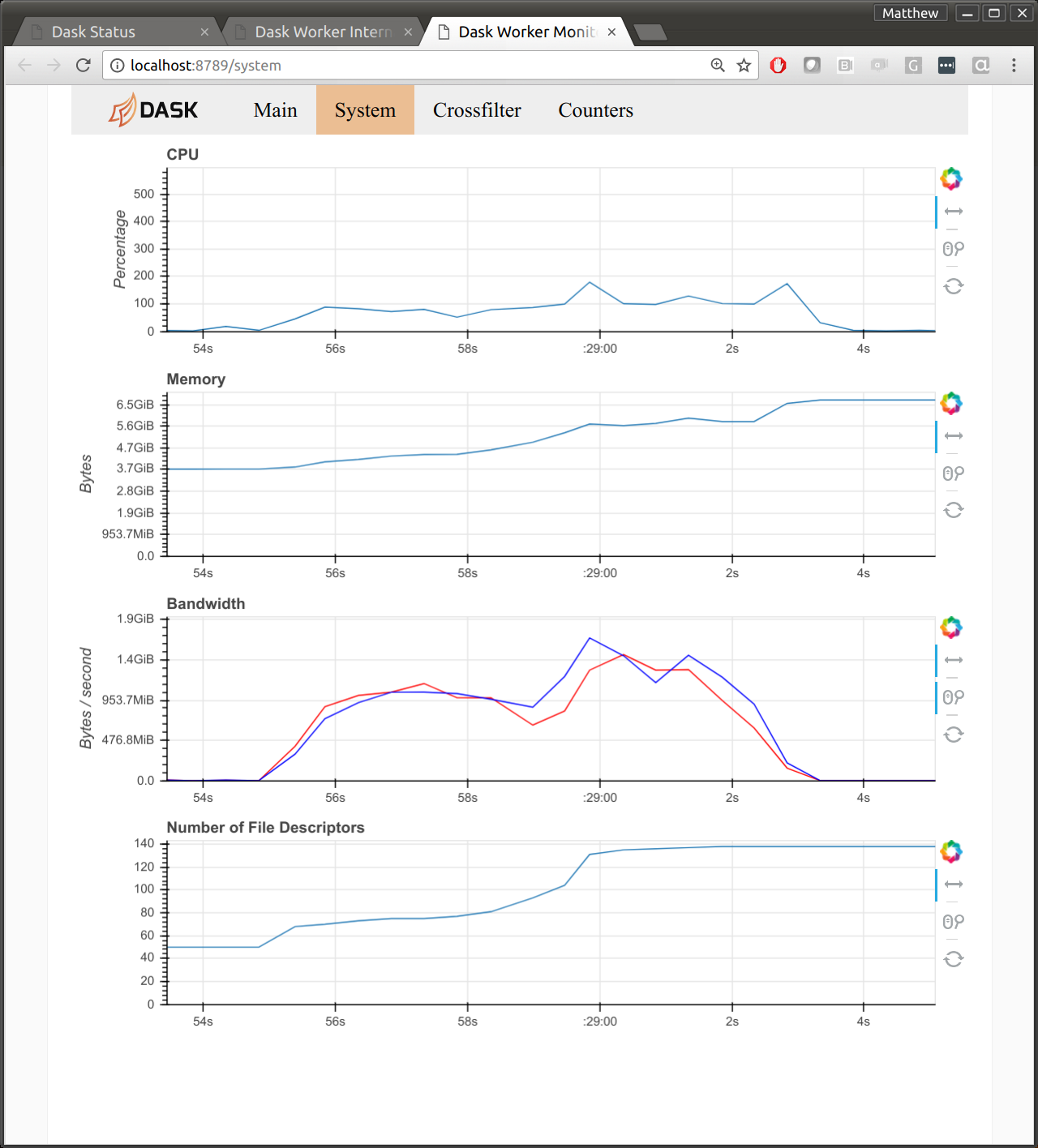
对于关注 Dask 的 HPC 用户来说,网络性能是一个大问题。如果我们能接近 MPI 带宽,那么这可能有助于减轻这个注重性能的社区的担忧。
XArray 与 Dask.distributed
XArray 是第一个在内部使用 Dask 的主要项目。这次早期集成对于通过用户反馈验证 Dask 的内部机制至关重要。然而,这也意味着 XArray 的一些部分是在 Dask 的一些较新部分(特别是异步分布式调度功能)出现之前设计的。
XArray 仍然可以在分布式集群上使用 Dask,但只能使用那些在单机调度程序上也可用的一小部分功能。这意味着目前使用 XArray 在分布式内存中持久化数据、并行调试、发布共享数据集等方面,都需要比理论上应有的更多工作。
为了解决这个问题,我们计划更新 XArray,使其遵循新提出的Dask 接口。这个接口足够复杂,可以处理所有 Dask 调度功能,但又足够轻量,实际上不需要对 Dask 库本身产生任何依赖。(这是 Jim Crist 的工作。)
我们最终还需要考虑减少检查多个 NetCDF 文件的开销,但我们还没有遇到这个问题,所以我打算再等等。
未来工作
我们认为目前科学用户已经可以开始使用该系统了。我们有一个 Cheyenne 上的 Dask 入门 wiki 页面,我们的第一批“小白鼠”用户已经成功地运行了一遍,没有遇到太多麻烦。我们还确定了一些问题,软件开发者可以在科研团队开始工作时着手解决。
我们非常乐意在此过程中与其他协作者合作。如果您或您的团队正在研究相关问题,我们很想听听您的意见。这项资助不仅是为了满足哥伦比亚大学和 NCAR 研究人员的科研需求,更是为了构建能够惠及整个大气和海洋社区的长期系统。请在 Pangeo GitHub issue tracker 上参与讨论。
博客评论由 Disqus 提供