Python 中的快速地理空间分析
这项工作由 Anaconda Inc.、摩尔基金会 (Moore Foundation) 的数据驱动发现计划以及 NASA SBIR NNX16CG43P 提供支持。
这项工作是与 Joris Van den Bossche 合作完成的。这篇博文基于 Joris 在 EuroSciPy 上的演讲(幻灯片),主题相同。你也可以查看 Joris 关于此主题的 博文。
TL;DR (太长不看)
Python 的地理空间技术栈很慢。我们使用 Cython 和 Dask 加速了 GeoPandas 库。Cython 提供了 10-100 倍的加速。Dask 在多核笔记本电脑上额外提供了 3-4 倍的加速。一切都还处于早期阶段,欢迎大家前来帮助。
我们首先复现了去年六月发表的一篇博文,但实现了 30 倍的加速。然后我们讨论了如何通过 Cython 和 Dask 实现这一加速。
本文中的所有代码都是实验性的,不应依赖于此。
实验
去年六月,Ravi Shekhar 发表了一篇题为《使用 Dask 和 GeoPandas 进行大规模地理空间操作》的博文,他在文中统计了纽约市每个官方出租车区域的乘车次数。他读取、处理并绘制了 1.2 亿次乘车数据,对每次乘车都进行了耗时的点多边形测试,并生成了一个类似于下图的图表
这在他的笔记本电脑上花费了大约三个小时。他使用 Dask 和一些自定义代码来利用所有核心并行处理 Geopandas。通过这种组合,他获得了接近 PostGIS 的速度,而且是在 Python 中实现的。
如今,使用加速的 GeoPandas 和新的 dask-geopandas 库,我们可以在大约八分钟内完成上述计算(其中一半时间用于读取 CSV 文件),从而可以生成许多其他有趣的图像,并且交互时间更快。
生成这些图表的完整 Notebook 如下所示
本文其余部分将讨论 GeoPandas、Cython 以及如何加速地理空间数据分析。
地理空间数据背景
Shapely 用户手册以以下段落开头,论述了地理空间分析对我们社会的效用。
确定性空间分析是农业、生态学、流行病学、社会学和许多其他领域计算方法中解决问题的重要组成部分。这些动物栖息地斑块的测量周长/面积比是多少?这个镇上的哪些房产与这个新洪水模型预测的 50 年洪水等高线相交?带有标记“A”和“B”的古代陶瓷器物的发现地点范围是什么,这些范围在哪里重叠?从家到办公室的最佳路径是什么,可以最好地避开已识别的基于位置的垃圾信息区域?这些只是使用非统计空间分析,更具体地说,计算几何可以解决的一些可能问题。
Shapely 是 Python 地理空间技术栈的一部分,该技术栈目前由以下库组成
- Shapely:管理点、线串、多边形等形状。封装了 GEOS C++ 库
- Fiona:处理数据摄入。封装了 GDAL 库
- Rasterio:处理栅格数据,如卫星图像
- GeoPandas:通过添加一列 shapely 几何对象来扩展 Pandas,以便直观地查询带有地理空间注释数据的表格。
这些库为 OSGeo C/C++ 库(GEOS、GDAL 等)提供了直观的 Python 封装,这些库几乎为所有开源地理空间库(如 PostGIS、QGIS 等)提供支持。它们提供相同的功能,但由于使用 Python 的方式,通常要慢得多。对于小型数据集来说这是可以接受的,但随着我们转向越来越大的数据集,这就会成为一个问题。
在本文中,我们专注于 GeoPandas,它是 Pandas 的一个地理空间扩展,用于管理带有几何信息(如点、路径和多边形)的表格数据。
GeoPandas 示例
GeoPandas 可以轻松加载、处理和绘制地理空间数据。例如,我们可以下载纽约出租车区域数据,然后用一行代码加载并绘制出来。
geopandas.read_file('taxi_zones.shp')
.to_crs({'init' :'epsg:4326'})
.plot(column='borough', categorical=True)

现在城市正在积极地公开数据。这提供了透明度,也为公民参与分析、理解和改善我们的社区提供了机会。这里有一些有趣的地理空间数据集,可能会引起你的兴趣
性能
不幸的是,GeoPandas 速度较慢。这限制了对大型数据集的交互式探索。例如,上面的第一个数据集——芝加哥犯罪数据——有七百万条记录,内存中占用几个 GB。目前使用 GeoPandas 交互式分析如此大的数据集是不可行的。

这种速度下降是因为 GeoPandas 将每个几何对象(如点、线或多边形)封装成一个 Shapely 对象,并将所有这些对象存储在一个 object-dtype 列中。当我们在所有形状上计算 GeoPandas 操作时,我们只是在 Python 中迭代这些形状。例如,这就是目前在 GeoPandas 中实现距离方法的方式。
def distance(self, other):
result = [geom.distance(other)
for geom in self.geometry]
return pd.Series(result)
不幸的是,这只是迭代系列中的元素,每个元素都是一个独立的 Shapely 对象。这效率低下,原因有二
- 相对于在 C 中迭代相同的对象,在 Python 中迭代对象速度较慢。
- Shapely Python 对象比它们封装的 GEOS Geometry 对象消耗更多内存。
这导致了性能低下。
用 Cython 加速 GeoPandas
幸运的是,我们使用 Cython 重写了 GeoPandas,直接循环遍历底层的 GEOS 指针。根据操作的不同,这提供了 10-100 倍的加速。因此,我们不再使用一个 包含 shapely 对象的 Pandas object-dtype 列,而是存储一个 直接指向 GEOS 对象的指针 的 NumPy 数组。
之前
之后

例如,我们计算距离的函数现在看起来像以下 Cython 实现(为简洁起见有所省略)
cpdef distance(self, other):
cdef int n = self.size
cdef GEOSGeometry *left_geom
cdef GEOSGeometry *right_geom = other.__geom__ # a geometry pointer
geometries = self._geometry_array
with nogil:
for idx in xrange(n):
left_geom = <GEOSGeometry *> geometries[idx]
if left_geom != NULL:
distance = GEOSDistance_r(left_geom, some_point.__geom)
else:
distance = NaN
对于快速操作,我们看到 100 倍的加速。对于较慢的操作,我们接近 10 倍的加速。现在这些操作以完整的 C 速度运行。
在 他的 EuroSciPy 演讲中,Joris 比较了 GeoPandas(Cython 化前后)与流行 PostgreSQL 数据库的标准地理空间插件 PostGIS 的性能(包含比较的原始 Notebook)。我从他的演讲中“借用”了一些图表如下
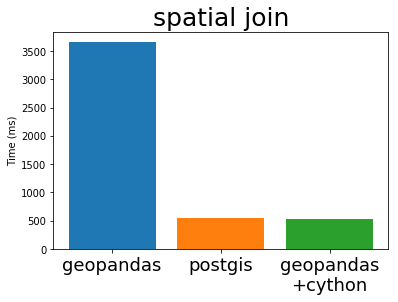
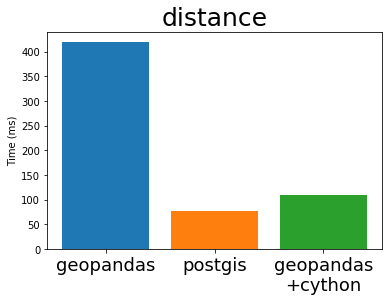

Cython 化的 GeoPandas 和 PostGIS 几乎以完全相同的速度运行。这是因为它们使用了相同的底层 C 库 GEOS。这些算法并不是特别复杂,所以每个人都以完全相同的方式实现它们也就不足为奇了。
这很棒。Python GIS 技术栈现在拥有一个全速运行的库,其运行速度可能与其他任何开放 GIS 系统一样快。
问题
然而,这仍然是一项正在进行中的工作,还有大量工作要做。
首先,我们需要 Pandas 以不同于跟踪普通整数数组的方式来跟踪我们的 GEOS 指针数组。这既是为了可用性原因,例如我们希望以不同的方式渲染它们,并且不希望用户能够对这些数组执行求和和平均等数值操作,也是为了稳定性原因,因为我们需要跟踪这些指针并在适当的时候从内存中释放它们分配的 GEOSGeometry 对象。目前,我们正在通过创建一个新的块类型 GeometryBlock 来实现这个目标(“块”是 pandas 的内部构建块,用于存储不同列的数据)。这将需要对 Pandas 本身进行一些修改,以启用自定义块类型(请参阅 pandas 问题追踪器上的此问题)。
其次,数据摄入仍然很慢。这不依赖于 GEOS,而是依赖于 GDAL/OGR,目前在 Python 中由 Fiona 处理。Fiona 更侧重于一致性和可用性,而不是原始速度。以前 GeoPandas 速度慢时,这说得通,因为没有人处理特别大的数据集。然而现在我们发现,数据加载往往比所有操作都要耗费几倍的时间,因此未来可能需要在这方面投入一些精力。
第三,GeoPandas 中有一些算法我们尚未进行 Cython 化。这包括叠加和溶解操作等特定功能以及 GeoJSON 输出等小型组件。
最后,正如任何尚未经过全面测试的代码库重写一样(我们正在努力改进测试),可能存在一些我们无法检测到的错误,直到一些耐心且宽容的用户首先遇到它们。
尽管如此,所有线性地理空间操作都能正常工作并经过了全面测试。空间连接(许多地理空间操作的主干)也已全速运行。如果你在非生产环境工作,那么 Cython 化的 GeoPandas 可能值得你花时间去研究。
你可以在 geopandas/geopandas #473 跟踪这项工作的未来进展,其中包含了安装说明。
使用 Dask 并行化
Cython 化为我们提供了 10-100 倍范围内的加速。我们尽可能有效地利用了 GEOS 库的一个核心。现在我们转向并行使用多个核心。这在标准的 4 核笔记本电脑上额外提供了 3-4 倍的加速。我们也可以扩展到集群,但这部分我将留到未来的博文中介绍。
为了并行化,我们需要将数据集分成多个块。我们可以简单地将前一百万行放在一个块中,第二个一百万行放在另一个块中,依此类推;或者我们可以按空间划分数据,例如将数据集某个区域的所有数据放在一个块中,将另一个区域的所有数据放在另一个块中,等等。这两种方法都在 GitHub 上的一个基本 dask-geopandas 库中实现。
因此,就像 dask-array 将许多 NumPy 数组组织成一个网格,dask-dataframe 将许多 Pandas DataFrames 组织成一个线性索引一样


dask-geopandas 库将许多 GeoPandas DataFrames 组织成空间区域。在下面的示例中,我们可以将纽约市的数据划分为不同的行政区。每个行政区的数据将由不同的线程独立处理,或者在分布式环境中,可能位于不同的机器上。

这给我们带来了两个优势
- 即使没有地理空间分区,我们也可以使用多个核心(或多台机器)来加速简单操作。
- 对于空间感知操作,如空间连接或子选择,我们可以只处理并行 DataFrame 中我们知道与计算相关的那部分。
然而,这也很昂贵,并非总是必要。在处理纽约出租车数据的初步实验中,我们没有这样做,但仍然从普通的多核操作中获得了显著的加速。
实践
因此,为了生成本文顶部的图片,我们使用了 dask.dataframe 加载 CSV 文件,dask-geopandas 执行空间连接,然后使用 dask.dataframe 和常规 pandas 执行实际计算的组合。我们的代码大致如下所示
import dask.dataframe as dd
import dask_geopandas as dg
df = dd.read_csv('yellow_tripdata_2015-*.csv')
gf = dg.set_geometry(df, geometry=df[['pickup_longitude', 'pickup_latitude']],
crs={'init' :'epsg:4326'})
gf = dg.sjoin(gf, zones[['zone', 'borough', 'geometry']])
full = gf[['zone', 'payment_type', 'tip_amount', 'fare_amount']]
full.to_parquet('nyc-zones.parquet') # compute and cache result on disk
full = dd.read_parquet('nyc-zones.parquet')
然后,我们可以在现在已正确标注区域的更典型的类似 pandas 的数据上进行常见的 groupby 和 join 操作。
result = full.passenger_count.groupby(full.zone).count().compute()
result.name = 'count'
joined = pd.merge(result.to_frame(), zones,
left_index=True, right_on='zone')
joined = geopandas.GeoDataFrame(joined) # convert back for plotting
我们用几行新的标准代码替换了 Ravi 大部分的自定义分析。这在进行空间连接时最大限度地利用了我们的 CPU。这里的每一步都很好地释放了 GIL,整个计算在几 GB 的内存下运行。
问题
dask-geopandas 项目目前是一个原型。它很容易在非简单应用(实际上也包括许多简单应用)中崩溃。它的设计目的是为了看看实现一些更复杂的操(如空间连接、重新分区和叠加)作有多困难。这就是为什么例如它支持完全分布式的空间连接,但缺少索引等简单操作。还有其他更长远的问题。
序列化成本尚可管理,但相当高。我们目前使用的是在其他地理空间应用中常见的标准“已知二进制” WKB 格式,但发现它相当慢,这阻碍了进程间的并行化。
类似地,分布式和空间分区的数据库似乎并不常见(或者至少我还没有遇到过)。
目前还不清楚 dask-geopandas DataFrames 与普通 dask DataFrames 应该如何交互。复用 dask.dataframe 中的所有算法会非常方便,但这两个库的索引结构差异很大。这可能需要 Dask 开发人员做一些巧妙的软件工程。
尽管如此,这些问题似乎都是可以克服的,而且总体而言,这个过程到目前为止还算顺利。我预计,只需要适度的努力,我们就能构建一个直观且高性能的并行 GIS 分析系统。
博文开头的示例 Notebook 展示了如何使用 dask-geopandas 并取得了不错的结果。
结论
借助 PyData 领域成熟的技术,如 Cython 和 Dask,我们已经能够将 GeoPandas 操作加速和扩展到超出行业标准的水平。然而,这项工作仍处于实验阶段,尚未准备好用于生产环境。这项工作对于 Joris 和 Matthew 来说都只是一个副项目,他们欢迎其他有经验的开源开发者贡献力量。我们相信这个项目能够产生巨大的社会影响,并对未来继续推进它充满热情。希望您也能分享我们的热情。
博客评论由 Disqus 提供支持