使用 Dask 进行信用建模 现实世界中的复杂任务图
作者:Richard Postelnik
本文探讨了一个现实世界的用例,即如何使用 Dask 在 Python 中计算复杂的信用模型。这是一个复杂的并行系统的示例,它远远超出了传统的“大数据”工作负载范围。
这是一篇客座文章
大家好,
这是一篇来自 Rich Postelnik 的客座文章,他是 Anaconda 的一名员工,与一家大型零售银行合作开发其信用建模系统。他们正在使用 Dask 进行一些有趣的工作来管理复杂的计算(见下面的任务图)。这是一个很好的例子,说明如何将 Dask 用于既不是大型数据框也不是大型数组,但仍然高度并行的复杂问题。Rich 非常友好地写下了他们的问题描述并在这里分享了它。
谢谢 Rich!

本文也发表在 Anaconda 开发者博客。
附注:如果其他人也有类似的解决方案并愿意分享,我也非常乐意将它们发布在此博客上。
问题
在申请贷款时,例如信用卡、抵押贷款、汽车贷款等,我们希望估计违约的可能性以及获得的利润(或损失)。这些模型由一组复杂的相互依赖的方程组成。可以有数百个方程,每个方程最多可以有 20 个输入并产生 20 个输出。需要跟踪的信息太多了!我们希望避免手动跟踪依赖关系,以及像下面这样混乱的 Python 函数代码
def final_equation(inputs):
out1 = equation1(inputs)
out2_1, out2_2, out2_3 = equation2(inputs, out1)
out3_1, out3_2 = equation3(out2_3, out1)
...
out_final = equation_n(inputs, out,...)
return out_final
这归结为一个被称为任务调度的依赖和排序问题。
DAG(有向无环图)来救援

有向无环图(DAG)通常用于解决任务调度问题。Dask 是一个用于延迟任务计算的库,其核心利用了有向图。dask.delayed 是一个简单的装饰器,它将一个 Python 函数变成一个图的顶点。如果我将一个延迟函数的输出作为参数传递给另一个延迟函数,Dask 就会在它们之间创建一个有向边。我们来看一个例子
def add(x, y):
return x + y
>>> add(2, 2)
4
所以这里我们有一个将两个数字相加的函数。让我们看看当我们用 dask.delayed 包装它时会发生什么
>>> add = dask.delayed(add)
>>> left = add(1, 1)
>>> left
Delayed('add-f6204fac-b067-40aa-9d6a-639fc719c3ce')
add 现在返回一个 Delayed 对象。我们可以将此对象作为参数传递回我们的 dask.delayed 函数,以开始构建计算链。
>>> right = add(1, 1)
>>> four = add(left, right)
>>> four.compute()
4
>>> four.visualize()
在下面我们可以看到 DAG 如何开始组合起来。
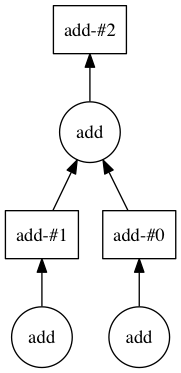
模拟信用示例
假设我是一家抵押贷款银行,有 10 个人申请抵押贷款。我想根据信用历史年限和收入来估计这组人的平均违约可能性。
hist_yrs = range(10)
incomes = range(10)
我们还假设违约是增量历史年限和一半经验年限的函数。虽然可以像这样编写代码
def default(hist, income):
return (hist + 1) ** 2 + (income / 2)
我知道将来我需要增量历史来进行另一个计算,并且希望能够重用代码并避免重复计算。因此,我可以将这些函数拆分出来
from dask import delayed
@delayed
def increment(x):
return x + 1
@delayed
def halve(y):
return y / 2
@delayed
def default(hist, income):
return hist**2 + income
请注意我是如何用 delayed 包装这些函数的。现在这些函数不再返回数字,而是返回一个 Delayed 对象。更好的是,这些函数还可以接受 Delayed 对象作为输入。正是这种将 Delayed 对象作为输入传递给其他 delayed 函数的方式,使得 Dask 能够构建任务图。现在我可以像正常的 Python 代码一样对我的数据调用这些函数了
inc_hist = [increment(n) for n in hist_yrs]
halved_income = [halve(n) for n in income]
estimated_default = [default(hist, income) for hist, income in zip(inc_hist, halved_income)]
如果你查看这些变量,你会发现实际上还没有计算任何东西。它们都是 Delayed 对象的列表。
现在,要获得平均值,我可以简单地计算 estimated_default 的总和,但我希望它能够扩展(并绘制一个更有趣的图),所以我们采用合并式的归约。
@delayed
def agg(x, y):
return x + y
def merge(seq):
if len(seq) < 2:
return seq
middle = len(seq)//2
left = merge(seq[:middle])
right = merge(seq[middle:])
if not right:
return left
return [agg(left[0], right[0])]
default_sum = merge(estimated_defaults)
此时,default_sum 是一个长度为 1 的列表,其第一个元素是所有申请人估计违约的总和。要获得平均值,我们将总和除以申请人数量,并调用 compute
avg_default = default_sum[0] / 10
avg_default.compute() # 40.75
要查看 Dask 将使用的计算图,我们调用 visualize
avg_default.visualize()
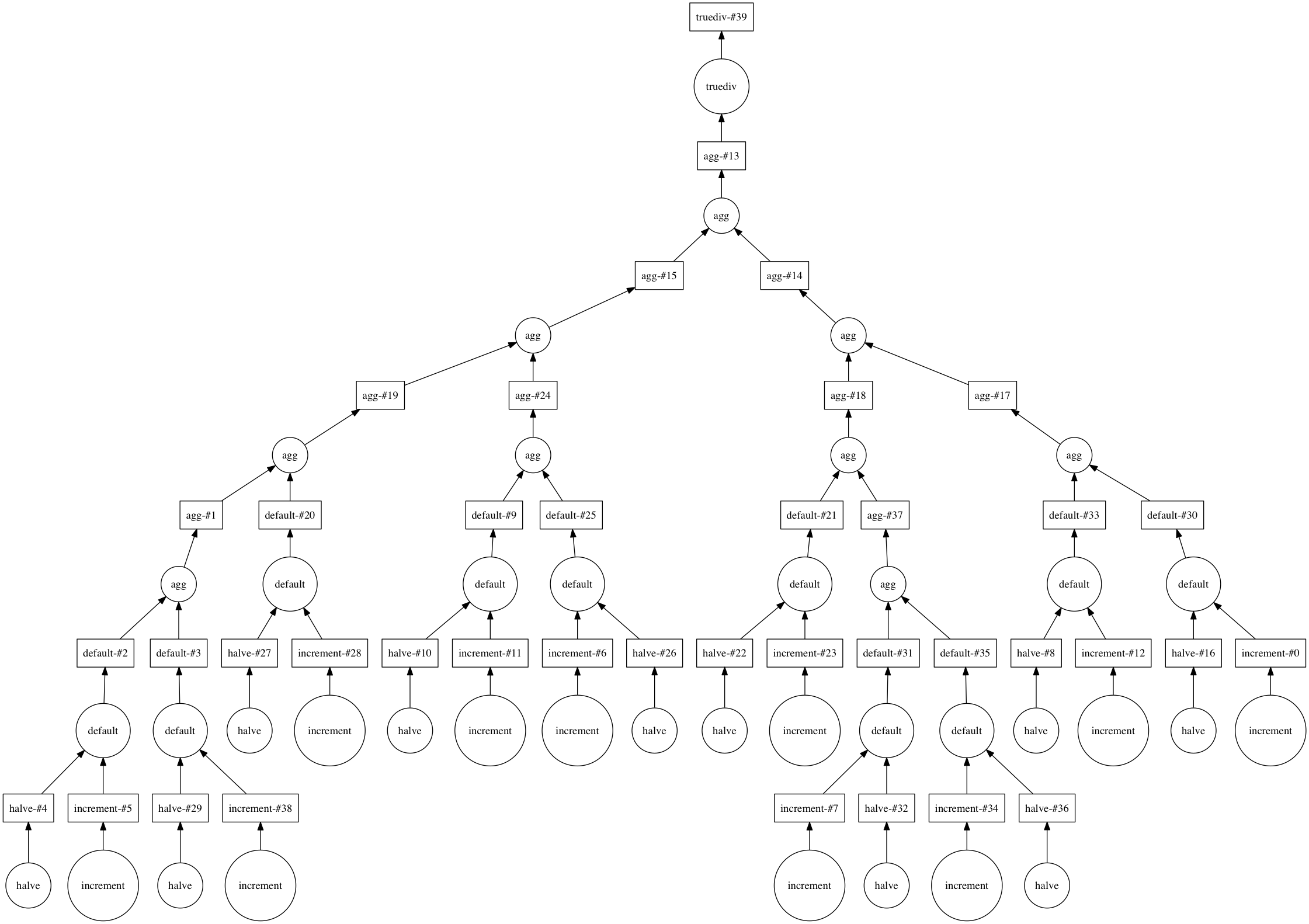
这就是如何使用 Dask 构建一个具有可重用中间计算的复杂方程系统。
我们在实践中如何使用 Dask
对于我们的信用建模问题,我们使用 Dask 构建了一个自定义数据结构来表示各个方程。使用上面默认的示例,它看起来像这样
class Default(Equation):
inputs = ['inc_hist', 'halved_income']
outputs = ['defaults']
@delayed
def equation(self, inc_hist, halved_income, **kwargs):
return inc_hist**2 + halved_income
这使我们能够将每个方程编写为一个独立的函数,并标记其输入和输出。有了这组方程对象,我们可以确定计算的顺序(使用拓扑排序),并让 Dask 处理图的生成和计算。这消除了在代码库中手动传递参数的繁琐任务。下面是银行实际使用的某个特定模型的任务图示例。

这个图有点太大,无法用常规的 my_task.visualize() 方法渲染,所以我们改用 Gephi 渲染了上面这个漂亮的彩色图。这个图的混沌上部区域是各个方程的计算。放大后我们可以看到入口点,即我们的输入 pandas DataFrame,它是顶部的那个大橙色圆圈,以及它如何输入到许多方程中。
模型的输出大小约为输入的 100 倍,因此我们在最后通过树归约进行了一些聚合。这构成了图的结构更清晰的下半部分。底部的那个大绿色节点是我们的最终输出。

最后思考
通过我们基于 Dask 的数据结构,我们将更多时间花在编写模型代码上,而不是维护引擎本身。这使得设计和编写模型的分析师与运行模型的计算系统之间实现了清晰的分离。Dask 还提供了许多上面未涉及的优点。例如,使用 Dask,您还可以访问诸如每个任务运行时间和使用的资源等诊断信息。此外,您可以相对轻松地使用dask distributed 分布计算。现在,如果我想在大于内存的数据或分布式集群上运行模型,我们不必担心重写代码来集成像 Spark 这样的东西。最后,Dask 允许您通过dask dataframe 让能够使用 pandas 的业务分析师或技术水平较低的人员访问大型数据集。
完整示例
from dask import delayed
@delayed
def increment(x):
return x + 1
@delayed
def halve(y):
return y / 2
@delayed
def default(hist, income):
return hist**2 + income
@delayed
def agg(x, y):
return x + y
def merge(seq):
if len(seq) < 2:
return seq
middle = len(seq)//2
left = merge(seq[:middle])
right = merge(seq[middle:])
if not right:
return left
return [agg(left[0], right[0])]
hist_yrs = range(10)
incomes = range(10)
inc_hist = [increment(n) for n in hist_yrs]
halved_income = [halve(n) for n in incomes]
estimated_defaults = [default(hist, income) for hist, income in zip(inc_hist, halved_income)]
default_sum = merge(estimated_defaults)
avg_default = default_sum[0] / 10
avg_default.compute()
avg_default.visualize() # requires graphviz and python-graphviz to be installed
致谢
特别感谢 Matt Rocklin、Michael Grant、Gus Cavanagh 和 Rory Merritt 在撰写本文时提供的反馈。
博客评论由 Disqus 提供支持