流式 Dataframes
这项工作由 Anaconda Inc 和 Moore Foundation 的数据驱动发现计划提供支持
本文介绍的是实验性软件。尚未准备好供公众使用。本文中的所有代码示例和 API 都可能随时更改,恕不另行通知。
摘要
本文描述了一个原型项目,该项目使用 Pandas 和 Streamz 处理表格数据的连续数据源。
引言
有些数据永远不会停止。它以持续不断的流形式连续到达。这发生在金融时间序列、Web 服务器日志、科学仪器、物联网遥测等等领域。处理这些数据的算法与你在 NumPy 和 Pandas 等库中找到的算法略有不同,后者假设它们预先知道所有数据。仍然可以使用 NumPy 和 Pandas,但你需要将它们与一些巧妙的方法结合起来,并保留足够的中间数据,以便在新数据进来时计算增量更新。
示例:流式均值
例如,想象一下我们有一个连续到达的 CSV 文件流,并且我们想打印出我们数据随时间的平均值。每当一个新的 CSV 文件到达时,我们需要重新计算整个数据集的平均值。如果我们聪明,我们会保留足够的中间状态,以便在不回顾其余历史数据的情况下计算这个平均值。我们可以通过维护运行总计和运行计数来实现这一点,如下所示
total = 0
count = 0
for filename in filenames: # filenames is an infinite iterator
df = pd.read_csv(filename)
total = total + df.sum()
count = count + df.count()
mean = total / count
print(mean)
现在,当我们向 filenames 迭代器添加新文件时,我们的代码会打印出随时间更新的新平均值。我们没有一个单一的平均值结果,我们有一个连续的平均值结果流,每个结果都对截止到该点的数据有效。我们的输出数据是一个无限流,就像我们的输入数据一样。
当我们的计算是像这样线性和直接时,一个 for 循环就足够了。然而,当我们的计算有几个流分支或汇合,可能在它们之间有限速或缓冲时,这种 for 循环方法会变得复杂且难以管理。
Streamz
几个月前,我推出了一个名为 streamz 的小型库,它处理管道的控制流,包括线性映射操作、累积状态的操作、分支、连接,以及背压、流量控制、反馈等等。Streamz 的设计宗旨是处理所有数据移动并在正确的时间发出计算信号。这个库被几个团队悄悄使用,现在感觉相当简洁和有用。
Streamz 旨在处理此类系统的控制流,但对流式算法没有任何帮助。在过去的一周里,我一直在 streamz 之上构建一个 dataframe 模块,以帮助处理常见的流式表格数据场景。这个模块使用 Pandas 并实现了 Pandas API 的一个子集,因此希望对于具有现有 Python 知识的程序员来说易于使用。
示例:流式均值
上面的例子可以用 streamz 这样写
source = Stream.filenames('path/to/dir/*.csv') # stream of filenames
sdf = (source.map(pd.read_csv) # stream of Pandas dataframes
.to_dataframe(example=...)) # logical streaming dataframe
sdf.mean().stream.sink(print) # printed stream of mean values
这个例子并不比 for 循环版本更清晰。就其本身而言,这可能是一个比之前更糟糕的解决方案,仅仅因为它涉及新技术。然而,在两种情况下它开始变得有用
-
你想进行更复杂的流式算法
sdf = sdf[sdf.name == 'Alice'] sdf.x.groupby(sdf.y).mean().sink(print) # or sdf.x.rolling('300ms').mean()使用上面那样的 for 循环构建这些算法需要更多的技巧。
-
你想执行多个操作、处理流量控制等。
sdf.mean().sink(print) sdf.x.sum().rate_limit(0.500).sink(write_to_database) ...持续地分支出计算、正确地路由数据以及处理时间,这些都可能难以一致地实现。
Jupyter 集成和流式输出
在开发过程中,我们发现 Jupyter 中有实时更新的输出非常有用。
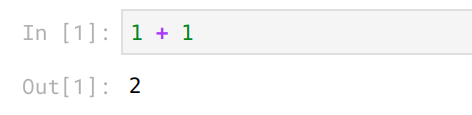
通常我们在 Jupyter 中评估代码时有静态输入和静态输出
然而现在我们的输入和输出都是实时的
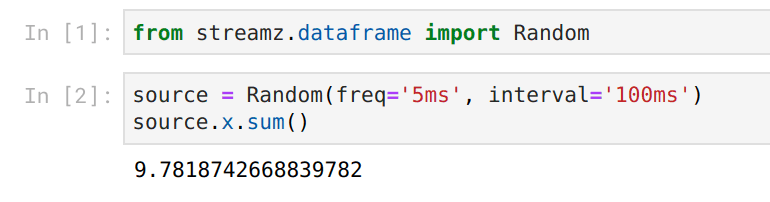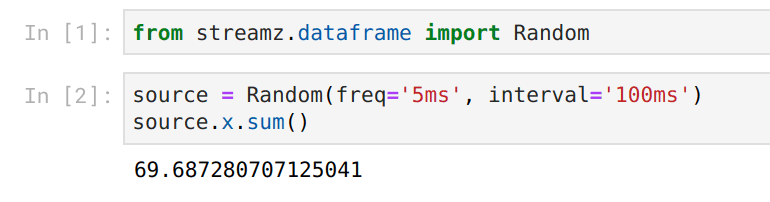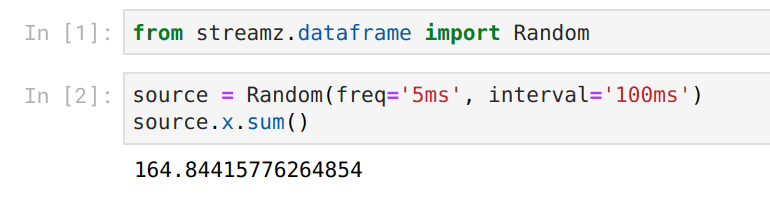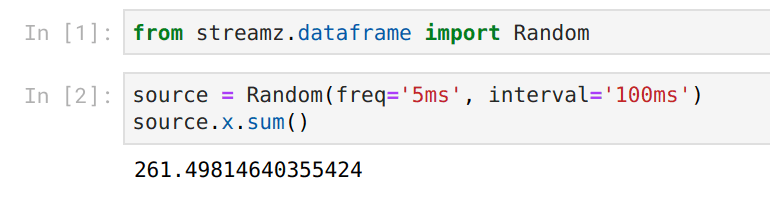
我们通过结合使用 ipywidgets 和 Bokeh 图表来实现这一点,它们都提供了很好的钩子来改变之前的 Jupyter 输出,并且与 Tornado IOLoop 配合良好(streamz、Bokeh、Jupyter 和 Dask 都使用 Tornado 实现并发)。每当有变化时,我们都能构建出良好的响应式反馈。
在下面的例子中,我们构建了一个 CSV 到 dataframe 的管道,只要目录中出现新文件就会更新。每当我们把文件拖到左侧的数据目录时,我们都会看到右侧的所有输出都更新了。
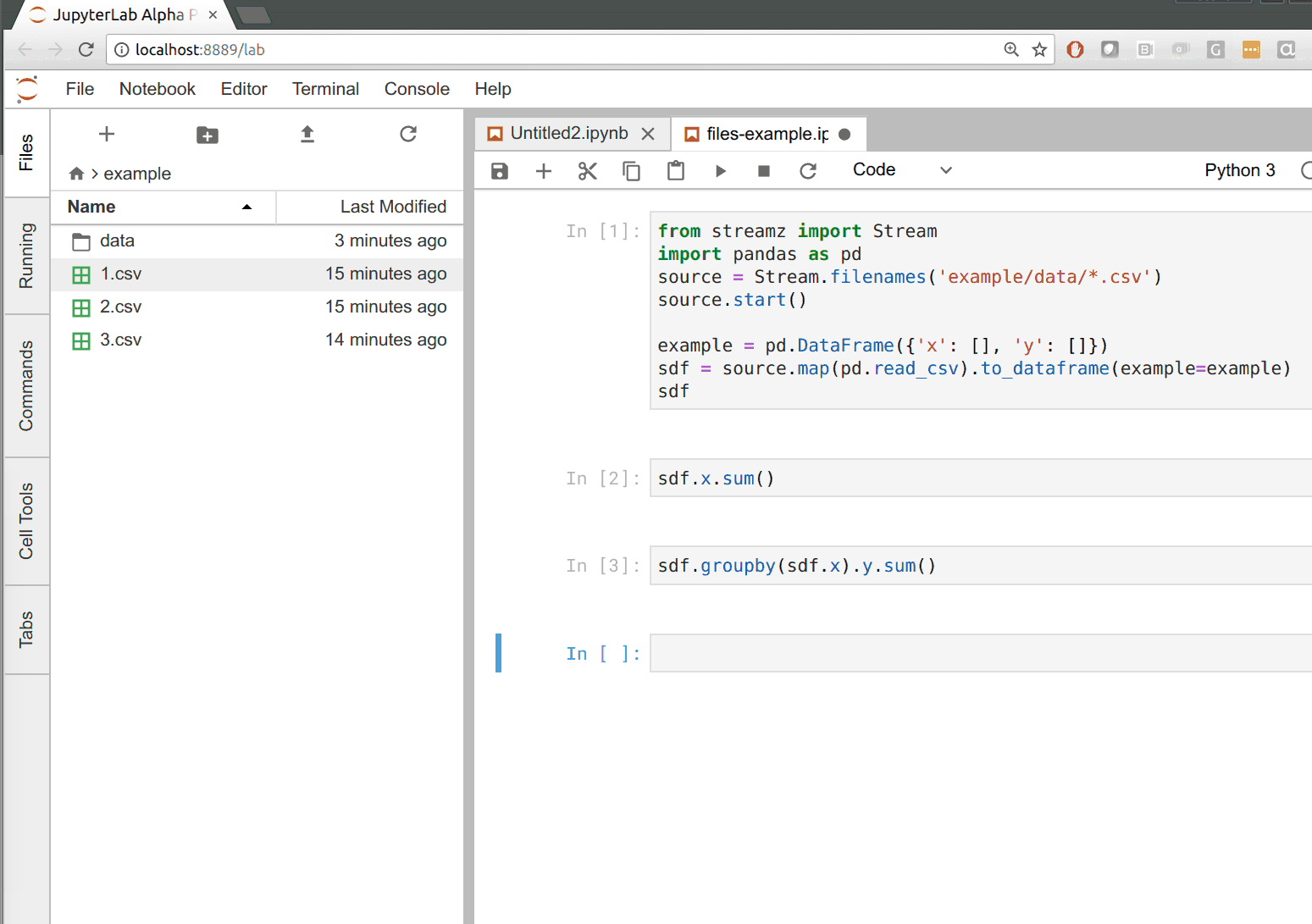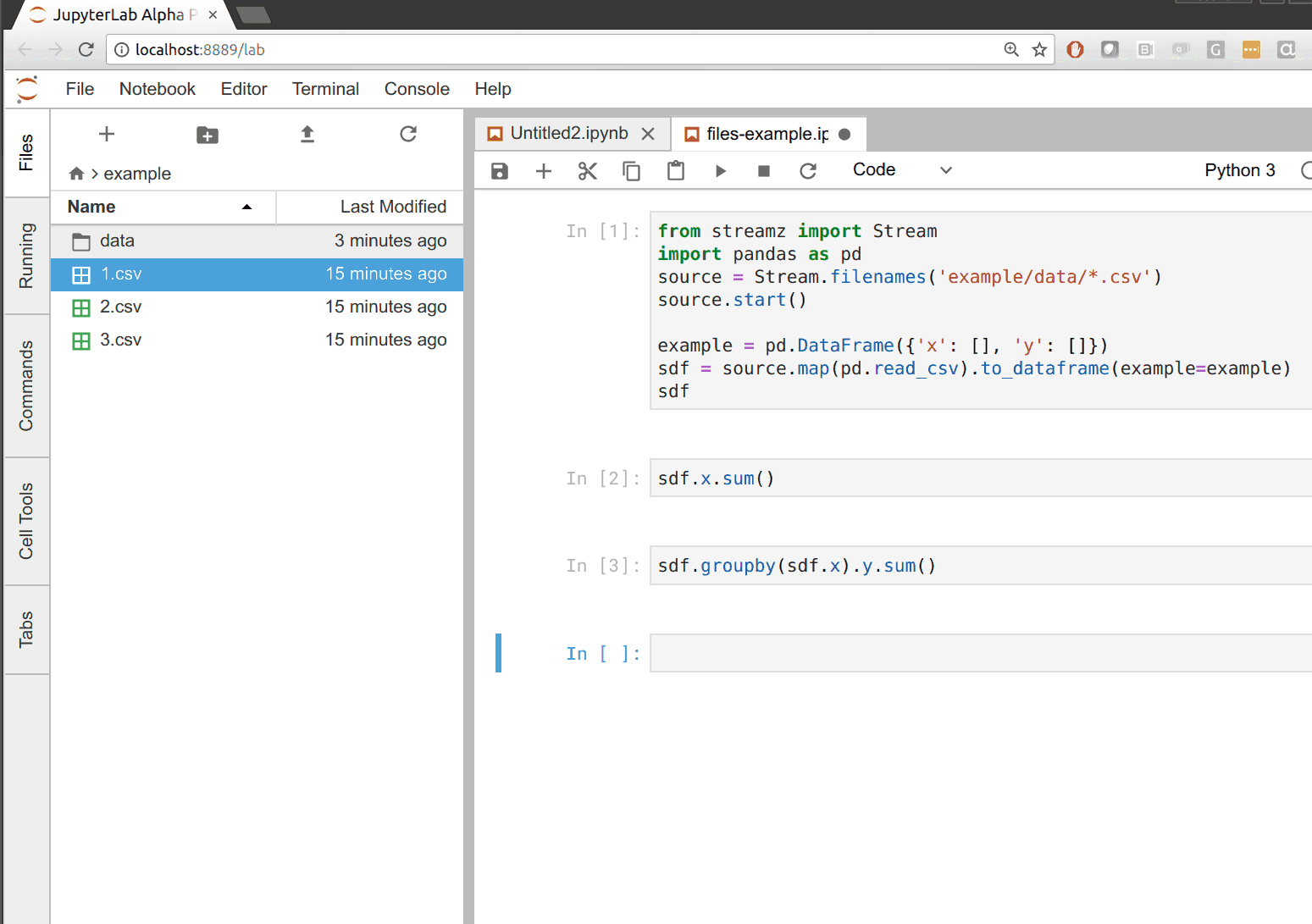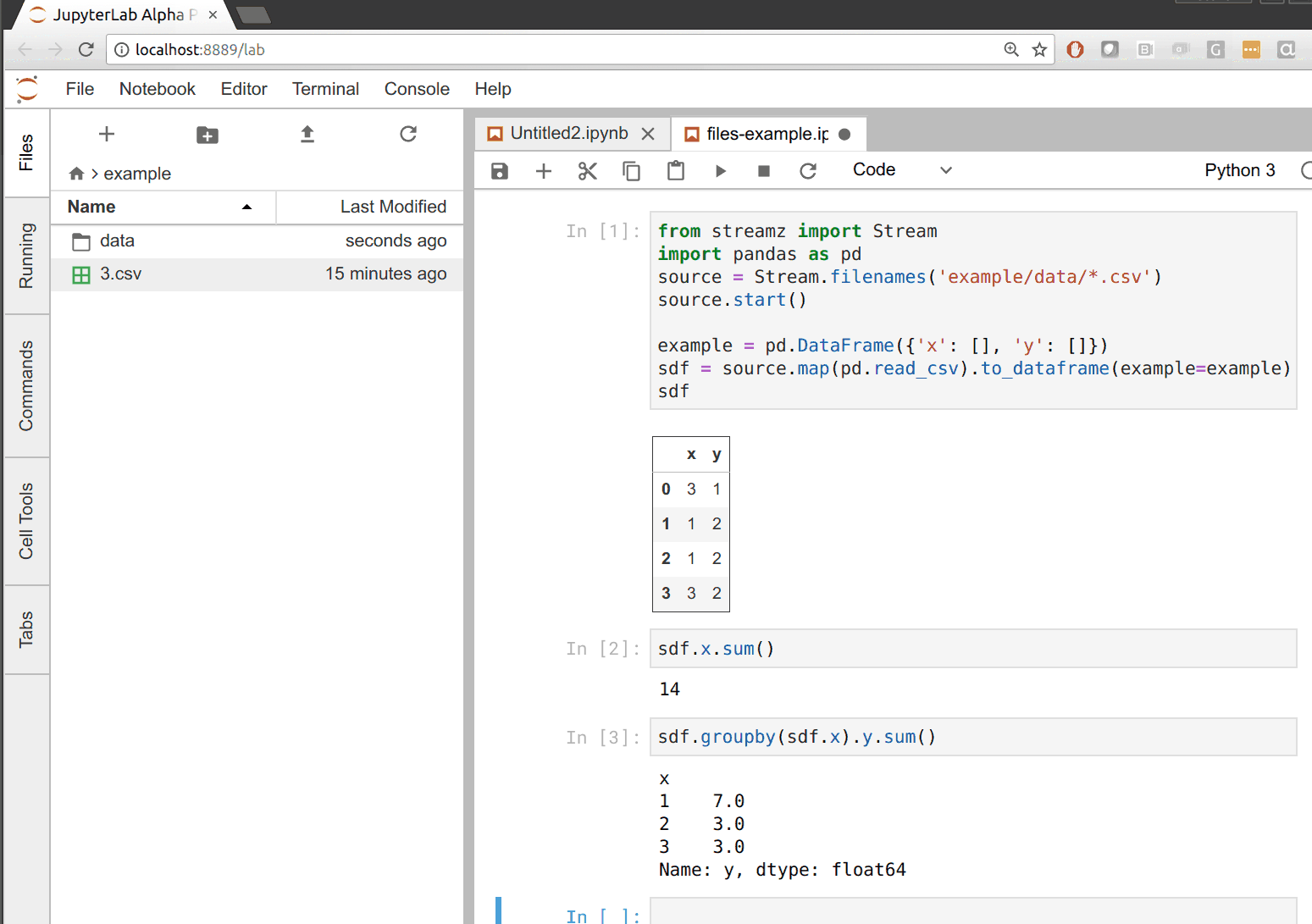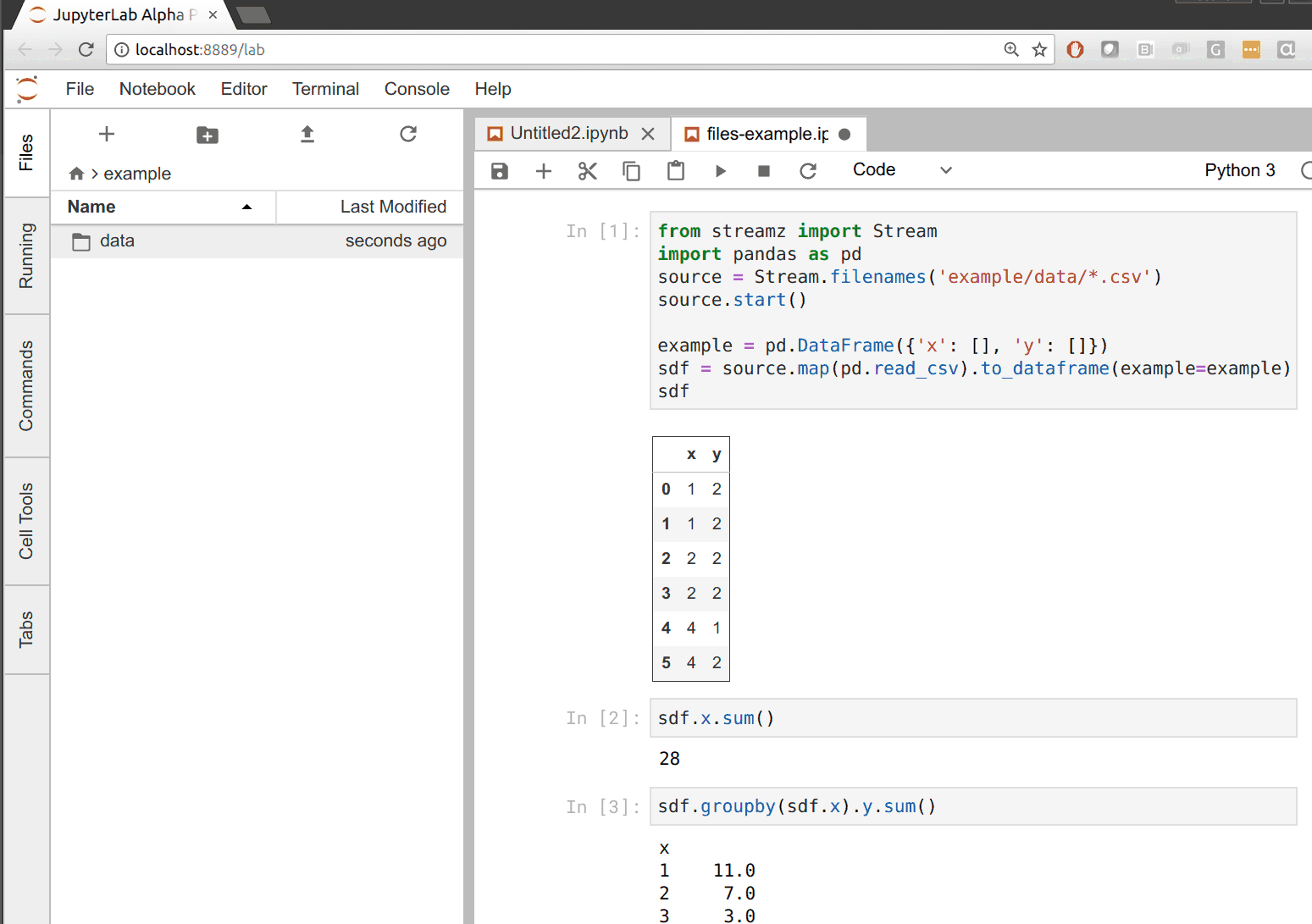
支持什么?
这个项目非常年轻,需要一些帮助。API 中有很多空白。尽管如此,以下功能运行良好
元素级操作
sdf['z'] = sdf.x + sdf.y
sdf = sdf[sdf.z > 2]
简单归约
sdf.sum()
sdf.x.mean()
Groupby 归约
sdf.groupby(sdf.x).y.mean()
按行数或时间窗口进行滚动归约
sdf.rolling(20).x.mean()
sdf.rolling('100ms').x.quantile(0.9)
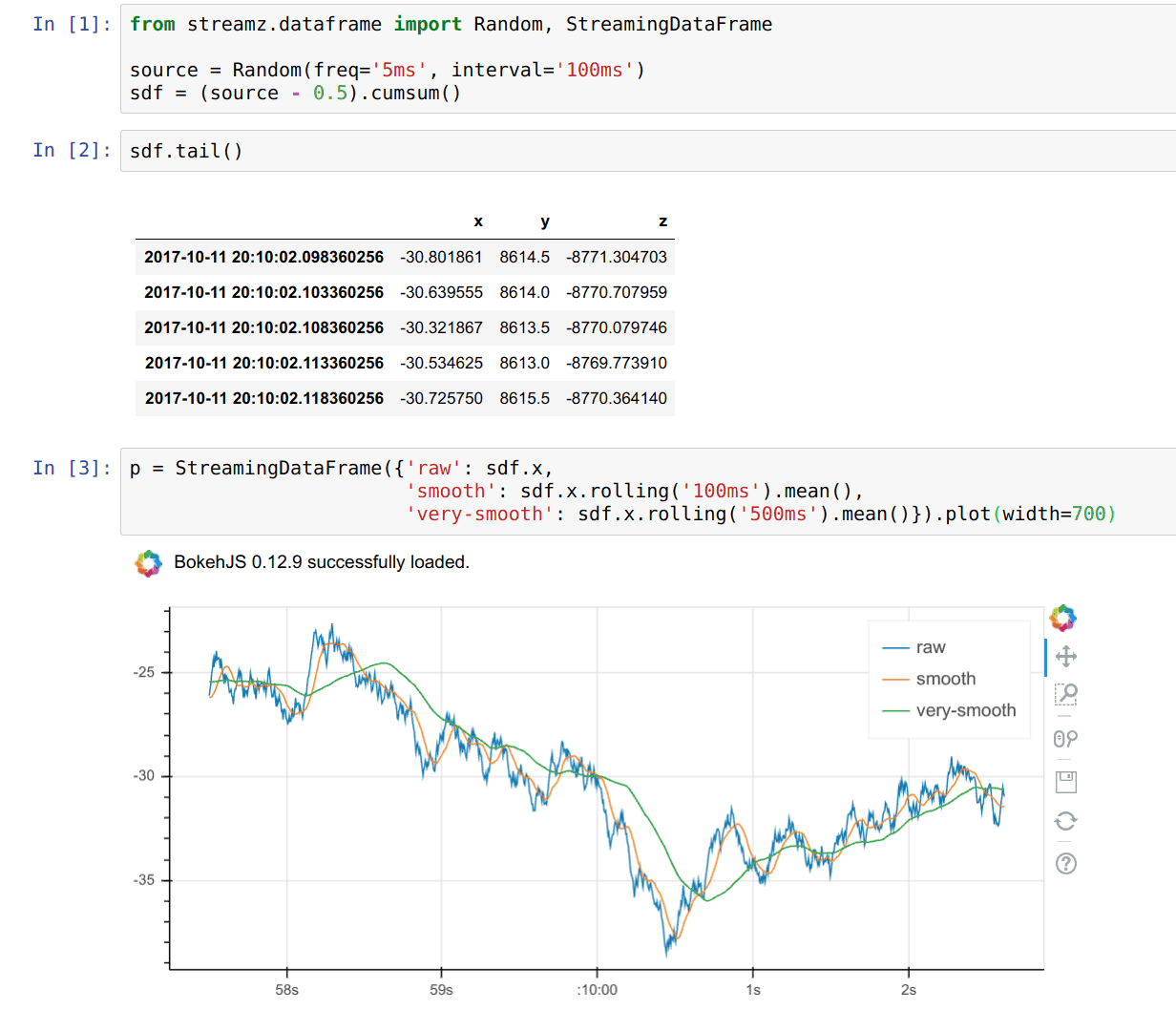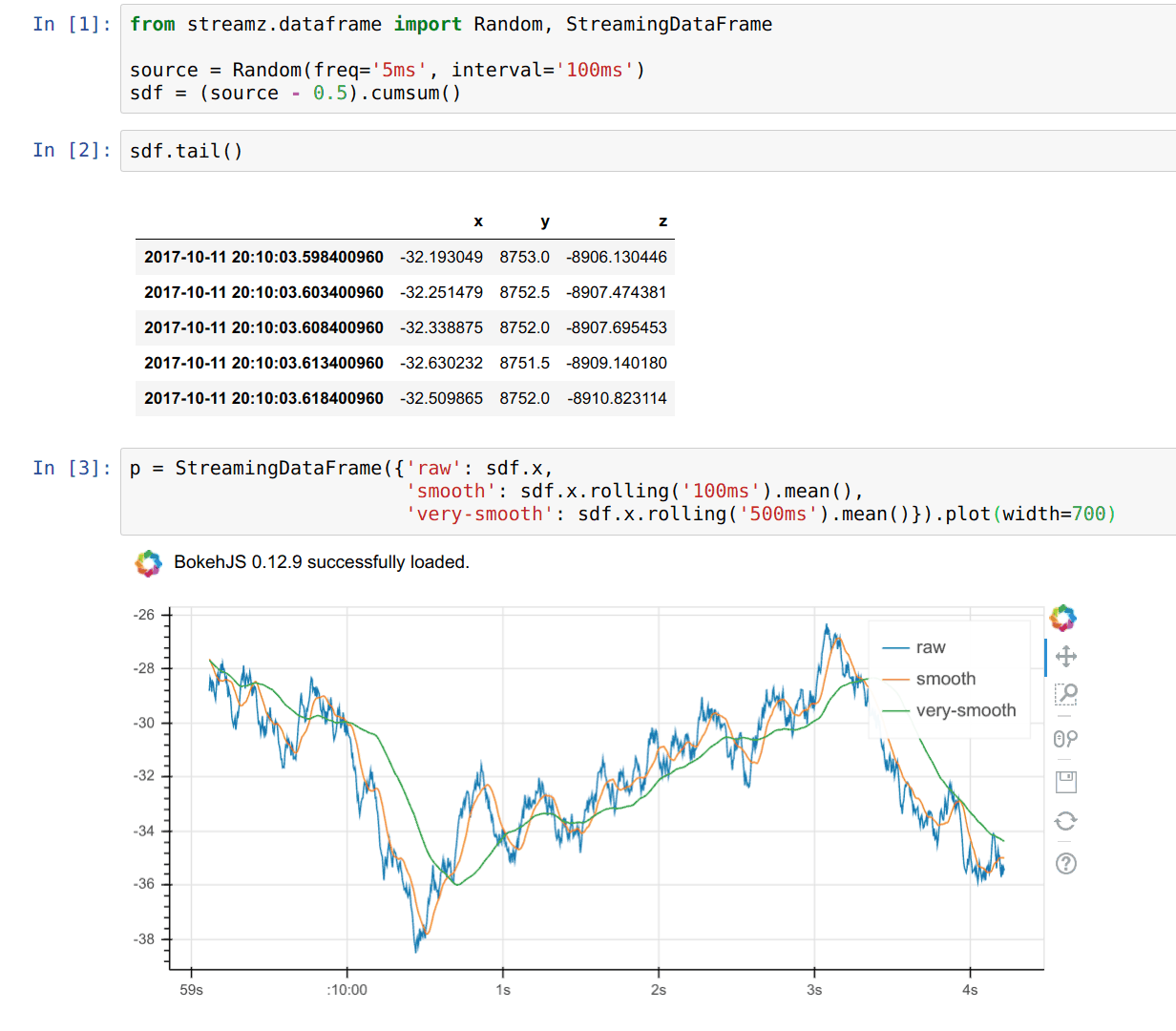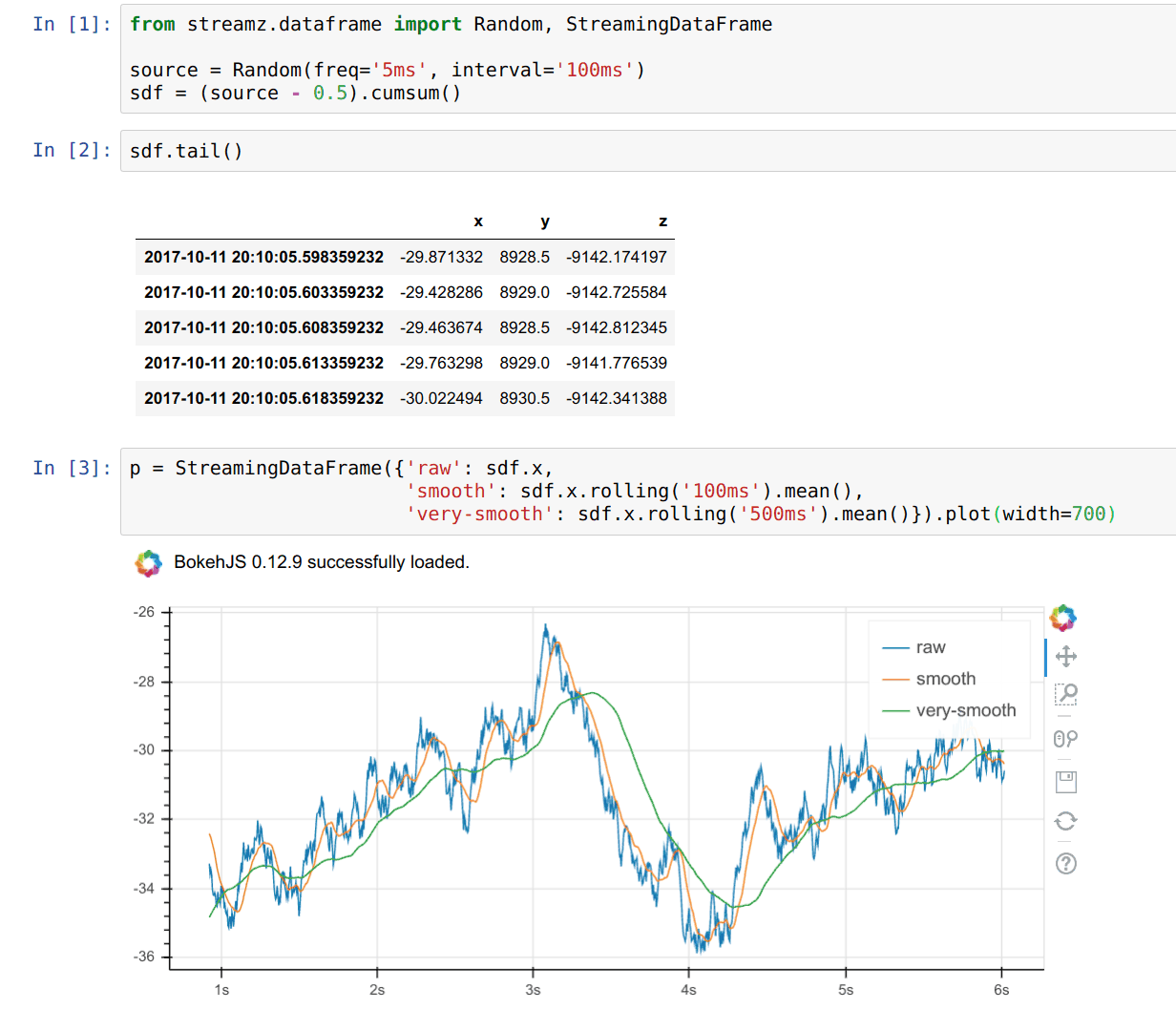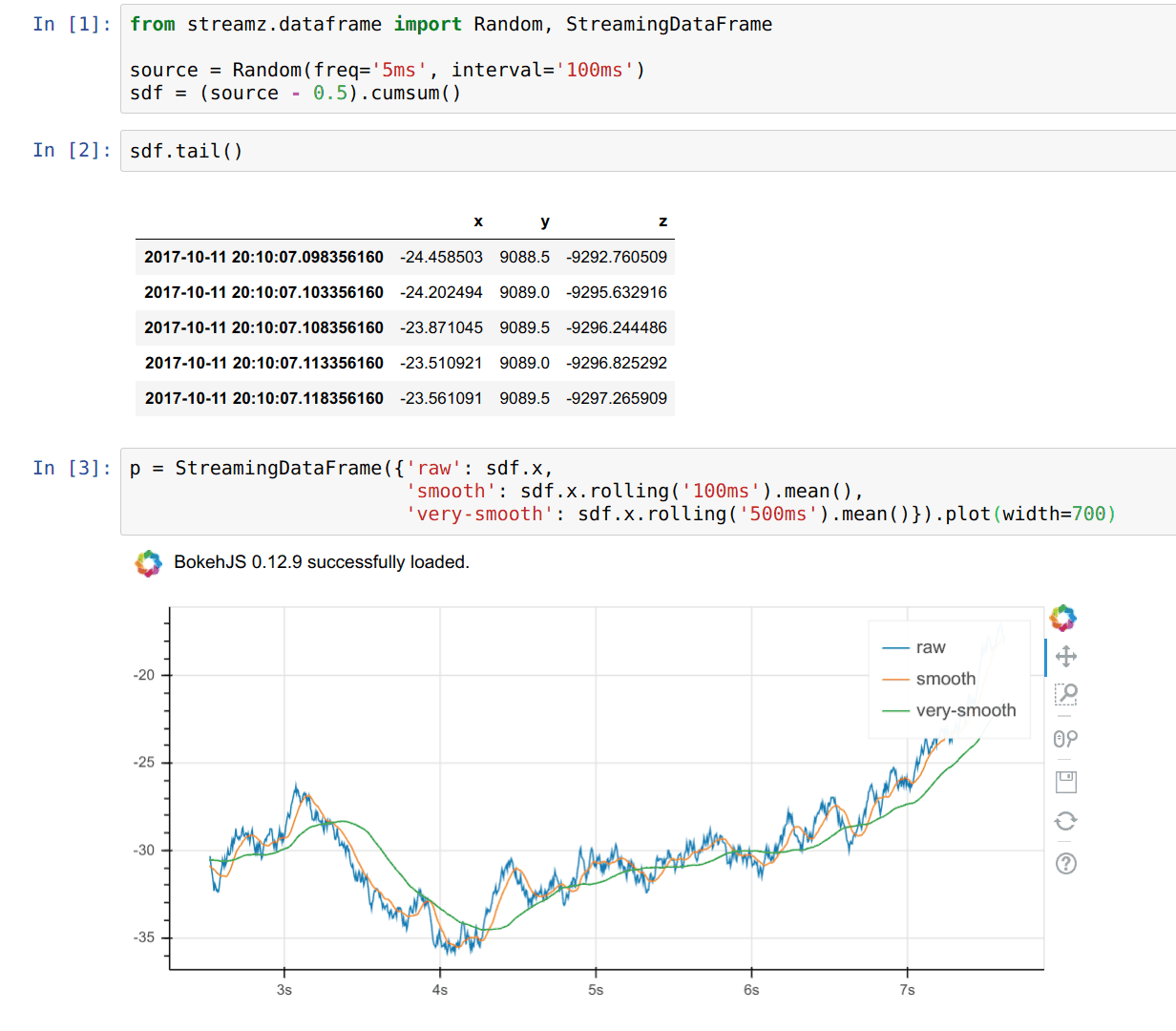
使用 Bokeh 进行实时绘图(我最喜欢的功能之一)
sdf.plot()
缺少什么?
- 并行计算:核心 streamz 库有一个可选的 Dask 后端用于并行计算。我还没有尝试将其连接到 dataframe 实现。
- 数据摄取:从常见的流式源(如 Kafka)摄取数据。我们目前正在构建围绕 Kafka Python 客户端库的异步感知包装器,因此这很可能很快就会实现。
- 乱序数据访问:并行数据摄取(例如同时从多个 Kafka 分区读取)后不久,我们需要弄清楚如何处理乱序数据访问。这是可行的,但需要一些努力。这是 Flink 等更成熟库的强项。
- 性能:上面的一些操作(特别是滚动操作)确实涉及大量的复制,尤其是在较大的窗口下。我们严重依赖 Pandas 库,该库并非为快速变化的数据而设计。希望 Pandas 的未来版本(Arrow/libpandas/Pandas 2.0?)能提高效率。
- 完整的 API:许多常见操作(如方差)尚未实现。一部分是因为懒惰,一部分是因为想找到正确的算法。
- 健壮的绘图:目前这对具有时间序列索引的数值数据效果很好,但对其他数据效果不佳。
但最重要的是,这需要有实际问题的人们来使用,以帮助我们了解这里有什么价值以及有什么不足之处。
欢迎就任何方面提供帮助。
你可以从 github 安装它
pip install git+https://github.com/mrocklin/streamz.git
文档和代码在这里
当前工作
当前和即将进行的工作重点是 Kafka 数据摄取和使用 Dask 进行并行化。
博客评论由 Disqus 提供支持