Dask 开发日志
这项工作由 Anaconda Inc 提供支持
为了提高透明度,我尝试更频繁地撰写博客,介绍围绕 Dask 和相关项目正在进行的当前工作。这里没有什么准备好用于生产环境。这篇博文是匆忙写就的,所以请勿期待精细的润色。
过去两周,我们在以下领域看到了进展
- 一个用于有状态处理的实验性 Actor 解决方案
- 使用超参数选择和参数服务器进行的机器学习实验。
- 开发更多预处理转换器
- 分布式调度器内部事件循环线程的统计分析和内部优化
- dask-yarn 的新版本发布
- dask-stories 上关于移动网络建模的新叙事
- dask-jobqueue 中对 LSF 集群的支持
- 针对间歇性故障进行测试套件清理
使用 Actors 进行有状态处理
一些高级工作负载需要直接管理和修改工作节点上的状态。像 Dask 这样的基于任务的框架可以通过长时运行任务来应对这类工作负载,但这是一种不舒适的体验。为了解决这个问题,我们在 Dask 标准任务调度系统旁边增加了一个实验性的 Actors 框架。这提供了更低的延迟,消除了调度开销,并提供了直接修改工作节点上状态的能力,但会失去诸如弹性(resilience)和诊断(diagnostics)等优点。
采用 Actors 的想法是厚颜无耻地从 Ray Project 窃取的 :)
Actors 的工作正在 dask/distributed #2133 中进行。
class Counter:
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
return self.n
counter = client.submit(Counter, actor=True).result()
>>> future = counter.increment()
>>> future.result()
1
机器学习实验
对增量训练模型的超参数优化
许多 Scikit-Learn 风格的估计器都具有一个 partial_fit 方法,该方法支持对批量数据进行增量训练。这特别适合像 Dask array 或 Dask dataframe 这样的系统,它们由许多批次的 Numpy 数组或 Pandas dataframe 构建而成。这很契合,因为所有的计算算法工作已经在 Scikit-Learn 中完成,Dask 只需管理性地将模型移动到数据所在位置并调用 scikit-learn(或其他遵循 fit/transform/predict/score API 的机器学习模型)。这种方法为并行计算和机器学习开发者提供了一个良好的社区接口。
然而,这种训练本质上是顺序的,因为模型一次只能在一个批次的数据上进行训练。我们浪费了很多处理能力。
为了解决这个问题,我们可以将增量训练与超参数选择相结合,同时在相同的数据上训练多个模型。这通常也是需要的,并且可以让我们更有效地进行计算。
然而,使用超参数选择进行增量训练有许多方法,而且合适的算法可能取决于具体问题。这是一个活跃的研究领域,因此像 Dask 这样的通用项目很难选择和实现一个适合所有人的单一方法。可能需要几种方法,并带有各种选项。
为了帮助实验,我们一直在试验一些低级工具,我们认为这些工具在各种情况下都会有所帮助。这些工具接受用户提供的策略(一个 Python 函数),该函数获取最近评估的分数,并询问在再次检查之前,每个超参数集还需要进一步进行多少。这使我们能够轻松地模拟一些常见情况,例如带有早期停止条件的随机搜索、逐次减半(successive halving)以及这些方法的变体,而无需编写任何 Dask 代码
这项工作由 Scott Sievert 和我共同完成

参数服务器
为了提高大型模型的训练速度,Scott Sievert 一直在使用 Actors(上文提到)开发参数服务器的简单示例。这些示例有助于发现并推动 Dask 自身的性能和诊断改进。
这些参数服务器管理不同工作节点生成的模型之间的通信,并将计算留给底层的深度学习库。这项工作正在进行中。
Dataframe 预处理转换器
我们已经开始围绕案例研究来指导一些 Dask-ML 的工作。我们的第一个案例研究由 Scott Sievert 撰写,使用了用于广告的 Criteo 数据集。这是一个很好的结合了密集和稀疏数据的例子,数据量可能相当大(约 1TB)。我们遇到的第一个挑战是预处理。这带来了一些预处理改进:
- Label Encoder 支持 Pandas Categorical dask/dask-ml #310
- 添加 Imputer 支持均值和中位数策略 dask/dask-ml #11
- 添加 OneHotEncoder dask/dask-ml #313
- 添加 Hashing Vectorizer dask/dask-ml #122
- 添加 ColumnTransformer dask/dask-ml #315
其中一些改进也基于 Scikit-Learn 即将发布的 0.20 版本中改进的 dataframe 处理功能。
这项工作由 Roman Yurchak, James Bourbeau, Daniel Severo, 和 Tom Augspurger 完成。
对主线程进行分析
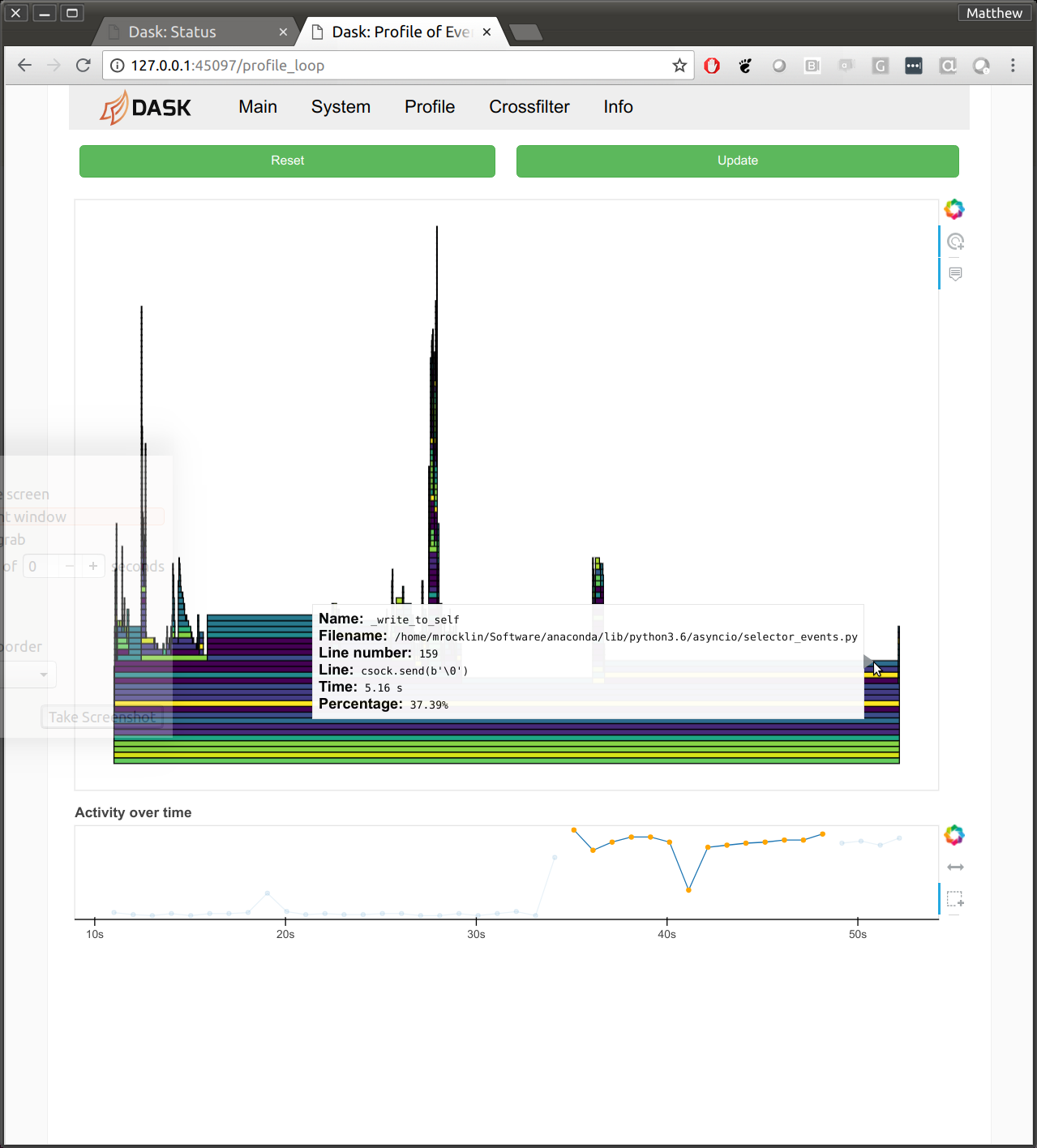
分析并发代码很困难。像 CProfile 这样的传统分析器会被不同协程之间传递控制权弄糊涂。这意味着我们对分布式调度器和工作节点的分析和调优工作做得不够全面。另一方面,统计分析器往往表现得更好一些。我们已经将通常用于 Dask 工作节点线程的统计分析器(可在仪表板的“Profile”选项卡中找到)应用到了运行 Tornado 事件循环的中央管理线程上。这突出了一些我们以前未能发现的问题,并有望在未来版本中减少开销。
- dask/distributed #2144
- stackoverflow.com/questions/51582394/which-functions-are-free-when-profiling-tornado-asyncio
Dask-Yarn 新版本发布
Dask-Yarn 及其用于管理 Yarn 作业的底层库 Skein 发布了新版本。这些版本包含了一些错误修复和改进的 YARN 应用程序并发原语。新功能文档可在此处查看,并在 jcrist/skein #40 中实现。
这项工作由 Jim Crist 完成
Dask-Jobqueue 中对 LSF 集群的支持
Dask-jobqueue 支持在 SGE, SLURM, PBS 等传统 HPC 集群管理器上使用 Dask。我们最近添加了对 LSF 集群的支持
这项工作由 Ray Bell 在 dask/dask-jobqueue #78 中完成。
新的 Dask 故事:移动网络建模
Dask Stories 仓库收录了关于人们如何使用 Dask 的叙事。 Sameer Lalwani 最近添加了一个关于使用 Dask 建模移动通信网络的故事。值得一读。
测试套件清理
dask.distributed 测试套件最近一直遭受间歇性故障的困扰。这些测试失败的频率非常低,因此在编写时很难发现,但在未来的无关 PR 在持续集成上运行测试套件时就会出现故障。它们增加了开发过程的摩擦,但追踪起来成本很高(测试分布式系统很困难)。
本周我们花了一些时间来追踪这些问题。进展如下
博客评论由 Disqus 驱动