构建用于 Dask 数组的 SAGA 优化
这项工作由 ETH Zurich、Anaconda Inc 和 Berkeley Institute for Data Science 支持
最近在 BIDS 举办的 Scikit-learn/Scikit-image/Dask 冲刺活动中,Fabian Pedregosa(机器学习研究员和 Scikit-learn 开发者)与 Matthew Rocklin(Dask 核心开发者)坐在一起,共同开发了用于并行 Dask 数据集的增量优化算法 SAGA 的实现。结果是得到了一个可以在任何 Dask 数组上运行的顺序算法,因此数据可以存储在磁盘上,甚至可以分布在不同的机器之间。
了解该算法的性能以及在 Dask 分布式数据集上运行研究算法的便利性和挑战,都很有趣。
开始
我们从 Fabian 使用 Numba 为 Numpy 数组编写的初始实现开始。以下代码解决形式如下的优化问题:
\[min_x \sum_{i=1}^n f(a_i^t x, b_i)\]import numpy as np
from numba import njit
from sklearn.linear_model.sag import get_auto_step_size
from sklearn.utils.extmath import row_norms
@njit
def deriv_logistic(p, y):
# derivative of logistic loss
# same as in lightning (with minus sign)
p *= y
if p > 0:
phi = 1. / (1 + np.exp(-p))
else:
exp_t = np.exp(p)
phi = exp_t / (1. + exp_t)
return (phi - 1) * y
@njit
def SAGA(A, b, step_size, max_iter=100):
"""
SAGA algorithm
A : n_samples x n_features numpy array
b : n_samples numpy array with values -1 or 1
"""
n_samples, n_features = A.shape
memory_gradient = np.zeros(n_samples)
gradient_average = np.zeros(n_features)
x = np.zeros(n_features) # vector of coefficients
step_size = 0.3 * get_auto_step_size(row_norms(A, squared=True).max(), 0, 'log', False)
for _ in range(max_iter):
# sample randomly
idx = np.arange(memory_gradient.size)
np.random.shuffle(idx)
# .. inner iteration ..
for i in idx:
grad_i = deriv_logistic(np.dot(x, A[i]), b[i])
# .. update coefficients ..
delta = (grad_i - memory_gradient[i]) * A[i]
x -= step_size * (delta + gradient_average)
# .. update memory terms ..
gradient_average += (grad_i - memory_gradient[i]) * A[i] / n_samples
memory_gradient[i] = grad_i
# monitor convergence
print('gradient norm:', np.linalg.norm(gradient_average))
return x
这个实现是 Fabian 在研究中经常使用的 SAGA 实现的简化版本,并且假设 $f$ 是对数损失,即 $f(z) = \log(1 + \exp(-z))$。通过覆盖函数 deriv_logistic,它也可以用于解决使用其他 $f$ 值的优化问题。
我们希望将其应用于并行 Dask 数组,通过一次一个地将其应用于 Dask 数组的每个块(较小的 Numpy 数组),并在此过程中携带一组参数。
开发过程
为了更好地理解编写 Dask 算法的挑战,Fabian 承担了大部分实际的初始编码工作。Fabian 是一个很好的例子,他是一名研究人员,知道如何出色地编程和设计机器学习算法,但没有直接接触过 Dask 库。这对 Fabian 和 Matt 来说都是一个教育机会。Fabian 学习了如何使用 Dask,而 Matt 学习了如何向像 Fabian 这样的研究人员介绍 Dask。
步骤 1:构建使用纯函数的顺序算法
起初我们实际上根本没有使用 Dask,而是 Fabian 通过几种方式修改了他的实现:
- 它应该操作一个 Numpy 数组列表。Numpy 数组列表类似于 Dask 数组,但更简单。
- 它应该将逻辑块分离到不同的函数中,这些函数最终将成为任务,所以它们应该是相当大的工作块。在这种情况下,这导致创建了函数
_chunk_saga,该函数在数据子集上执行 SAGA 算法的一次迭代。 - 这些函数不应修改其输入,也不应依赖全局状态。这些函数需要的所有信息(例如我们在算法中学习的参数)都应该显式地作为输入提供。
这些修改请求对性能有些影响,我们最终会创建更多参数副本和更多中间状态副本。从编程难度来看,这花了一些时间(大约几个小时),但这是一个直接的任务,Fabian 似乎没有觉得有挑战或陌生。
这些变化导致了以下代码
from numba import njit
from sklearn.utils.extmath import row_norms
from sklearn.linear_model.sag import get_auto_step_size
@njit
def _chunk_saga(A, b, n_samples, f_deriv, x, memory_gradient, gradient_average, step_size):
# Make explicit copies of inputs
x = x.copy()
gradient_average = gradient_average.copy()
memory_gradient = memory_gradient.copy()
# Sample randomly
idx = np.arange(memory_gradient.size)
np.random.shuffle(idx)
# .. inner iteration ..
for i in idx:
grad_i = f_deriv(np.dot(x, A[i]), b[i])
# .. update coefficients ..
delta = (grad_i - memory_gradient[i]) * A[i]
x -= step_size * (delta + gradient_average)
# .. update memory terms ..
gradient_average += (grad_i - memory_gradient[i]) * A[i] / n_samples
memory_gradient[i] = grad_i
return x, memory_gradient, gradient_average
def full_saga(data, max_iter=100, callback=None):
"""
data: list of (A, b), where A is a n_samples x n_features
numpy array and b is a n_samples numpy array
"""
n_samples = 0
for A, b in data:
n_samples += A.shape[0]
n_features = data[0][0].shape[1]
memory_gradients = [np.zeros(A.shape[0]) for (A, b) in data]
gradient_average = np.zeros(n_features)
x = np.zeros(n_features)
steps = [get_auto_step_size(row_norms(A, squared=True).max(), 0, 'log', False) for (A, b) in data]
step_size = 0.3 * np.min(steps)
for _ in range(max_iter):
for i, (A, b) in enumerate(data):
x, memory_gradients[i], gradient_average = _chunk_saga(
A, b, n_samples, deriv_logistic, x, memory_gradients[i],
gradient_average, step_size)
if callback is not None:
print(callback(x, data))
return x
步骤 2:应用 dask.delayed
一旦函数既不修改其输入也不依赖全局状态,我们学习了一个 dask.delayed 示例,然后将 @dask.delayed 装饰器应用于 Fabian 编写的函数。Fabian 第一次这样做只花了大约五分钟,令我们双方都感到惊讶的是,事情竟然成功了!
@dask.delayed(nout=3) # <<<---- New
@njit
def _chunk_saga(A, b, n_samples, f_deriv, x, memory_gradient, gradient_average, step_size):
...
def full_saga(data, max_iter=100, callback=None):
n_samples = 0
for A, b in data:
n_samples += A.shape[0]
data = dask.persist(*data) # <<<---- New
...
for _ in range(max_iter):
for i, (A, b) in enumerate(data):
x, memory_gradients[i], gradient_average = _chunk_saga(
A, b, n_samples, deriv_logistic, x, memory_gradients[i],
gradient_average, step_size)
cb = dask.delayed(callback)(x, data) # <<<---- Changed
x, cb = dask.persist(x, cb) # <<<---- New
print(cb.compute()
然而,它们的表现并没有那么好。当我们查看 Dask 面板时,我们发现存在大量的空闲空间(dead space),这表明我们仍然在客户端进行了大量计算。
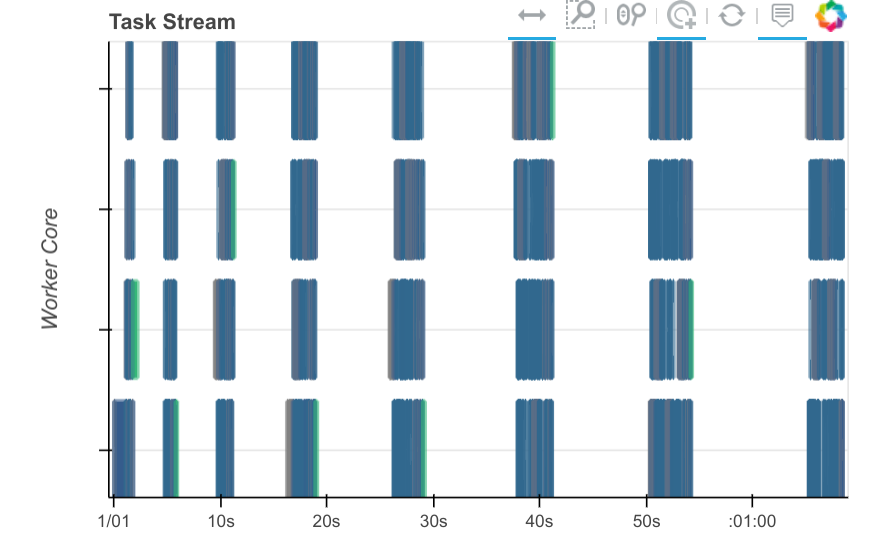
步骤 3:诊断并添加更多 dask.delayed 调用
虽然事情成功了,但速度也相当慢。如果您注意到上面的面板图,您会看到彩色矩形之间有大量的空白。这表明有很长一段时间没有任何工作节点(worker)在工作。
这是工作节点(worker)(显示在面板上)和客户端之间混合工作的一种常见迹象。解决这个问题的方法通常是更有针对性地使用 dask.delayed。Dask delayed 入门很容易,但要用好需要一些经验。重要的是要跟踪哪些操作和变量是延迟的,哪些不是。在它们之间混合使用会产生一些开销。
在这一点上,Matt 介入并在更多地方添加了 delayed,面板图开始看起来更清晰了。
@dask.delayed(nout=3) # <<<---- New
@njit
def _chunk_saga(A, b, n_samples, f_deriv, x, memory_gradient, gradient_average, step_size):
...
def full_saga(data, max_iter=100, callback=None):
n_samples = 0
for A, b in data:
n_samples += A.shape[0]
n_features = data[0][0].shape[1]
data = dask.persist(*data) # <<<---- New
memory_gradients = [dask.delayed(np.zeros)(A.shape[0])
for (A, b) in data] # <<<---- Changed
gradient_average = dask.delayed(np.zeros)(n_features) # Changed
x = dask.delayed(np.zeros)(n_features) # <<<---- Changed
steps = [dask.delayed(get_auto_step_size)(
dask.delayed(row_norms)(A, squared=True).max(),
0, 'log', False)
for (A, b) in data] # <<<---- Changed
step_size = 0.3 * dask.delayed(np.min)(steps) # <<<---- Changed
for _ in range(max_iter):
for i, (A, b) in enumerate(data):
x, memory_gradients[i], gradient_average = _chunk_saga(
A, b, n_samples, deriv_logistic, x, memory_gradients[i],
gradient_average, step_size)
cb = dask.delayed(callback)(x, data) # <<<---- Changed
x, memory_gradients, gradient_average, step_size, cb = \
dask.persist(x, memory_gradients, gradient_average, step_size, cb) # New
print(cb.compute()) # <<<---- changed
return x
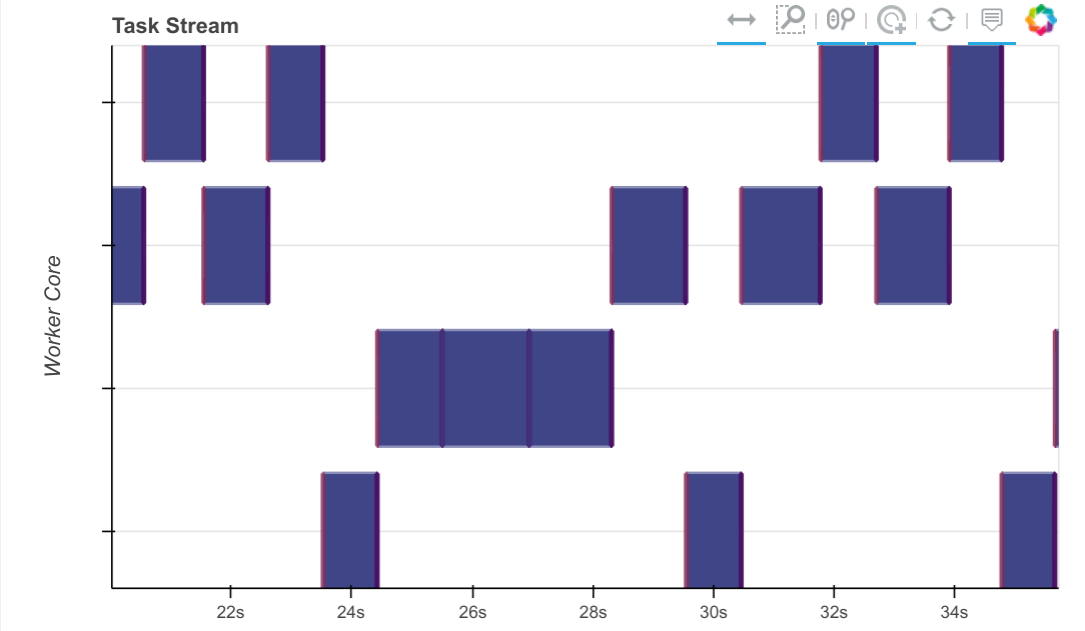
从 Dask 的角度来看,现在看起来不错了。我们看到在任何给定时间只有一个 partial_fit 调用处于活动状态,partial_fit 调用之间没有大的水平间隔。我们没有获得任何并行性(这只是一个顺序算法),但也没有太多空闲空间。模型似乎在不同的工作节点之间跳转,处理完一个数据块后移动到新的数据上。
步骤 4:性能分析
上面的面板图让我们相信我们的算法正在按预期运行。算法的块顺序特性清晰地体现出来,任务之间的间隔非常短。
然而,当我们查看跨所有核心的计算的性能分析图时(Dask 会持续在所有工作节点的所有线程上运行性能分析器来获取这些信息),我们发现大部分时间都花费在编译 Numba 代码上。

我们在 numba issue tracker 上就此展开了讨论,该问题现已解决。同一时间内的同一计算现在看起来像这样:
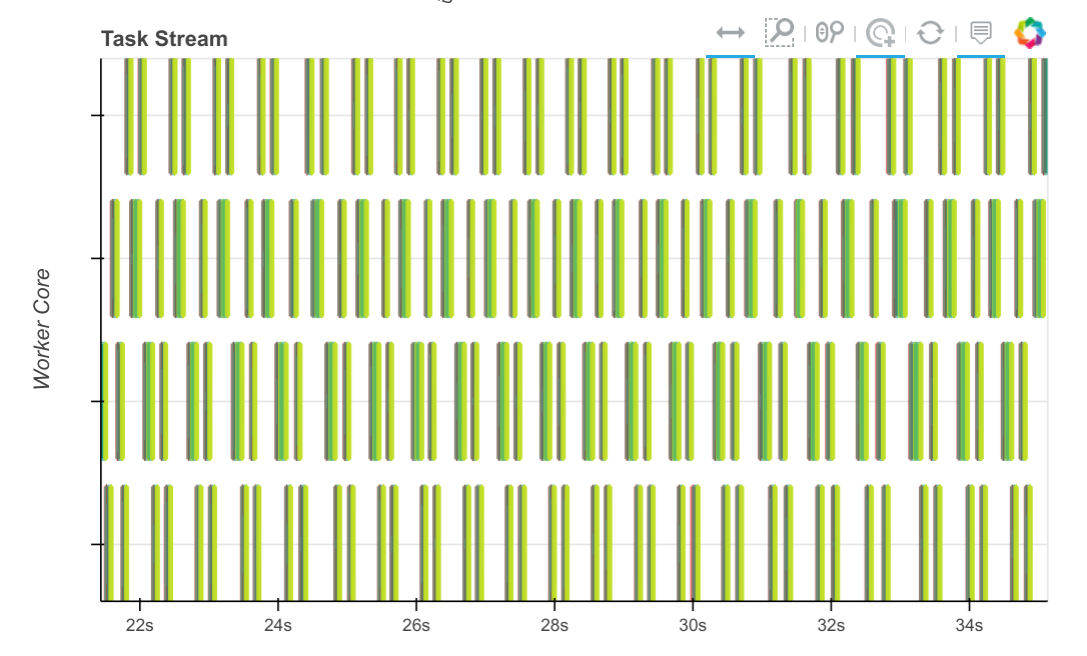
以前需要几秒钟的任务,现在只需要几十毫秒,因此我们可以在相同的时间内处理更多的数据块。
未来工作
构建这样一个有趣的算法是一次有益的经历。上述大部分工作是在一个下午完成的。我们从这项活动中总结出了一些我们自己的任务:
- 为该算法构建一个常规的 Scikit-Learn 风格的估计器类,以便人们在使用它时无需过多考虑 delayed 对象,而是可以直接使用 Dask 数组或 DataFrame
- 整合 Fabian 关于此算法的一些研究,这些研究提高了在稀疏数据和多线程环境中的性能。
- 思考如何改进学习体验,以便 dask.delayed 能够教会新用户如何正确使用它
链接
- SAGA+Dask 实现不同阶段的 Notebooks
- Scikit-Learn/Image + Dask 冲刺活动问题跟踪器
- 关于 SAGA 算法的论文
- Fabian 功能更全的非 Dask SAGA 实现
- 关于重复反序列化的 Numba 问题
博客评论由 Disqus 提供支持