DataFrame Groupby 聚合 深入探讨 groupby
作者:Benjamin Zaitlen & James Bourbeau
使用 Dask 进行按组聚合
本文我们将深入探讨 Dask 如何计算 groupby 聚合。这些操作在 ETL 和数据分析中很常用,其过程是将数据拆分成组,独立地对每组应用一个函数,然后将结果合并在一起。在 PyData/R 社区,这通常被称为 split-apply-combine(拆分-应用-合并)策略(由 Hadley Wickham 最早提出),并在 Pandas 生态系统中广泛使用。
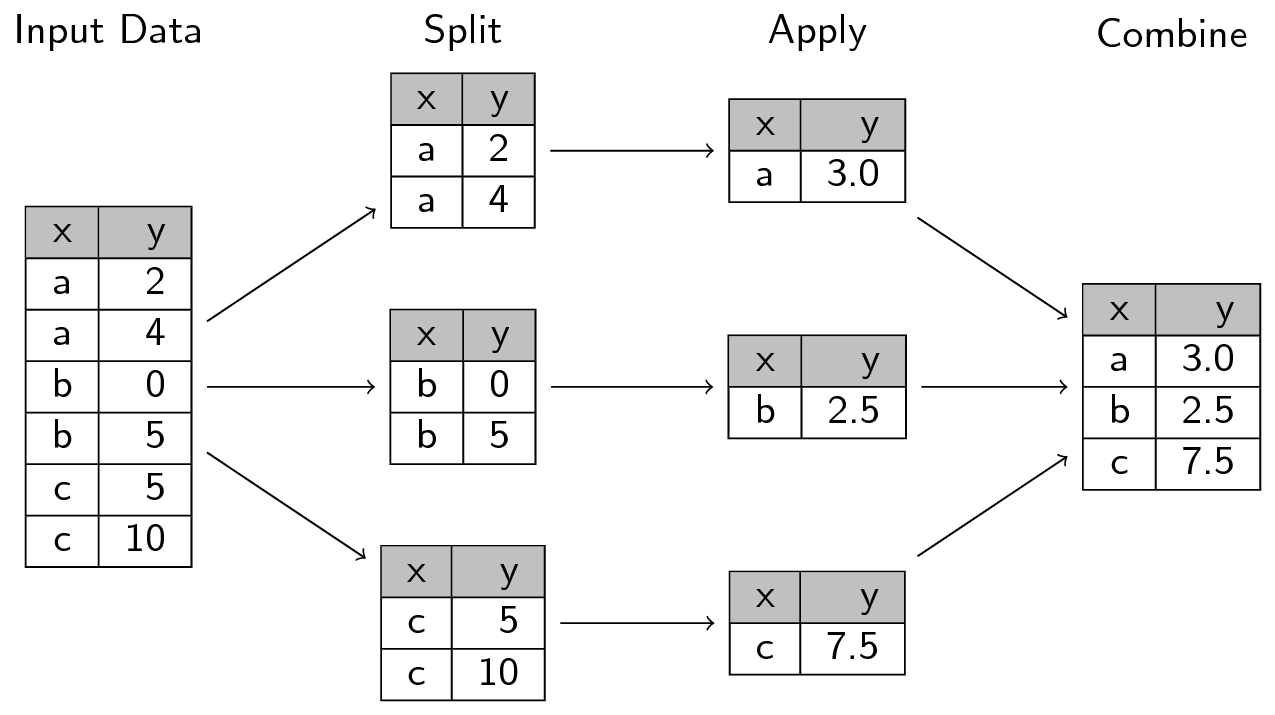
图片来源:swcarpentry.github.io
Dask 借鉴了这一思想,并使用了类似 catchy(朗朗上口)的名字:apply-concat-apply(应用-连接-应用),简称 aca。在本文中,我们将探讨 aca 策略在简单和复杂操作中的应用。
首先,回顾一下 Dask DataFrame 是 DataFrame 对象的集合(例如,Dask DataFrame 的每个分区都是一个 Pandas DataFrame)。例如,假设我们有以下 Pandas DataFrame:
>>> import pandas as pd
>>> df = pd.DataFrame(dict(a=[1, 1, 2, 3, 3, 1, 1, 2, 3, 3, 99, 10, 1],
... b=[1, 3, 10, 3, 2, 1, 3, 10, 3, 3, 12, 0, 9],
... c=[2, 4, 5, 2, 3, 5, 2, 3, 9, 2, 44, 33, 2]))
>>> df
a b c
0 1 1 2
1 1 3 4
2 2 10 5
3 3 3 2
4 3 2 3
5 1 1 5
6 1 3 2
7 2 10 3
8 3 3 9
9 3 3 2
10 99 12 44
11 10 0 33
12 1 9 2
要从这些数据创建一个包含三个分区的 Dask DataFrame,我们可以按索引范围 (0, 4)、(5, 9) 和 (10, 12) 对 df 进行分区。我们可以使用 Dask 的 from_pandas 函数并设置 npartitions=3 来完成此分区。
>>> import dask.dataframe as dd
>>> ddf = dd.from_pandas(df, npartitions=3)
这 3 个分区就是 3 个独立的 Pandas DataFrame
>>> ddf.partitions[0].compute()
a b c
0 1 1 2
1 1 3 4
2 2 10 5
3 3 3 2
4 3 2 3
应用-连接-应用
当 Dask 对 Dask DataFrame 应用函数和/或算法(例如 sum、mean 等)时,它会独立地将该操作应用于所有组成它的分区,将输出收集(或连接)成中间结果,然后再次将操作应用于中间结果以产生最终结果。在内部,Dask 对许多内部 DataFrame 计算都重用了相同的 apply-concat-apply 方法。
让我们通过 aca 过程的每个步骤来分解 Dask 如何计算 ddf.groupby(['a', 'b']).c.sum()。我们将首先把 df 这个 Pandas DataFrame 拆分成三个分区。
>>> df_1 = df[:5]
>>> df_2 = df[5:10]
>>> df_3 = df[-3:]
应用
接下来,我们对三个分区分别执行相同的 groupby(['a', 'b']).c.sum() 操作。
>>> sr1 = df_1.groupby(['a', 'b']).c.sum()
>>> sr2 = df_2.groupby(['a', 'b']).c.sum()
>>> sr3 = df_3.groupby(['a', 'b']).c.sum()
这些操作都会产生一个带有多级索引(MultiIndex)的 Series。
>>> sr1
a b
1 1 2
3 4
2 10 5
3 2 3
3 2
Name: c, dtype: int64
|
>>> sr2
a b
1 1 5
3 2
2 10 3
3 3 11
Name: c, dtype: int64
|
>>> sr3
a b
1 9 2
10 0 33
99 12 44
Name: c, dtype: int64
|
|---|
连接!
在第一次 apply 之后,下一步是将中间结果 sr1、sr2 和 sr3 连接起来。使用 Pandas 的 concat 函数可以很直接地完成这一步。
>>> sr_concat = pd.concat([sr1, sr2, sr3])
>>> sr_concat
a b
1 1 2
3 4
2 10 5
3 2 3
3 2
1 1 5
3 2
2 10 3
3 3 11
1 9 2
10 0 33
99 12 44
Name: c, dtype: int64
再次应用
我们的最后一步是再次对连接后的 sr_concat Series 应用相同的 groupby(['a', 'b']).c.sum() 操作。但我们不再拥有列 a 和 b,那我们该如何继续呢?
退一步来看,我们的目标是将具有相同索引的列中的值相加。例如,有两个行的索引是 (1, 1),对应的值分别是 2 和 5。那么,我们如何对具有相同值的索引进行 groupby 呢?MultiIndex 使用层级(levels)来定义给定索引处的值。Dask 在 apply-concat-apply 计算的最终应用步骤中确定并使用这些层级。在我们的例子中,层级是 [0, 1],也就是说,我们想要第 0 层和第 1 层的索引,如果我们按这两层进行分组(0, 1),我们就有效地将相同的索引组合在一起了。
>>> total = sr_concat.groupby(level=[0, 1]).sum()
>>> total
a b
1 1 7
3 6
9 2
2 10 8
3 2 3
3 13
10 0 33
99 12 44
Name: c, dtype: int64
|
>>> ddf.groupby(['a', 'b']).c.sum().compute()
a b
1 1 7
3 6
2 10 8
3 2 3
3 13
1 9 2
10 0 33
99 12 44
Name: c, dtype: int64
|
>>> df.groupby(['a', 'b']).c.sum()
a b
1 1 7
3 6
9 2
2 10 8
3 2 3
3 13
10 0 33
99 12 44
Name: c, dtype: int64
|
|---|
此外,我们可以很容易地检查这个 apply-concat-apply 计算的步骤,通过可视化计算的任务图。
>>> ddf.groupby(['a', 'b']).c.sum().visualize()

sum 是一个相当直接的计算。对于像 mean 这样稍微复杂一些的操作怎么办?
>>> ddf.groupby(['a', 'b']).c.mean().visualize()

Mean(均值)是无法直接套用 aca 模型的一个好例子——将 mean 值连接起来并再次计算 mean 会得到错误的结果。就像任何计算模式一样:向量化、Map/Reduce 等,有时我们需要创造性地调整计算方式以适应模式。在 aca 的情况下,我们通常可以将计算分解为组成部分。对于 mean,这将是 sum(求和)和 count(计数)。
从上面的任务图中可以看出,每个分区都有两个独立任务:series-groupby-count-chunk 和 series-groupby-sum-chunk。然后结果被聚合成两个最终节点:series-groupby-count-agg 和 series-groupby-sum-agg,最后我们计算均值:total sum / total count。
博客评论由 Disqus 提供支持