比较 Dask-ML 与 Ray Tune 的模型选择算法 现代超参数优化,Scikit-Learn 支持,框架支持以及扩展到多机。
作者:Scott Sievert (威斯康星大学麦迪逊分校)
超参数优化是推导无法从数据中学习的模型参数的过程。这个过程通常耗时且消耗资源,特别是在深度学习的背景下。关于这个过程的良好描述可以在“调优 estimator 的超参数”中找到,而由此产生的问题则在 Dask-ML 的“超参数搜索”文档中得到了简洁的总结。
有大量的库和框架可以解决这个问题。Scikit-Learn 的模块已在 Dask-ML 和 auto-sklearn 中进行了镜像,两者都提供了高级的超参数优化技术。不遵循 Scikit-Learn 接口的其他实现包括 Ray Tune、AutoML 和 Optuna。
Ray 最近为 Ray Tune 提供了一个封装器,它模仿了 Scikit-Learn API,称为 tune-sklearn(文档,源代码)。该库的介绍中提到:
尖端的超参数调优技术(贝叶斯优化、早期停止、分布式执行)可以比网格搜索和随机搜索提供显著的加速。
然而,机器学习生态系统中缺少一种解决方案,既能让用户利用这些新算法,又能让他们留在 Scikit-Learn API 内。在这篇博文中,我们介绍了 tune-sklearn [Ray 的调优库] 来弥合这一差距。Tune-sklearn 是 Scikit-Learn 模型选择模块的直接替代品,具有最先进的优化功能。
这个说法并不准确:一年多来,Dask-ML 一直提供对“尖端超参数调优技术”的访问,并且拥有与 Scikit-Learn 兼容的 API。为了纠正他们的说法,让我们看看 Ray 的 tune-sklearn 提供的每一个功能,并将它们与 Dask-ML 进行比较。
以下是 [Ray 的] tune-sklearn 所提供的功能:
- 与 Scikit-Learn API 的一致性 ...
- 现代超参数调优技术 ...
- 框架支持 ...
- 扩展 ... [到] 多个核心甚至多台机器。
[Ray 的] Tune-sklearn 也速度快。
Dask-ML 的模型选择模块拥有所有这些功能:
- 与 Scikit-Learn API 的一致性: Dask-ML 的模型选择 API 模仿 Scikit-Learn 的模型选择 API。
- 现代超参数调优技术: Dask-ML 提供最先进的超参数调优技术。
- 框架支持: Dask-ML 模型选择支持许多库,包括 Scikit-Learn、PyTorch、Keras、LightGBM 和 XGBoost。
- 扩展: Dask-ML 支持分布式调优(怎么可能不支持?),并且支持大于内存的数据集。
Dask-ML 也速度快。在“速度”部分,我们展示了 Dask-ML、Ray 和 Scikit-Learn 之间的基准测试。
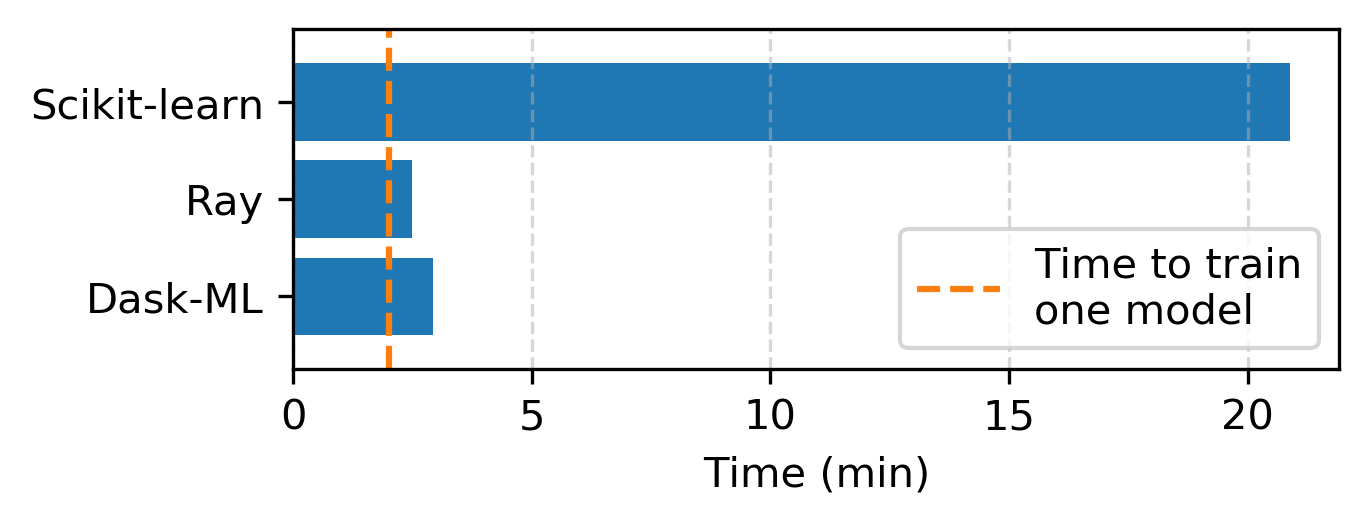
只有达到解决方案的时间是相关的;所有这些方法产生的模型分数都相似。详见“速度”。
现在,让我们详细介绍如何使用 Dask-ML 来获得上述 5 个功能。
与 Scikit-Learn API 的一致性
Dask-ML 与 Scikit-Learn API 保持一致。
以下是如何使用 Scikit-Learn、Dask-ML 和 Ray 的 tune-sklearn 进行超参数优化:
## Trimmed example; see appendix for more detail
from sklearn.model_selection import RandomizedSearchCV
search = RandomizedSearchCV(model, params, ...)
search.fit(X, y)
from dask_ml.model_selection import HyperbandSearchCV
search = HyperbandSearchCV(model, params, ...)
search.fit(X, y, classes=[0, 1])
from tune_sklearn import TuneSearchCV
search = TuneSearchCV(model, params, ...)
search.fit(X, y, classes=[0, 1])
model 和 params 的定义遵循常规的 Scikit-Learn 定义,详见附录。
显然,Dask-ML 和 Ray 的 tune-sklearn 都与 Scikit-Learn 兼容。现在让我们重点关注每种搜索的性能和配置。
现代超参数调优技术
Dask-ML 以 Scikit-Learn 接口提供最先进的超参数调优技术。
Ray 的 tune-sklearn 的介绍中提到了这个说法:
tune-sklearn 是唯一允许您通过简单地切换几个参数就能轻松利用贝叶斯优化、HyperBand 和其他优化技术的 Scikit-Learn 接口。
当前超参数优化的最先进技术是“Hyperband”。Hyperband 通过一个有原则的早期停止方案减少了所需的计算量;除此之外,它与 Scikit-Learn 流行的 RandomizedSearchCV 相同。
Hyperband 奏效了。因此,它非常流行。自 2016 年 Li 等人引入 Hyperband 以来,这篇论文已被引用超过 470 次,并已在许多不同的库中实现,包括 Dask-ML、Ray Tune、keras-tune、Optuna、AutoML1 和 微软的 NNI。原始论文显示与所有相关实现相比有相当显著的改进2,并且这种显著改进在后续工作中持续存在3。以下是 Hyperband 的一些说明性结果:
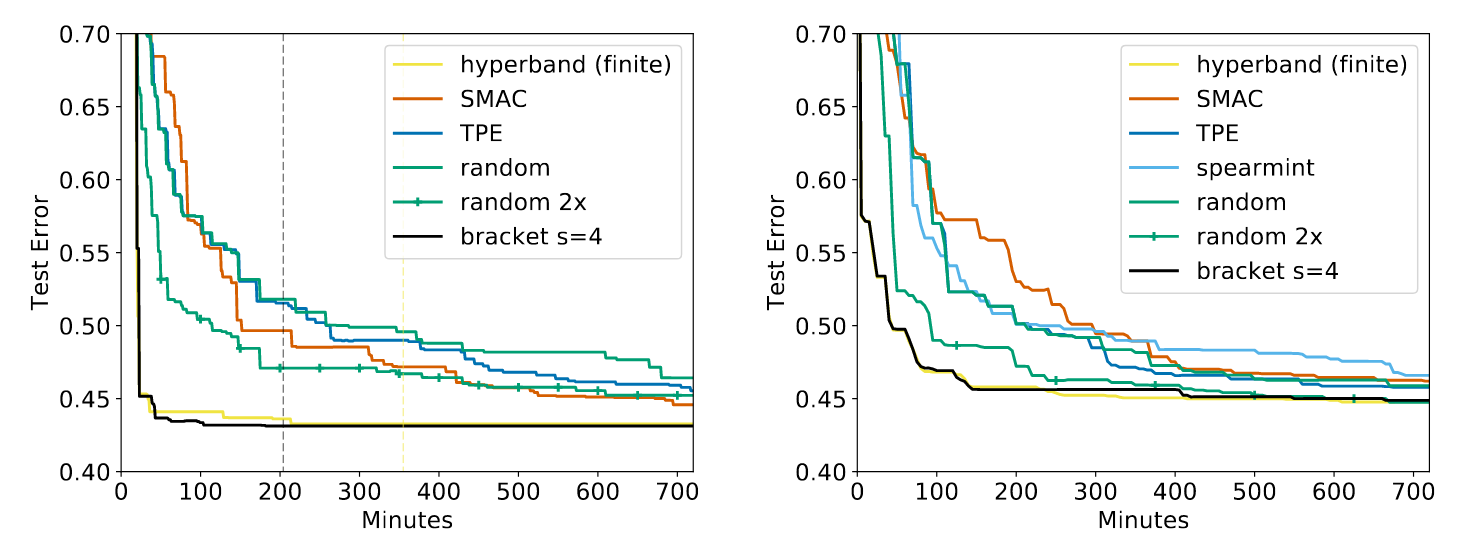
所有算法都配置执行相同量的工作,除了“random 2x”(随机 2 倍)执行两倍的工作量。“hyperband (finite)”(有限 Hyperband)类似于 Dask-ML 的默认实现,“bracket s=4”(分支 s=4)类似于 Ray 的默认实现。“random”(随机)是随机搜索。SMAC4、spearmint5 和 TPE6 是流行的贝叶斯算法。
Hyperband 毫无疑问是一种“尖端”的超参数优化技术。Dask-ML 和 Ray 提供了该算法的 Scikit-Learn 实现,它们依赖于相似的实现,并且 Dask-ML 的实现还提供了一个配置经验法则。Dask-ML 和 Ray 的文档都鼓励使用 Hyperband。
Ray 确实支持在其 Hyperband 实现之上使用一种称为贝叶斯采样(Bayesian sampling)的技术。这改变了模型初始化的超参数采样方案。它可以与 Hyperband 的早期停止方案结合使用。将此选项添加到 Dask-ML 的 Hyperband 实现是 Dask-ML 的未来工作。
框架支持
Dask-ML 模型选择支持许多库,包括 Scikit-Learn、PyTorch、Keras、LightGBM 和 XGBoost。
Ray 的 tune-sklearn 支持这些框架:
tune-sklearn 主要用于调优 Scikit-Learn 模型,但它也支持许多其他带有 Scikit-Learn 封装器的框架,例如 Skorch (Pytorch)、KerasClassifiers (Keras) 和 XGBoostClassifiers (XGBoost),并提供了相关示例。
显然,Dask-ML 和 Ray 都支持许多相同的库。
然而,Dask-ML 和 Ray 都有一些限制。某些库不提供 partial_fit 的实现7,因此并非所有现代超参数优化技术都能提供。下表比较了不同库及其在 Dask-ML 模型选择和 Ray 的 tune-sklearn 中的支持情况:
| 模型库 | Dask-ML 支持 | Ray 支持 | Dask-ML:早期停止? | Ray:早期停止? |
|---|---|---|---|---|
| Scikit-Learn | ✔ | ✔ | ✔* | ✔* |
| PyTorch (通过 Skorch) | ✔ | ✔ | ✔ | ✔ |
| Keras (通过 SciKeras) | ✔ | ✔ | ✔** | ✔** |
| LightGBM | ✔ | ✔ | ❌ | ❌ |
| XGBoost | ✔ | ✔ | ❌ | ❌ |
* 仅适用于实现 partial_fit 的模型。
** 感谢 Dask 开发者在 scikeras#24 方面所做的工作。
从这个角度来看,Dask-ML 和 Ray 模型选择在框架支持方面具有相同的水平。当然,Dask 通过 Dask-ML 的 xgboost 模块和 dask-lightgbm 与 LightGBM 和 XGBoost 有关联集成。
扩展
Dask-ML 支持分布式调优(怎么可能不支持?),即跨多台机器/核心进行并行化。此外,它还支持大于内存的数据。
[Ray 的] Tune-sklearn 利用 Ray Tune(一个用于分布式超参数调优的库),可以高效透明地在多个核心甚至多台机器上并行化交叉验证。
自然,Dask-ML 也能够扩展到多个核心/机器,因为它依赖于 Dask。Dask 对从个人机器到超级计算机的各种部署选项有广泛支持。Dask 极有可能在你可用的任何计算系统上运行,包括 Kubernetes、SLURM、YARN 和 Hadoop 集群,以及你的个人机器。
Dask-ML 的模型选择还支持大于内存的数据集,并且经过全面测试。Ray 对大于内存数据的支持尚未测试,并且没有详细说明如何使用 Ray Tune 与 PyTorch/Keras 中的分布式数据集实现的示例。
此外,我在“使用 Dask 进行更好更快的超参数优化”中对 Dask-ML 的模型选择模块进行了基准测试,以了解达到解决方案的时间如何受 Dask worker 数量的影响。也就是说,达到特定准确度所需的时间如何随 worker 数量 $P$ 扩展?起初,它会像 $1/P$ 一样扩展,但当 worker 数量很大时,串行部分将根据阿姆达尔定律决定达到解决方案的时间。简而言之,我发现对于特定的搜索,Dask-ML 的 HyperbandSearchCV 加速在 24 个 worker 附近开始饱和。
速度
Dask-ML 和 Ray 都比 Scikit-Learn 快得多。
Ray 的 tune-sklearn 在介绍中与 Scikit-Learn 和 Dask-ML 中发现的 GridSearchCV 类进行了一些基准测试。一个更公平的基准测试应该使用 Dask-ML 的 HyperbandSearchCV,因为它与 Ray 的 tune-sklearn 中的算法几乎相同。具体来说,我感兴趣的是比较这些方法:
- Scikit-Learn 的
RandomizedSearchCV。这是一个流行的实现,我自己曾用一个自定义模型对其进行了引导。 - Dask-ML 的
HyperbandSearchCV。这是一种用于RandomizedSearchCV的早期停止技术。 - Ray tune-sklearn 的
TuneSearchCV。这是一种与HyperbandSearchCV略有不同的早期停止技术。
每个搜索都配置执行相同的任务:采样 100 个参数并训练不超过 100 个“epoch”或数据传递次数8。每个 estimator 都按照其各自文档的建议进行配置。每个搜索使用 8 个 worker 进行单次交叉验证分割,并且一次 partial_fit 调用需要一秒钟,处理 50,000 个示例。完整的设置可以在附录中找到。
以下是每个库完成相同搜索所需的时间:
值得注意的是,我们没有为了这次基准测试改进 Dask-ML 代码库,代码运行方式与过去一年相同9。尽管如此,这次基准测试中可能也存在有偏基准测试的其他痕迹。
显然,与 Scikit-Learn 相比,Ray 和 Dask-ML 在使用 8 个 worker 时提供了相似的性能。值得称赞的是,Ray 的实现在使用 8 个 worker 时比 Dask-ML 快约 15%。我们怀疑这种性能提升来自于 Ray 实现了一种异步的 Hyperband 变体。我们应该研究 Dask 和 Ray 之间的这种差异,以及它们如何平衡权衡(FLOP 数量与达到解决方案的时间)。这将随 worker 数量而变化:异步的 Hyperband 变体在与单个 worker 一起使用时不会带来任何好处。
Dask-ML 在串行环境或 worker 数量较少时能快速达到分数。Dask-ML 优先拟合得分高的模型:如果要拟合 100 个模型但只有 4 个 worker 可用,Dask-ML 会选择得分最高的模型。这在串行环境中最为相关10;详见“使用 Dask 进行更好更快的超参数优化”的基准测试。此功能在此基准测试中省略,该基准测试仅关注达到解决方案的时间。
结论
Dask-ML 和 Ray 在模型选择方面提供相同的功能:具有 Scikit-Learn 兼容 API 的最先进功能,并且两种实现都对不同的框架提供了相当广泛的支持,并依赖于可以扩展到多台机器的后端。
此外,Ray 的实现为进一步开发提供了动力,特别是以下项目:
- 增加对更多库的支持,包括 Keras (dask-ml#696, dask-ml#713, scikeras#24)。SciKeras 是 Keras 的 Scikit-Learn 封装器,它(现在)可以与 Dask-ML 模型选择一起工作,因为 SciKeras 模型实现了 Scikit-Learn 模型 API。
- 更好地记录 Dask-ML 支持的模型 (dask-ml#699)。Dask-ML 支持任何实现 Scikit-Learn 接口的模型,并且有针对 Keras、PyTorch、LightGBM 和 XGBoost 的封装器。现在,Dask-ML 的文档显著强调了这一事实。
Ray 的实现也帮助推动和明确了未来的工作。Dask-ML 应包括以下实现:
- 为 Hyperband 实现增加贝叶斯采样方案,类似于 Ray 和 BOHB 的方案 (dask-ml#697)。
- 一个适用于探索性超参数搜索的
HyperbandSearchCV配置。初步实现在 dask-ml#532 中,应与 Ray 进行基准测试。
幸运的是,所有这些开发都是直接的修改,因为 Dask-ML 模型选择框架非常灵活。
感谢 Tom Augspurger、Matthew Rocklin、Julia Signell 和 Benjamin Zaitlen 提供的反馈、建议和编辑。
附录
基准测试设置
这是 Dask-ML、Scikit-Learn 和 Ray 之间基准测试的完整设置。详细信息可在 stsievert/dask-hyperband-comparison 中找到。
让我们创建一个虚拟模型,其 partial_fit 调用处理 50,000 个示例需要 1 秒。这对于本次基准测试是合适的;我们只关注完成搜索所需的时间,而不关注模型的表现。Scikit-learn、Ray 和 Dask-ML 在选择要评估的超参数方面有非常相似的方法;它们在早期停止技术上有所不同。
from scipy.stats import uniform
from sklearn.model_selection import make_classification
from benchmark import ConstantFunction # custom module
# This model sleeps for `latency * len(X)` seconds before
# reporting a score of `value`.
model = ConstantFunction(latency=1 / 50e3, max_iter=max_iter)
params = {"value": uniform(0, 1)}
# This dummy dataset mirrors the MNIST dataset
X_train, y_train = make_classification(n_samples=int(60e3), n_features=784)
该模型训练 100 个 epoch(即数据通过次数)需要 2 分钟。详细信息可在 stsievert/dask-hyperband-comparison 中找到。
让我们将搜索配置为使用 8 个 worker 和单次交叉验证分割:
from sklearn.model_selection import RandomizedSearchCV, ShuffleSplit
split = ShuffleSplit(test_size=0.2, n_splits=1)
kwargs = dict(cv=split, refit=False)
search = RandomizedSearchCV(model, params, n_jobs=8, n_iter=n_params, **kwargs)
search.fit(X_train, y_train) # 20.88 minutes
from dask_ml.model_selection import HyperbandSearchCV
dask_search = HyperbandSearchCV(
model, params, test_size=0.2, max_iter=max_iter, aggressiveness=4
)
from tune_sklearn import TuneSearchCV
ray_search = TuneSearchCV(
model, params, n_iter=n_params, max_iters=max_iter, early_stopping=True, **kwargs
)
dask_search.fit(X_train, y_train) # 2.93 minutes
ray_search.fit(X_train, y_train) # 2.49 minutes
完整示例用法
from sklearn.linear_model import SGDClassifier
from scipy.stats import uniform, loguniform
from sklearn.datasets import make_classification
model = SGDClassifier()
params = {"alpha": loguniform(1e-5, 1e-3), "l1_ratio": uniform(0, 1)}
X, y = make_classification()
from sklearn.model_selection import RandomizedSearchCV
search = RandomizedSearchCV(model, params, ...)
search.fit(X, y)
from dask_ml.model_selection import HyperbandSearchCV
HyperbandSearchCV(model, params, ...)
search.fit(X, y, classes=[0, 1])
from tune_sklearn import TuneSearchCV
search = TuneSearchCV(model, params, ...)
search.fit(X, y, classes=[0, 1])
-
他们在 HpBandSter 中的 Hyperband 实现包含在 Auto-PyTorch 和 BOAH 中。 ↩
-
参见“Hyperband:一种基于 Bandit 的新型超参数优化方法”中的图 4、7 和 8。 ↩
-
SMAC 在“通用算法配置的序贯模型优化”中有描述,并可在 AutoML 中获得。 ↩
-
Spearmint 在“机器学习算法的实用贝叶斯优化”中有描述,并可在 HIPS/spearmint 中获得。 ↩
-
引自 Ray 的 README.md:“如果 estimator 不支持
partial_fit,将显示警告,说明无法进行早期停止,它将仅在 Ray 的并行后端上运行交叉验证。” ↩ -
我选择随机搜索而不是网格搜索进行基准测试,因为随机搜索产生更好的结果,而网格搜索需要估计每个参数的重要性;更多细节请参阅 Bergstra 和 Bengio 的“超参数优化的随机搜索”。 ↩
-
尽管在 dask-ml#527 中有一个相关的实现。 ↩
-
因为如果有无限数量的 worker,优先级就没有意义了。 ↩
博客评论由 Disqus 提供支持