如何使用 Dask Helm Chart 运行不同类型的 Worker
作者 Matthew Murray (NVIDIA)
引言
今天,我们将学习如何使用 Dask Helm Chart 在 Kubernetes 集群上部署 Dask,然后使用注释运行和扩展不同类型的 Worker。
Dask Helm Chart 是什么?
Dask Helm Chart 是使用 Helm(一个 Kubernetes 应用程序包管理器)部署 Dask 的一种便捷方式。使用 Dask Helm Chart 部署 Dask 后,我们可以连接到我们的 HelmCluster 并开始扩展 Worker。
Dask Kubernetes 是什么?
Dask Kubernetes 允许您在 Kubernetes 集群上部署和管理您的 Dask 部署。Dask Kubernetes Python 包有一个 HelmCluster 类(以及其他功能),使您能够从 Python 管理集群。在本教程中,我们将使用 HelmCluster 作为我们的集群管理器。
先决条件
- 已安装 Helm 并能够运行
helm命令 - 已有一个正在运行的 Kubernetes 集群。无论您是使用 MiniKube 或 Kind 在本地运行 Kubernetes,还是使用 AWS 或 GCP 等云提供商,都无关紧要。但您的集群需要能够访问 GPU 节点 才能运行 GPU Worker。您还需要安装 RAPIDS 来运行 GPU Worker 示例。
- 已安装 kubectl。尽管这不是必需的。
就这些了,让我们开始吧!
安装 Dask Kubernetes
来自文档,
pip install dask-kubernetes --upgrade
或
conda install dask-kubernetes -c conda-forge
安装 Dask Helm Chart
首先,使用 Helm 在 Kubernetes 上部署 Dask
helm repo add dask https://helm.dask.org/
helm repo update
helm install my-dask dask/dask
现在您的 Kubernetes 集群上应该正在运行 Dask。如果您安装了 kubectl,您可以运行 kubectl get all -n default
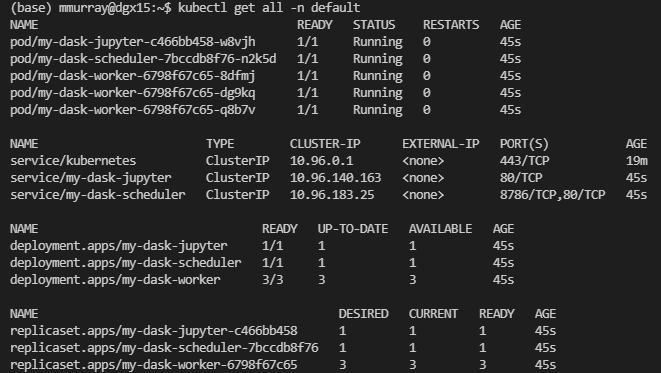
您可以看到我们创建了一些资源!主要要知道的是,我们一开始有三个 Dask Worker。
向我们的 Dask 部署添加 GPU Worker 组
Helm Chart 具有开箱即用的默认值,用于在 Kubernetes 上部署我们的 Dask 集群。但是现在,因为我们想创建一些 GPU Worker,我们需要更改 Dask Helm Chart 中的默认值。为了做到这一点,我们可以复制当前的 values.yaml 文件,更新它以添加一个 GPU Worker 组,然后更新我们的 Helm 部署。
- 首先,您可以复制 Dask Helm Chart 中
values.yaml文件的内容,并创建一个名为my-values.yaml的新文件。 - 接下来,我们将更新文件中名为
additional_worker_groups的部分。该部分如下所示
additional_worker_groups: [] # Additional groups of workers to create
# - name: high-mem-workers # Dask worker group name.
# resources:
# limits:
# memory: 32G
# requests:
# memory: 32G
# ...
# (Defaults will be taken from the primary worker configuration)
- 现在,我们将编辑该部分,使其看起来像这样
additional_worker_groups: # Additional groups of workers to create
- name: gpu-workers # Dask worker group name.
replicas: 1
image:
repository: rapidsai/rapidsai-core
tag: 21.12-cuda11.5-runtime-ubuntu20.04-py3.8
dask_worker: dask-cuda-worker
extraArgs:
- --resources
- "GPU=1"
resources:
limits:
nvidia.com/gpu: 1
- 现在,我们可以使用我们在
my-values.yaml中的新值来更新我们的部署。
helm upgrade -f my-values.yaml my-dask dask/dask
- 再次,您可以运行
kubectl get all -n default,您将看到我们新的 GPU Worker Pod 正在运行。
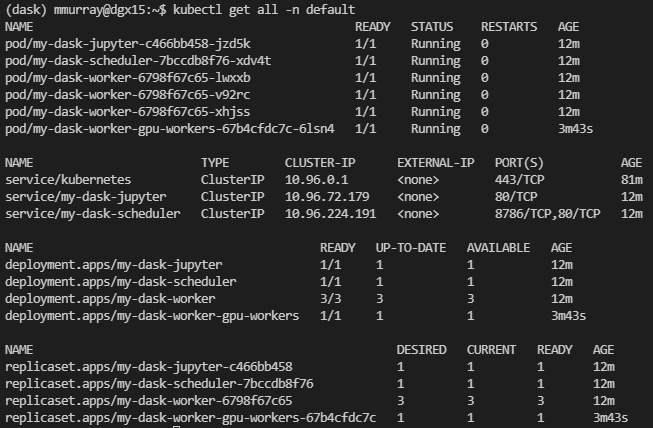
- 现在,我们可以打开一个 Jupyter Notebook 或任何编辑器来编写一些代码。
扩展/收缩 Worker
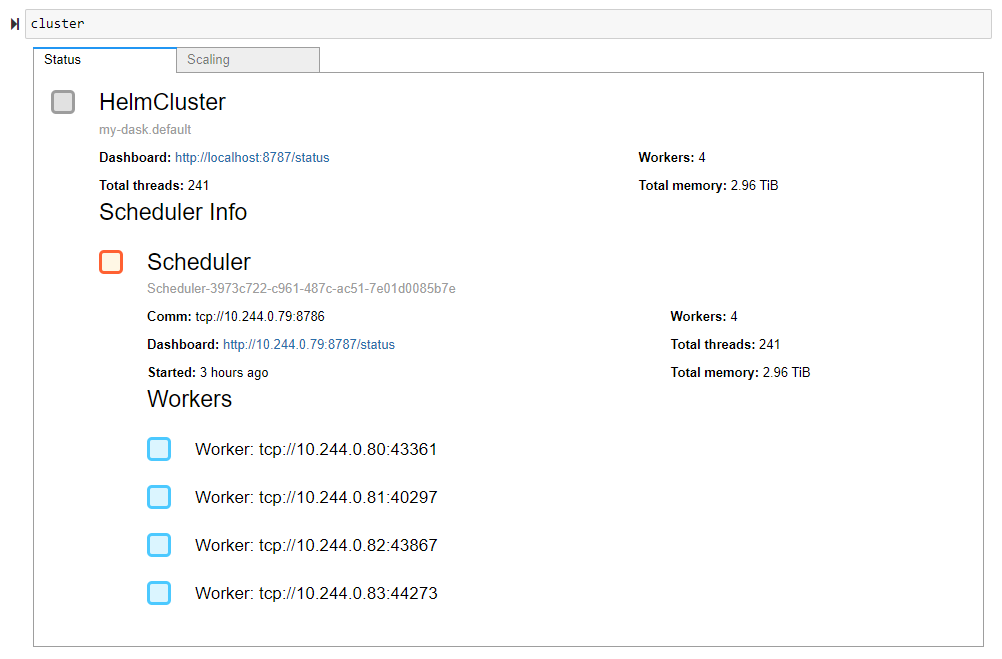
我们首先从 Dask Kubernetes 导入 HelmCluster 集群管理器。接下来,通过传递 Dask 集群的 release_name 作为参数,我们将集群管理器连接到我们的 Dask 集群。就这样,HelmCluster 会自动将调度器端口转发给我们,并使我们能够快速访问日志。接下来,我们将扩展我们的 Dask 集群。
from dask_kubernetes import HelmCluster
cluster = HelmCluster(release_name="my-dask")
cluster
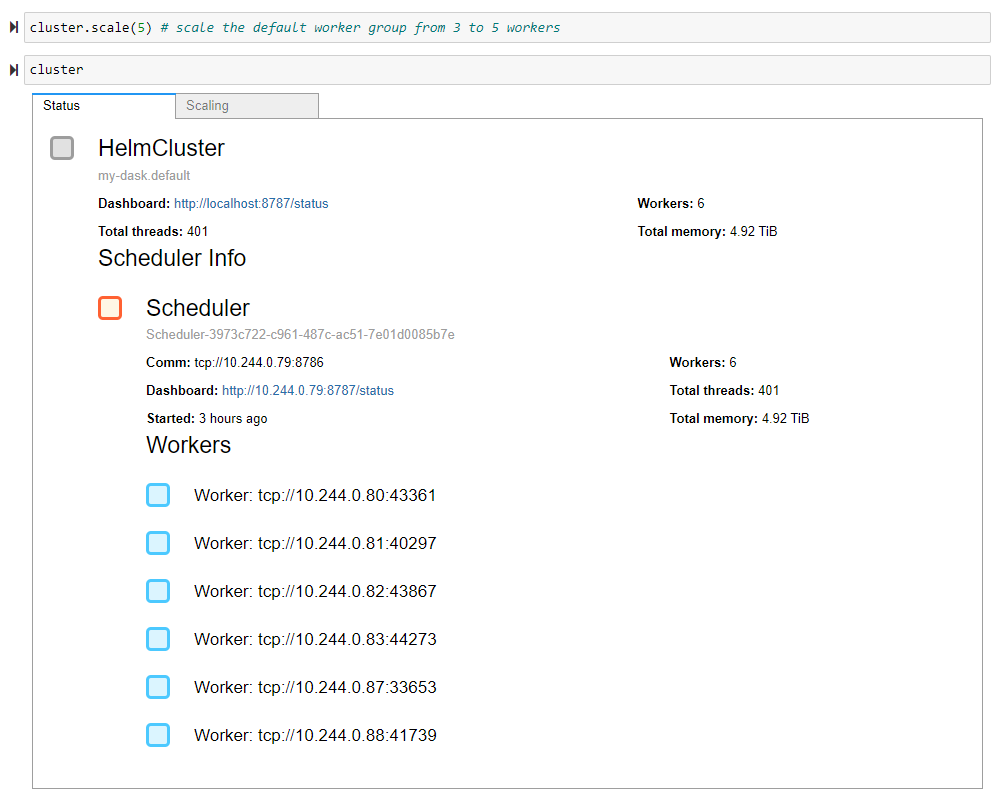
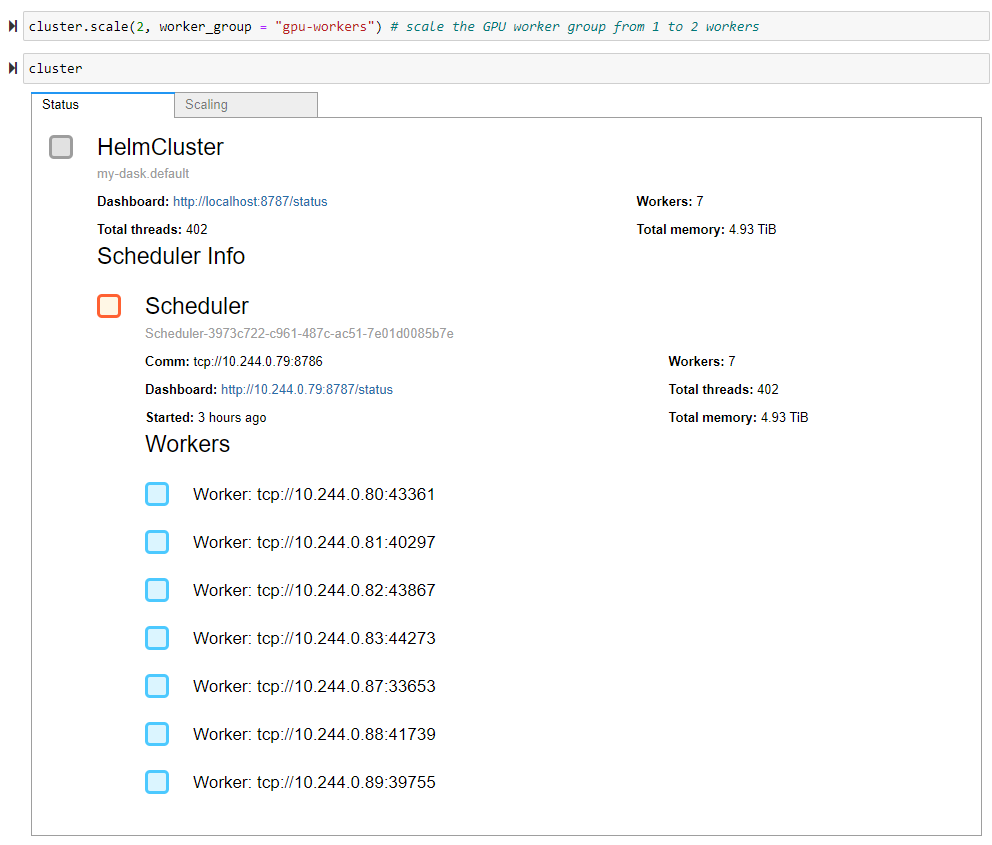
要扩展我们的集群,我们需要将所需的 Worker 数量作为参数提供给 HelmCluster 的 scale 方法。默认情况下,scale 方法会扩展默认 Worker 组。在第一个示例中您可以看到,我们将默认 Worker 组从三个 Worker 扩展到五个 Worker,总共得到六个 Worker。在第二个示例中,我们使用了方便的 worker_group 关键字参数,将我们的 GPU Worker 组从一个 Worker 扩展到两个 Worker,总共得到七个 Worker。
cluster.scale(5) # scale the default worker group from 3 to 5 workers
cluster
cluster.scale(2, worker_group = "gpu-workers") # scale the GPU worker group from 1 to 2 workers
cluster
示例:查找 2020 年 4 月纽约市出租车平均出行距离
本示例将使用纽约出租车数据集查找 2020 年 4 月纽约市黄色出租车的平均出行距离。我们将以两种不同的方式计算此距离。第一种方式将使用我们的默认 Dask Worker,第二种方式将利用我们的 GPU Worker 组。我们将在两个示例中都将纽约出租车数据集加载为数据帧,并计算 trip_distance 列的 mean。主要区别在于,我们需要使用我们的 GPU Worker 组来运行 GPU 上的特定计算。我们可以通过使用 Dask 注释来实现这一点。
import dask.dataframe as dd
import dask
link = "https://s3.amazonaws.com/nyc-tlc/trip+data/yellow_tripdata_2020-04.csv"
ddf = dd.read_csv(link, assume_missing=True)
avg_trip_distance = ddf['trip_distance'].mean().compute()
print(f"In January 2021, the average trip distance for yellow taxis was {avg_trip_distance} miles.")
with dask.annotate(resources={'GPU': 1}):
import dask_cudf, cudf
dask_cdf = ddf.map_partitions(cudf.from_pandas)
avg_trip_distance = dask_cdf['trip_distance'].mean().compute()
print(f"In January 2021, the average trip distance for yellow taxis was {avg_trip_distance} miles.")
总结
就是这样!我们使用 Helm 部署了 Dask,创建了一个额外的 GPU Worker 类型,并使用我们的 Worker 运行了一个使用纽约出租车数据集的示例计算。我们学到了几件新事物
- Dask Helm Chart 允许您创建具有不同 Worker 类型的多个 Worker 组。我们创建两种不同的 Dask Worker 组时看到了这一点:CPU Worker 和 GPU Worker。
- 您可以使用注释在您选择的 Worker 上运行特定的计算。我们的示例在我们的 GPU Worker 组上使用 RAPIDS 库
cudf和dask_cudf计算了平均出租车距离。 - Dask Kubernetes 中的
HelmCluster集群管理器让您可以从 Python 快速扩展您的 Worker 组。我们通过在HelmCluster的 scale 方法中方便地将 Worker 组名称作为关键字参数传递,来扩展了我们的 GPU Worker 组。
未来工作
我们在 Dask 社区中对 Worker 组的概念进行了很多思考。到目前为止,大多数 Dask 部署都是同构的 Worker,但随着 Dask 用户更深入地使用 Dask,对具有专用 Worker 的异构集群的需求越来越大。因此,我们希望在整个 Dask 中添加 Worker 组。
博客评论由 Disqus 提供支持