Pickle 不慢,它是一种协议
这项工作由 Anaconda Inc 提供支持
太长不看: Pickle 不慢,它是一种协议。协议对于生态系统很重要。
最近的一个 Dask 问题显示,将 Dask 与 PyTorch 一起使用很慢,因为在 Dask Worker 之间发送 PyTorch 模型耗时很长(Dask GitHub 问题)。
事实证明,这是因为使用 pickle 序列化 PyTorch 模型非常慢(基于 GPU 的模型为 1 MB/s,基于 CPU 的模型为 50 MB/s)。从架构上看,没有理由必须这么慢。硬件管道的每个部分都比这快得多。
我们本可以通过为 PyTorch 模型添加特殊处理来解决 Dask 中的这个问题(Dask 有自己的可选序列化系统用于提升性能),但作为良好的生态系统公民,我们决定在上游的一个问题中提出这个性能问题(PyTorch Github 问题)。这促成了一个对 PyTorch 的五行代码修复,将 1-50 MB/s 的序列化带宽转变为 1 GB/s 的带宽,这对于许多用例来说已经足够快了(提交到 PyTorch 的 PR)。
def __reduce__(self):
- return type(self), (self.tolist(),)
+ b = io.BytesIO()
+ torch.save(self, b)
+ return (_load_from_bytes, (b.getvalue(),))
+def _load_from_bytes(b):
+ return torch.load(io.BytesIO(b))
感谢 PyTorch 的维护者,这个问题很容易就解决了。PyTorch 的张量和模型现在可以在 Dask 或在 任何其他 Python 库 中高效地序列化,这些库可能希望在 PySpark、IPython parallel、Ray 或其他任何分布式系统中使用它们,而无需添加特殊处理代码或做任何特殊的事情。我们没有解决 Dask 的问题,我们解决了一个生态系统问题。
然而,在我们解决这个问题之前,我们讨论了一些事情。这条评论给我留下了深刻的印象
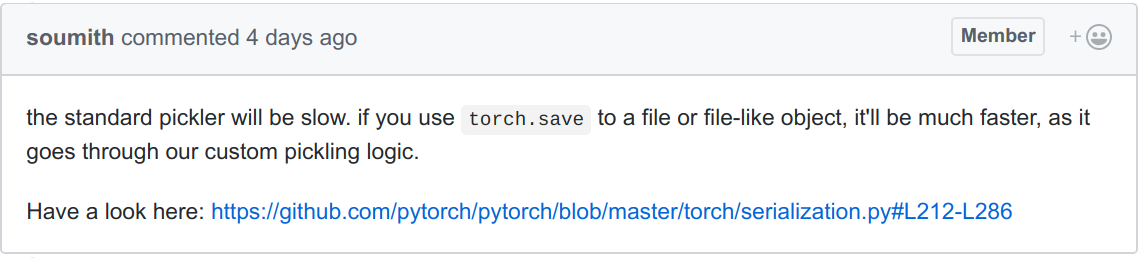
这条评论包含了两个非常普遍且在我看来有些事与愿违的观点
- Pickle 很慢
- 你应该使用我们专有的方法
我在这里有点在批评 PyTorch 的维护者(抱歉!),但我发现这些观点非常普遍,所以我想在这里谈谈它们。
Pickle 很慢
Pickle 不慢。Pickle 是一种协议。我们实现了 pickle。如果它慢,那是我们的错,不是 Pickle 的错。
需要明确的是,有很多理由不使用 Pickle。
- 它不是跨语言的
- 它不太容易解析
- 它不提供随机访问
- 它不安全
- 等等。
所以你不应该使用 Pickle 存储数据或创建公共服务,但对于像在网络上传输数据这样的事情,如果你在受信任且统一的环境中严格地在 Python 进程之间传输数据,它是一个很好的默认选择。
它很棒,因为它可以做到像内存复制一样快,并且生态系统中的其他库无需对你的代码进行特殊处理即可使用它。
这就是我们为 PyTorch 所做的改变。
def __reduce__(self):
- return type(self), (self.tolist(),)
+ b = io.BytesIO()
+ torch.save(self, b)
+ return (_load_from_bytes, (b.getvalue(),))
+def _load_from_bytes(b):
+ return torch.load(io.BytesIO(b))
慢的部分不是 Pickle,而是在 __reduce__ 中的 .tolist() 调用,它将 PyTorch 张量转换为 Python 整数和浮点数的列表。我怀疑“Pickle 就是慢”这个普遍的观点阻止了其他人调查这里的性能问题。我很惊讶像 PyTorch 这样活跃且维护良好的项目竟然还没有修复这个问题。
提醒一下,你可以通过在你的类上提供 __reduce__ 方法来实现 pickle 协议。__reduce__ 函数返回一个加载函数和足够的参数来重构你的对象。在这里,我们使用了 torch 现有的 save/load 函数来创建一个我们可以传递的 bytestring。
只使用我们专有的选项
专有的选项可能很棒。它们可以有带有许多选项的良好 API,如果存在(例如 RDMA 或 NVLink)专用的通信硬件,它们可以自行调整以适应,等等。但人们需要先了解它们,而了解它们可能有两个难点。
对用户来说困难
如今我们使用大量快速变化的库。用户很难成为所有这些库的专家。我们越来越依赖新库通过遵守标准 API、提供有用的错误消息以引导正确行为等方式来简化我们的使用。
对其他库来说困难
需要交互的其他库 肯定 不会阅读文档,即使读了,让每个库都为其他每个库喜欢的方法进行特殊处理以将对象转换为字节也是不合理的。库的生态系统在很大程度上依赖于协议的存在以及围绕一致且高效地实现这些协议形成的强烈共识。
有时专有选项是合适的
确实有充分的理由支持专有选项。有时你需要超过 1GB/s 的带宽。虽然这种情况通常很少见(很少有流水线处理速度超过 1GB/s/节点),但在 PyTorch 在单机上使用多个进程进行并行训练的特定情况下,这却是事实。Soumith(PyTorch 维护者)写道:
通过多进程发送张量时,我们的自定义序列化器实际上是通过共享内存来快捷处理的,i.e. 它将底层 Storage 移动到共享内存,并在另一个进程中恢复张量以指向该共享内存。我们这样做是出于以下原因
-
速度:我们节省了内存复制,特别是如果我们分摊了在将张量发送到多进程队列之前将其移动到共享内存的成本。将张量从一个进程实际移动到另一个进程的总成本最终是 O(1),并且与张量的大小无关
-
共享:如果张量 A 和张量 B 是彼此的视图,一旦我们序列化并发送它们,我们希望保留它们是视图的这个属性。这对于神经网络至关重要,在神经网络中,重新查看权重/偏置并将其用于其他用途是很常见的。使用默认的 pickle 解决方案,这个属性实际上会丢失。
博客评论由 Disqus 提供支持