大规模 SVD Dask + CuPy + Zarr + 基因组学
作者:Matthew Rocklin (Coiled),Ben Zaitlen (NVIDIA),Alistair Miles (牛津大学)
摘要
我们对大型数据集执行奇异值分解 (SVD) 计算。
我们通过使用完全精确和近似方法,以及同时使用 CPU 和 GPU 来修改计算。
最终,我们在 15-20 秒内使用多 GPU 机器对 200GB 模拟数据计算了一个近似 SVD。然后,我们从存储在云端的数据集运行此过程,发现 I/O 如预期的那样,是主要的瓶颈。
SVD - 简单案例
Dask 数组包含一个相对复杂的 SVD 算法,适用于高瘦或矮胖的情况,但在近似方形的情况下效果不佳。它的工作原理是对数组的每个块进行 QR 分解,组合 R 矩阵,对这些矩阵进行另一个较小的 SVD 计算,然后执行一些矩阵乘法以获得完整结果。它在数值上是稳定的,速度也相当快,前提是 QR 分解的中间 R 矩阵大部分能装入内存。
这里的内存限制是,如果你有一个 n 乘 m 的高瘦数组(n >> m)被切分成 k 块,那么你需要大约 m**2 * k 的空间。这在许多情况下都是如此,包括典型的 PCA 机器学习工作负载,其中表格数据只有几列(最多数百列)和许多行。
它易于使用且相当稳健。
import dask.array as da
x = da.random.random((10000000, 20))
x
|
u, s, v = da.linalg.svd(x)
这在矮胖的情况下(列远多于行时)也工作良好,但我们始终假设其中一个维度未分块,而另一个维度的块要长得多,否则,数据可能无法装入内存。
近似 SVD
如果你的数据集在两个维度上都很大,那么上面的算法就不能直接使用。但是,如果你不需要精确结果,或者只需要几个分量,那么有很多优秀的近似算法。
Dask 数组在 da.linalg.svd_compressed 函数中实现了其中一个近似算法。有了它,我们可以计算非常大矩阵的近似 SVD。
我们最近在解决一个问题(如下所述)时,发现使用此算法时仍然会遇到内存不足的问题。我们遇到了两个挑战
-
该算法需要多次遍历数据,但 Dask 任务调度器在输入矩阵加载一次后会将其保留在内存中,以避免重复计算。虽然仍然可以工作,但 Dask 不得不反复将数据移至磁盘并读回,这显著降低了性能。
我们通过在算法中加入显式的重复计算步骤来解决这个问题。
-
相关的数据块会在不同时间加载,因此需要比必要的时间更长地停留在内存中等待其关联的块。
我们通过启用任务融合作为优化传递来解决这个问题。
在深入探讨技术解决方案之前,我们快速介绍一下推动这项工作的用例。
应用 - 基因组学
许多研究正在使用基因组测序来研究同一物种不同个体之间的遗传变异。这包括对人类群体的研究,也包括对小鼠、蚊子或致病寄生虫等其他物种的研究。这些研究通常会在基因组序列中发现大量个体间存在差异的位点。例如,人类基因组中有超过 1 亿个变异位点,像 UK BioBank 这样的现代研究正致力于对 100 万或更多个体进行基因组测序。
在人类、小鼠或蚊子等二倍体物种中,每个个体携带两个基因组序列,一个来自父亲,一个来自母亲。在 1 亿个基因组变异位点中的每一个位点,一个基因组可能携带两种或多种“等位基因”。一种思考方式是通过 Punnett square(庞氏方格),它表示个体在这些变异位点之一可能携带的不同基因型
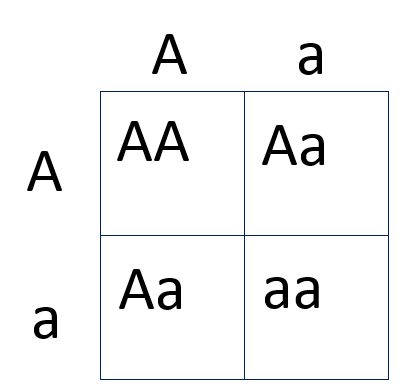
上图中,有三种可能的基因型:AA、Aa 和 aa。对于计算基因组学,这些基因型可以编码为 0、1 或 2。在一项针对 N 个个体样本中检测 M 个遗传变异的物种研究中,我们可以将这些基因型表示为一个 (M x N) 的整数数组。对于现代人类遗传学研究,该数组的规模可能接近 (1 亿 x 100 万)。(尽管在实践中,第一个维度(变异数量)的大小可以有所减少,至少可以减少一个数量级,因为许多遗传变异携带的信息很少和/或彼此相关。)
这些遗传差异并非随机,而是携带了关于个体间遗传相似性和共同祖先模式的信息,因为它们通过多代遗传。一项常见的任务是对这些数据进行降维分析,例如主成分分析 (SVD),以识别反映这些共同祖先程度差异的遗传结构。这是发现与不同疾病相关的遗传变异以及了解群体和物种遗传历史的重要部分。
减少计算 SVD 等分析所需的时间,就像所有科学一样,能够在更短的时间内探索更大的数据集并测试更多假设。实际上,这意味着不仅仅是快速 SVD,而是从数据加载到分析再到理解的端到端加速流程。
我们希望在泡一杯茶的时间内完成实验
使用 Dask 的高性能 SVD
有了这些科学背景,现在我们回到计算方面。
为了阻止 Dask 持续占用数据,我们在构建图时故意触发计算。这在 Dask 计算中有些不典型(我们更倾向于在计算之前一次性进行尽可能多的计算),但考虑到这个问题的多趟遍历特性,这样做很有用。这是一个相当容易的改变,已在 dask/dask #5041 中提供。
此外,我们发现开启适度的任务融合也很有帮助。
import dask
dask.config.set({"optimization.fuse.ave-width": 5})
然后一切正常
我们将在几种不同的硬件选项上尝试这种 SVD,包括
- 一台 MacBook Pro
- 一台 DGX-2,配备 16 个高端 GPU 和快速互连的 NVIDIA 工作站
- 一个在 AWS 上的二十节点集群
Macbook Pro
我们可以在 Macbook Pro 上轻松地对 20GB 数组执行 SVD
import dask.array as da
x = da.random.random(size=(1_000_000, 20_000), chunks=(20_000, 5_000))
u, s, v = da.linalg.svd_compressed(x, k=10, compute=True)
v.compute()
这个调用不再是完全惰性的,并且会重新计算几次 x,但它工作正常,并且在消费级笔记本电脑上仅使用几 GB 内存即可工作。
在笔记本电脑上计算这个需要大约 2 分 30 秒。这很棒!尝试起来非常容易,不需要任何特殊硬件或设置,而且在很多情况下速度已经足够快了。通过在本地工作,我们可以快速迭代。
既然一切正常,我们可以尝试不同的硬件了。
添加 GPU(15 秒 SVD)
免责声明:其中一位作者 (Ben Zaitlen) 就职于 NVIDIA
通过使用多 GPU 机器,我们可以显著提高性能。NVIDIA 和其他制造商现在生产的机器在同一个物理机箱内集成了多个 GPU。在下一节中,我们将在 DGX2 上运行计算,这是一台配备 16 个 GPU 并拥有 GPU 间快速互连的机器。
下面是几乎相同的代码,运行时间显著缩短,但我们进行了以下更改
- 我们将数组大小增加了 10 倍
- 我们将 NumPy 替换为 CuPy,一个 GPU 上的 NumPy 实现
- 我们使用一台配备 NVLink GPU 互连的十六 GPU DGX-2 机器(NVLink 将显著减少工作节点之间的数据传输时间)
在 DGX2 上,我们可以在 10 到 15 秒内计算 200GB Dask 数组的 SVD。
完整的 notebook 在这里,相关代码片段如下
# Some GPU specific setup
from dask_cuda import LocalCluster
cluster = LocalCluster(...)
client = Client(cluster)
import cupy
import dask.array as da
rs = da.random.RandomState(RandomState=cupy.random.RandomState)
# Create the data and run the SVD as normal
x = rs.randint(0, 3, size=(10_000_000, 20_000),
chunks=(20_000, 5_000), dtype="uint8")
x = x.persist()
u, s, v = da.linalg.svd_compressed(x, k=10, seed=rs)
v.compute()
要查看运行情况,我们建议观看此屏幕录像
从磁盘读取数据集
虽然令人印象深刻,但上面的计算主要受限于生成随机数据和执行矩阵计算。GPU 在这两方面都很擅长。
然而在实践中,我们的输入数组不会是随机生成的,它将来自存储在磁盘上或越来越普遍地存储在云端的数据集。为了更贴近实际,我们使用存储在 GCS 的 Zarr 格式数据进行了类似的计算。
在这个Zarr SVD 示例中,我们将一个 25GB 的 GCS 支持数据集加载到 DGX2 上,运行一些预处理步骤,然后执行 SVD。预处理和 SVD 计算的总共运行时间为 18.7 秒,数据加载耗时 14.3 秒。
同样,在 DGX2 上,从数据加载到 SVD 的运行时间不到泡一杯茶的时间。然而,数据加载可以加速。我们从 GCS 读取数据到机器的主内存(主机内存),解压 zarr 数据,然后将数据从主机内存移动到 GPU(设备内存)。在主机内存和设备内存之间来回传递数据会显著降低性能。直接读取到 GPU,绕过主机内存,将改善整个流程。
因此,我们回到了高性能计算的一个共同经验
高性能计算不是关于把一件事做到极致,而是关于不把任何事做得糟糕.
在这种情况下,GPU 使我们的计算速度足够快,以至于我们现在需要关注系统的其他组件,特别是磁盘带宽,以及一个用于将 Zarr 数据直接读取到 GPU 内存的读取器。
云
免责声明:其中一位作者 (Matthew Rocklin) 就职于 Coiled Computing
我们也可以在云上使用任何数量的框架来运行它。在此例中,我们使用了 Coiled Cloud 服务在 AWS 上进行部署。
from coiled_cloud import Cloud, Cluster
cloud = Cloud()
cloud.create_cluster_type(
organization="friends",
name="genomics",
worker_cpu=4,
worker_memory="16 GiB",
worker_environment={
"OMP_NUM_THREADS": 1,
"OPENBLAS_NUM_THREADS": 1,
# "EXTRA_PIP_PACKAGES": "zarr"
},
)
cluster = Cluster(
organization="friends",
typename="genomics",
n_workers=20,
)
from dask.distributed import Client
client = Client(cluster)
# then proceed as normal
使用 20 台总共 80 个 CPU 核心的机器,处理比 MacBook Pro 示例大 10 倍的数据集,我们能够在大致相同的时间内完成运行。这表明该问题的扩展性接近最优,考虑到 SVD 计算的复杂性,这是令人欣慰的。
此问题的屏幕录像可在此处查看
压缩
提高性能的最简单方法之一是通过压缩来减小数据的大小。这些数据高度可压缩有两个原因
- 真实世界的数据本身具有结构和重复性(尽管随机生成的数据没有)
- 我们存储的条目只取四个值。在我们只需要两比特整数时,却使用了八比特整数
我们先解决第二个问题。
位操作压缩
理想情况下,Numpy 应该有一个两比特整数数据类型。不幸的是它没有,这很难做到,因为计算机中的内存通常是以完整的字节为单位来考虑的。
为了解决这个问题,我们可以使用位运算将四个值塞进一个值。这里有一些实现此功能的函数,假设我们的数组是方形的,并且最后一个维度能被四整除。
import numpy as np
def compress(x: np.ndarray) -> np.ndarray:
out = np.zeros_like(x, shape=(x.shape[0], x.shape[1] // 4))
out += x[:, 0::4]
out += x[:, 1::4] << 2
out += x[:, 2::4] << 4
out += x[:, 3::4] << 6
return out
def decompress(out: np.ndarray) -> np.ndarray:
back = np.zeros_like(out, shape=(out.shape[0], out.shape[1] * 4))
back[:, 0::4] = out & 0b00000011
back[:, 1::4] = (out & 0b00001100) >> 2
back[:, 2::4] = (out & 0b00110000) >> 4
back[:, 3::4] = (out & 0b11000000) >> 6
return back
然后,我们可以结合 Dask 使用这些函数以压缩状态存储数据,并在需要时惰性解压。
x = x.map_blocks(compress).persist().map_blocks(decompress)
就是这样。我们压缩每个数据块并将其存储在内存中。然而,我们得到的输出变量 x 会在我们对其进行操作之前解压每个块,所以我们不需要担心处理压缩块的问题。
使用 Zarr 压缩
一个稍微更通用但可能效率较低的方法是使用像 Zarr 这样的专业压缩库来压缩我们的数组。
下面的示例展示了我们在实践中是如何做到的。
import zarr
import numpy as np
from numcodecs import Blosc
compressor = Blosc(cname='lz4', clevel=3, shuffle=Blosc.BITSHUFFLE)
x = x.map_blocks(zarr.array, compressor=compressor).persist().map_blocks(np.array)
此外,如果我们使用 dask-distributed 调度器,那么我们希望确保 Blosc 压缩库不使用额外的线程。这样我们就不会并行调用一个并行库,这可能会引起一些争用。
def set_no_threads_blosc():
""" Stop blosc from using multiple threads """
import numcodecs
numcodecs.blosc.use_threads = False
# Run on all workers
client.register_worker_plugin(set_no_threads_blosc)
这种方法更通用,可能是一个不错的备用技巧,但它在 GPU 上不起作用,这最终也是我们选择上面一节中位操作方法的原因,该方法使用了在 Numpy 和 CuPy 库中都能统一访问的 API。
总结
在这篇文章中,我们围绕基因组学中的一个重要问题做了几件事。
- 我们学习了一些科学知识
- 我们将一个科学问题转化为一个计算问题,特别是转化为执行大规模奇异值分解的需求
- 我们使用了 dask.array 中一个现成的算法,它表现得相当好,前提是我们能够接受对数组进行多次遍历
- 然后我们快速地在三种架构上尝试了该算法
- 一台 Macbook Pro
- 一台多 GPU 机器
- 一个云端集群
- 最后,我们讨论了一些通过压缩将更多数据打包到相同内存中的技巧
这个问题很棒,因为我们得以深入研究一个技术科学问题,同时也能快速尝试各种架构,以研究未来可能做出的硬件选择。
我们今天在这里使用了多种技术,这些技术由不同的社区和公司开发。很高兴看到它们如何无缝地协同工作,提供灵活而一致的体验。
博客评论由 Disqus 提供