数据中心间分布式 Dask 集群上的数据就近计算
作者:Duncan McGregor(英国气象局)、Mike Grant(EUMETSAT)、Richard Care(英国气象局)
这项工作是英国气象局与欧洲天气云(欧洲天气云是欧洲中期天气预报中心 (ECMWF) 和欧洲气象卫星组织 (EUMETSAT) 的合作伙伴关系)共同开展的合资项目。
摘要
我们设计了一种技术,用于创建 Dask 集群,其中工作节点分布在不同的数据中心,通过网状 VPN 连接,允许调度器和工作节点进行通信和交换结果。
我们对 Dask 资源进行了新颖的(滥用)使用,使得数据处理任务能够在离源数据最近的集群工作节点上运行,从而最大程度地减少数据中心之间的通信。如果结合 zarr 以访问对象存储中的巨大超立方体数据集,我们相信这项技术可以在云中实现数据就近分布式计算的潜力。
引言
英国气象局一直在与欧洲天气云合作进行一项关于数据就近计算的研究。我们将 Dask 确定为一项关键技术,尽管现有的 Dask 技术主要侧重于单个数据中心内的并行计算,但我们希望将其扩展到跨数据中心的计算。这样,当所需数据托管在多个位置时,任务可以在数据所在的地方运行,而不是复制数据。
Dask 工作节点在网络上交换数据块,由调度器协调。这里有一个假设,即所有节点都可以自由通信,但这在跨数据中心的情况下通常不是真的,因为存在防火墙、NAT 等。因此,一个真正的分布式方法必须解决这个问题。此外,它还必须高效地管理数据传输,因为在数据中心之间移动数据块比在同一云中的工作节点之间移动数据块的成本要高得多。
本笔记本记录了一个正在运行的概念验证,它解决了这些问题。它在三个位置运行计算:
- 这台计算机,运行客户端和调度器。在开发过程中,这台计算机运行在 AWS 上。
- 欧洲中期天气预报中心 (ECMWF) 数据中心。这里有计算资源,并托管包含“预测”的数据。
- 欧洲气象卫星组织 (EUMETSAT) 数据中心,这里有计算资源和关于“观测”的数据。
from IPython.display import Image
Image(filename="images/datacentres.png") # this because GitHub doesn't render markup images in private repos
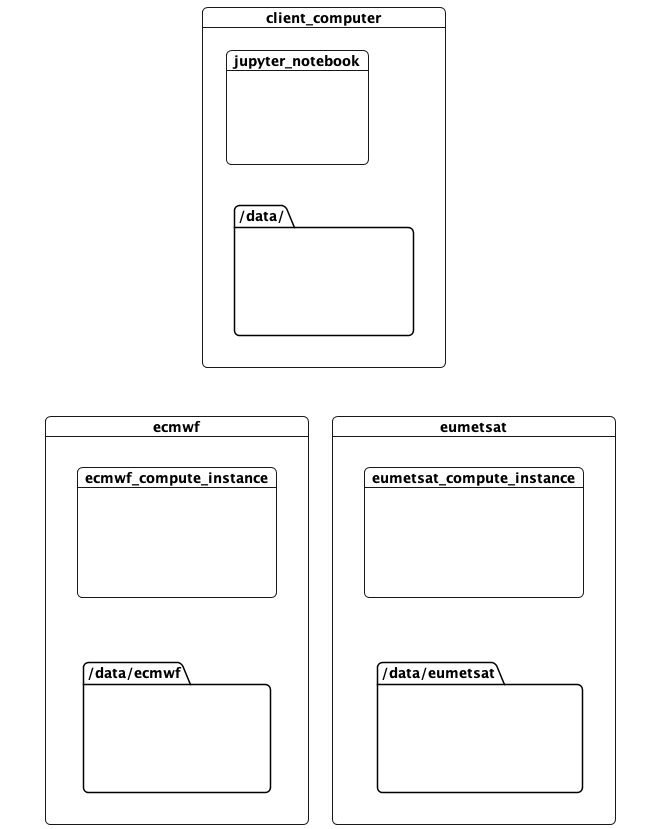
其思想是,访问某个位置可用数据的任务应该在该位置运行。同时,可以在其他地方定义、调用计算并呈现结果。所有这一切都只需要对计算进行最少的提示,说明应该如何完成。
设置
首先进行一些导入和便捷操作
import os
from time import sleep
import dask
from dask.distributed import Client
from dask.distributed import performance_report, get_task_stream
from dask_worker_pools import pool, propagate_pools
import pytest
import ipytest
import xarray
import matplotlib.pyplot as plt
from orgs import my_org
from tree import tree
ipytest.autoconfig()
在这种情况下,我们使用 10.8.0.0/24 上的控制平面 IPv4 WireGuard 网络来设置集群——这并非必需,但简化了本概念验证。WireGuard 对等节点已经在 ECMWF 和 EUMETSAT 机器上运行,但我们必须在这里启动一个。
!./start-wg.sh
4: mo-aws-ec2: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 8921 qdisc noqueue state UNKNOWN group default qlen 1000
link/none
inet 10.8.0.3/24 scope global mo-aws-ec2
valid_lft forever preferred_lft forever
我们在 ECMWF 和 EUMETSAT 都配置了工作机器,各一台。它们在控制平面网络上可访问,如下:
ecmwf_host='10.8.0.4'
%env ECMWF_HOST=$ecmwf_host
eumetsat_host='10.8.0.2'
%env EUMETSAT_HOST=$eumetsat_host
env: ECMWF_HOST=10.8.0.4
env: EUMETSAT_HOST=10.8.0.2
挂载数据
这台机器需要通过网络访问数据文件才能读取 NetCDF 元数据。工作节点正在使用 NFS 共享它们的数据,所以我们在这里挂载它们。(在这个概念验证中,控制平面网络用于 NFS,但数据平面网络同样可以使用,或者使用更合适的技术,例如访问对象存储的 zarr。)
%%bash
sudo ./data-reset.sh
mkdir -p /data/ecmwf
mkdir -p /data/eumetsat
sudo mount $ECMWF_HOST:/data/ecmwf /data/ecmwf
sudo mount $EUMETSAT_HOST:/eumetsatdata/ /data/eumetsat
Image(filename="images/datacentres-data.png")
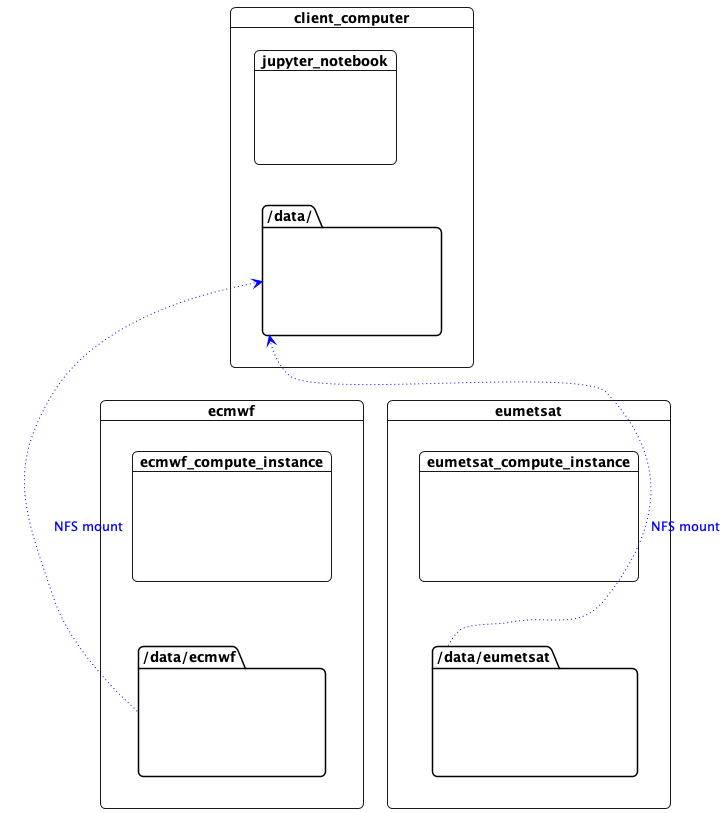
访问数据
对于本次演示,我们有两个需要处理的大型数据文件。在 ECMWF,我们在 /data/ecmwf/000490262cdd067721a34112963bcaa2b44860ab.nc 中有预测数据。在 ECMWF 运行的工作节点可以看到该文件。
!ssh -i ~/.ssh/id_rsa_rcar_infra rcar@$ECMWF_HOST 'tree /data/'
/data/
└── ecmwf
└── 000490262cdd067721a34112963bcaa2b44860ab.nc
1 directory, 1 file
而且由于该目录通过 NFS 挂载到这里,这台计算机也可以看到。
!tree /data/ecmwf
/data/ecmwf
└── 000490262cdd067721a34112963bcaa2b44860ab.nc
0 directories, 1 file
这是一个大文件
!ls -lh /data/ecmwf
total 2.8G
-rw-rw-r-- 1 ec2-user ec2-user 2.8G Mar 25 13:09 000490262cdd067721a34112963bcaa2b44860ab.nc
在 EUMETSAT,我们有 observations.nc
!ssh -i ~/.ssh/id_rsa_rcar_infra rcar@$EUMETSAT_HOST 'tree /data/eumetsat/ad-hoc'
/data/eumetsat/ad-hoc
└── observations.nc
0 directories, 1 file
同样可以在这台计算机上看到
!ls -lh /data/eumetsat/ad-hoc/observations.nc
-rw-rw-r-- 1 613600004 613600004 4.8M May 20 10:57 /data/eumetsat/ad-hoc/observations.nc
至关重要的是,ECMWF 数据在 EUMETSAT 数据中心不可见,反之亦然。
我们的计算
我们想比较预测值和观测值。
我们可以使用 xarray 打开预测文件
predictions = xarray.open_dataset('/data/ecmwf/000490262cdd067721a34112963bcaa2b44860ab.nc').chunk('auto')
predictions
<xarray.Dataset>
Dimensions: (realization: 18, height: 33, latitude: 960,
longitude: 1280, bnds: 2)
Coordinates:
* realization (realization) int32 0 18 19 20 21 ... 31 32 33 34
* height (height) float32 5.0 10.0 20.0 ... 5.5e+03 6e+03
* latitude (latitude) float32 -89.91 -89.72 ... 89.72 89.91
* longitude (longitude) float32 -179.9 -179.6 ... 179.6 179.9
forecast_period timedelta64[ns] 1 days 18:00:00
forecast_reference_time datetime64[ns] 2021-11-07T06:00:00
time datetime64[ns] 2021-11-09
Dimensions without coordinates: bnds
Data variables:
air_pressure (realization, height, latitude, longitude) float32 dask.array<chunksize=(18, 33, 192, 160), meta=np.ndarray>
latitude_longitude int32 -2147483647
latitude_bnds (latitude, bnds) float32 dask.array<chunksize=(960, 2), meta=np.ndarray>
longitude_bnds (longitude, bnds) float32 dask.array<chunksize=(1280, 2), meta=np.ndarray>
Attributes:
history: 2021-11-07T10:27:38Z: StaGE Decoupler
institution: Met Office
least_significant_digit: 1
mosg__forecast_run_duration: PT198H
mosg__grid_domain: global
mosg__grid_type: standard
mosg__grid_version: 1.6.0
mosg__model_configuration: gl_ens
source: Met Office Unified Model
title: MOGREPS-G Model Forecast on Global 20 km St...
um_version: 11.5
Conventions: CF-1.7
在这台机器上运行的 Dask 代码已经通过 NFS 读取了文件的元数据,但尚未读取实际的数据数组。
同样,我们可以看到观测数据,所以我们可以在本地执行计算。在这里,我们将预测数据在实现之间求平均,然后将其与特定高度的观测数据进行比较。(这是一个故意低效的计算,因为我们可以在所需高度处求平均,但你明白重点。)
%%time
def scope():
client = Client()
predictions = xarray.open_dataset('/data/ecmwf/000490262cdd067721a34112963bcaa2b44860ab.nc').chunk('auto')
observations = xarray.open_dataset('/data/eumetsat/ad-hoc/observations.nc').chunk('auto')
averages = predictions.mean('realization')
diff = averages.isel(height=10) - observations
diff.compute()
#scope()
CPU times: user 10 µs, sys: 2 µs, total: 12 µs
Wall time: 13.8 µs
当我们取消注释 scope() 并实际运行时,它需要 14 分钟以上才能完成!通过数据中心之间(我们在 AWS 中运行此笔记本)的 NFS 访问数据实在太慢了。
事实上,仅仅将数据文件复制到运行此笔记本的计算机上就需要相同的时间。至少 2.8 GiB + 4.8 MiB 的数据必须从数据中心传输到此机器才能执行计算。
相反,我们显然应该在数据所在的位置运行 Dask 任务。我们可以在 Dask 集群上做到这一点。
启动集群
集群通过一条命令启动。不过需要一些时间
import subprocess
scheduler_process = subprocess.Popen([
'../dask_multicloud/dask-boot.sh',
f"rcar@{ecmwf_host}",
f"rcar@{eumetsat_host}"
])
[#] ip link add dasklocal type wireguard
[#] wg setconf dasklocal /dev/fd/63
[#] ip -6 address add fda5:c0ff:eeee:0::1/64 dev dasklocal
[#] ip link set mtu 1420 up dev dasklocal
[#] ip -6 route add fda5:c0ff:eeee:2::/64 dev dasklocal
[#] ip -6 route add fda5:c0ff:eeee:1::/64 dev dasklocal
2022-06-29 14:46:57,237 - distributed.scheduler - INFO - -----------------------------------------------
2022-06-29 14:46:58,602 - distributed.http.proxy - INFO - To route to workers diagnostics web server please install jupyter-server-proxy: python -m pip install jupyter-server-proxy
2022-06-29 14:46:58,643 - distributed.scheduler - INFO - -----------------------------------------------
2022-06-29 14:46:58,644 - distributed.scheduler - INFO - Clear task state
2022-06-29 14:46:58,646 - distributed.scheduler - INFO - Scheduler at: tcp://172.17.0.2:8786
2022-06-29 14:46:58,646 - distributed.scheduler - INFO - dashboard at: :8787
2022-06-29 14:47:16,104 - distributed.scheduler - INFO - Register worker <WorkerState 'tcp://[fda5:c0ff:eeee:1::11]:37977', name: ecmwf-1-2, status: undefined, memory: 0, processing: 0>
2022-06-29 14:47:16,107 - distributed.scheduler - INFO - Starting worker compute stream, tcp://[fda5:c0ff:eeee:1::11]:37977
2022-06-29 14:47:16,108 - distributed.core - INFO - Starting established connection
2022-06-29 14:47:16,108 - distributed.scheduler - INFO - Register worker <WorkerState 'tcp://[fda5:c0ff:eeee:1::11]:44575', name: ecmwf-1-3, status: undefined, memory: 0, processing: 0>
2022-06-29 14:47:16,109 - distributed.scheduler - INFO - Starting worker compute stream, tcp://[fda5:c0ff:eeee:1::11]:44575
2022-06-29 14:47:16,109 - distributed.core - INFO - Starting established connection
2022-06-29 14:47:16,113 - distributed.scheduler - INFO - Register worker <WorkerState 'tcp://[fda5:c0ff:eeee:1::11]:40121', name: ecmwf-1-1, status: undefined, memory: 0, processing: 0>
2022-06-29 14:47:16,114 - distributed.scheduler - INFO - Starting worker compute stream, tcp://[fda5:c0ff:eeee:1::11]:40121
2022-06-29 14:47:16,114 - distributed.core - INFO - Starting established connection
2022-06-29 14:47:16,119 - distributed.scheduler - INFO - Register worker <WorkerState 'tcp://[fda5:c0ff:eeee:1::11]:40989', name: ecmwf-1-0, status: undefined, memory: 0, processing: 0>
2022-06-29 14:47:16,121 - distributed.scheduler - INFO - Starting worker compute stream, tcp://[fda5:c0ff:eeee:1::11]:40989
2022-06-29 14:47:16,121 - distributed.core - INFO - Starting established connection
2022-06-29 14:47:23,342 - distributed.scheduler - INFO - Register worker <WorkerState 'tcp://[fda5:c0ff:eeee:2::11]:33423', name: eumetsat-2-0, status: undefined, memory: 0, processing: 0>
2022-06-29 14:47:23,343 - distributed.scheduler - INFO - Starting worker compute stream, tcp://[fda5:c0ff:eeee:2::11]:33423
2022-06-29 14:47:23,343 - distributed.core - INFO - Starting established connection
2022-06-29 14:47:23,346 - distributed.scheduler - INFO - Register worker <WorkerState 'tcp://[fda5:c0ff:eeee:2::11]:43953', name: eumetsat-2-1, status: undefined, memory: 0, processing: 0>
2022-06-29 14:47:23,348 - distributed.scheduler - INFO - Starting worker compute stream, tcp://[fda5:c0ff:eeee:2::11]:43953
2022-06-29 14:47:23,348 - distributed.core - INFO - Starting established connection
2022-06-29 14:47:23,350 - distributed.scheduler - INFO - Register worker <WorkerState 'tcp://[fda5:c0ff:eeee:2::11]:46089', name: eumetsat-2-3, status: undefined, memory: 0, processing: 0>
2022-06-29 14:47:23,352 - distributed.scheduler - INFO - Starting worker compute stream, tcp://[fda5:c0ff:eeee:2::11]:46089
2022-06-29 14:47:23,352 - distributed.core - INFO - Starting established connection
2022-06-29 14:47:23,357 - distributed.scheduler - INFO - Register worker <WorkerState 'tcp://[fda5:c0ff:eeee:2::11]:43727', name: eumetsat-2-2, status: undefined, memory: 0, processing: 0>
2022-06-29 14:47:23,358 - distributed.scheduler - INFO - Starting worker compute stream, tcp://[fda5:c0ff:eeee:2::11]:43727
2022-06-29 14:47:23,358 - distributed.core - INFO - Starting established connection
我们需要等待 8 行 distributed.core - INFO - Starting established connection —— 每台工作机器上的 4 个工作进程各一条。
这里发生了什么:
start-scheduler.sh在这台计算机上启动一个 Docker 容器。- 该容器创建一个 WireGuard IPv6 数据平面 VPN。这涉及为所有节点生成共享密钥以及容器内部的网络接口。这个数据平面 VPN 是临时的,并且对于此集群是唯一的。
- 该容器运行一个 Dask 调度器,托管在数据平面网络上。
- 然后它要求每个数据中心配置工作节点和路由。
每个数据中心托管一个控制进程,可通过控制平面网络访问。调用时:
- 控制进程在数据平面网络上创建一个 WireGuard 网络接口。它充当数据中心内的工作节点和调度器之间的路由器。
- 它在计算实例上启动 Docker 容器。这些容器在数据平面网络上拥有自己的 WireGuard 网络接口,通过控制进程实例进行路由。
- Docker 容器生成(4 个)Dask 工作进程,每个进程通过数据平面网络连接回开始时创建的调度器。
结果是这台计算机上的一个容器运行调度器,通过一个一次性的数据平面 WireGuard IPv6 网络与每台工作机器上的一个容器通信,该网络允许每个(本例中为 8 个)Dask 工作进程相互通信并与调度器通信,即使它们分布在 3 个数据中心。
大概是这样的
Image(filename="images/datacentres-dask.png")
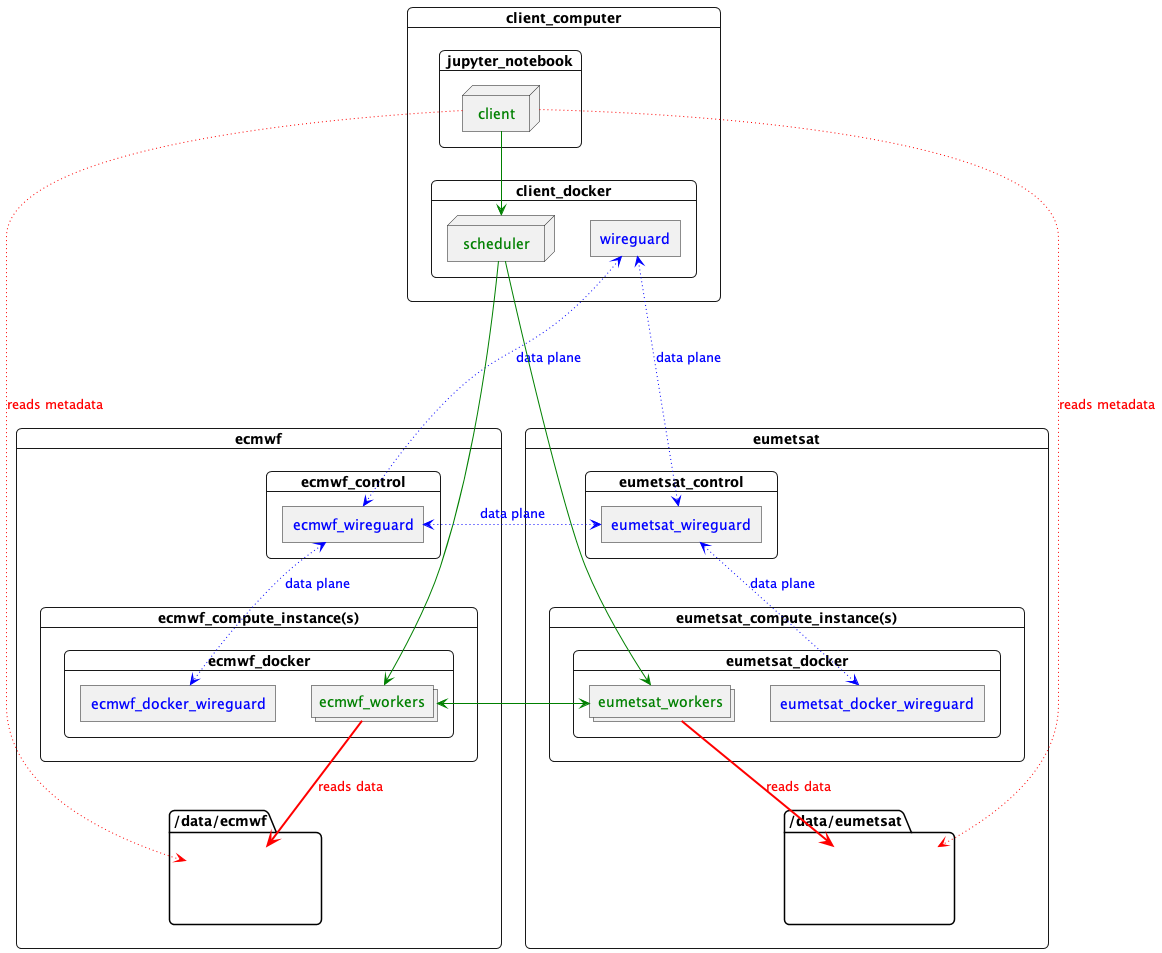
图例
- 数据平面网络
- Dask
- NetCDF 数据
连接到集群
集群的调度器现在运行在这台机器的一个 Docker 容器中,并暴露在 localhost 上,所以我们可以创建一个客户端与之通信
client = Client("localhost:8786")
2022-06-29 14:47:35,535 - distributed.scheduler - INFO - Receive client connection: Client-69f22f41-f7ba-11ec-a0a2-0acd18a5c05a
2022-06-29 14:47:35,536 - distributed.core - INFO - Starting established connection
/home/ec2-user/miniconda3/envs/jupyter/lib/python3.10/site-packages/distributed/client.py:1287: VersionMismatchWarning: Mismatched versions found
+---------+--------+-----------+---------+
| Package | client | scheduler | workers |
+---------+--------+-----------+---------+
| msgpack | 1.0.4 | 1.0.3 | 1.0.3 |
| numpy | 1.23.0 | 1.22.3 | 1.22.3 |
| pandas | 1.4.3 | 1.4.2 | 1.4.2 |
+---------+--------+-----------+---------+
Notes:
- msgpack: Variation is ok, as long as everything is above 0.6
warnings.warn(version_module.VersionMismatchWarning(msg[0]["warning"]))
如果您点击客户端,您应该在 Scheduler Info 节点下看到工作节点。
# client
您还可以点击转到 https://:8787/status 上的仪表盘。在那里我们可以查看任务流上的工作节点。
def show_all_workers():
my_org().compute(workers='ecmwf-1-0')
my_org().compute(workers='ecmwf-1-1')
my_org().compute(workers='ecmwf-1-2')
my_org().compute(workers='ecmwf-1-3')
my_org().compute(workers='eumetsat-2-0')
my_org().compute(workers='eumetsat-2-1')
my_org().compute(workers='eumetsat-2-2')
my_org().compute(workers='eumetsat-2-3')
sleep(0.5)
show_all_workers()
在集群上运行
现在 Dask 客户端在范围内,计算将在集群上运行。我们可以定义要运行的任务
predictions = xarray.open_dataset('/data/ecmwf/000490262cdd067721a34112963bcaa2b44860ab.nc').chunk('auto')
observations = xarray.open_dataset('/data/eumetsat/ad-hoc/observations.nc').chunk('auto')
averages = predictions.mean('realization')
diff = averages.isel(height=10) - observations
但是当我们尝试执行计算时,它失败了
with pytest.raises(FileNotFoundError) as excinfo:
show_all_workers()
diff.compute()
str(excinfo.value)
"[Errno 2] No such file or directory: b'/data/eumetsat/ad-hoc/observations.nc'"
它失败了,因为 Dask 调度器将一些读取数据的任务发送到了在 EUMETSAT 运行的工作节点。它们无法看到 ECMWF 中的数据,我们也不希望它们看到,因为在数据中心之间读取所有这些数据会太慢。
数据就近计算
Dask 拥有资源的概念。任务可以被安排只在某个资源(如 GPU 或内存大小)可用时运行。我们可以滥用这种机制,将任务固定到某个数据中心,将数据中心视为一种资源。
为此,当创建工作节点时,我们将它们标记为拥有 pool-ecmwf 或 pool-eumetsat 资源。然后,当我们要创建只能在一个数据中心运行的任务时,我们标记它们需要相应的资源:
with (dask.annotate(resources={'pool-ecmwf': 1})):
predictions.mean('realization').isel(height=10).compute()
我们可以将这些样板代码隐藏在一个 Python 上下文管理器 pool 内部,然后这样写:
with pool('ecmwf'):
predictions.mean('realization').isel(height=10).compute()
pool 上下文管理器是与 Dask 开发者合作完成的,并发布在 GitHub 上。您可以在Dask Discourse上阅读更多关于该概念演变的信息。
不过,我们可以做得比注释计算任务更好。如果我们在上下文管理器块内部加载数据,数据加载任务将携带该注释:
with pool('ecmwf'):
predictions = xarray.open_dataset('/data/ecmwf/000490262cdd067721a34112963bcaa2b44860ab.nc').chunk('auto')
在这种情况下,我们需要库中的另一个上下文管理器 propagate_pools,以确保在处理和执行任务图时不会丢失注释。
with propagate_pools():
predictions.mean('realization').isel(height=10).compute()
这两个上下文管理器允许我们用数据所属的池标记数据,从而标记加载任务将在何处运行。
with pool('ecmwf'):
predictions = xarray.open_dataset('/data/ecmwf/000490262cdd067721a34112963bcaa2b44860ab.nc').chunk('auto')
with pool('eumetsat'):
observations = xarray.open_dataset('/data/eumetsat/ad-hoc/observations.nc').chunk('auto')
定义一些不关心数据来源的延迟计算:
averaged_predictions = predictions.mean('realization')
diff = averaged_predictions.isel(height=10) - observations
然后执行最终计算:
%%time
with propagate_pools():
show_all_workers()
diff.compute()
CPU times: user 127 ms, sys: 6.34 ms, total: 133 ms
Wall time: 4.88 s
记住,我们的目标是在数据中心之间分布计算,同时防止工作节点读取外部的大量数据。
在这里,我们知道数据只由适当位置的工作节点读取,因为任何一个数据中心都无法读取另一个数据中心的数据。一旦数据载入内存,Dask 更倾向于在拥有数据的节点上调度任务,这样本地工作节点倾向于执行后续计算,数据块倾向于保留在读取它们的数据中心。
然而,通常情况下,如果工作节点空闲,Dask 会使用它们来执行计算,即使它们没有数据。如果允许这样做,这种工作窃取会导致数据在数据中心之间不必要地移动,这是一个可能昂贵的操作。propagate_pools 上下文管理器会安装一个调度器优化,阻止不同池之间的工作窃取,以防止这种情况发生。
一旦一个池中加载的数据需要与来自另一个池的数据结合(上面 averaged_predictions.isel(height=10) - observations 中的减法操作),这就不再被归类为工作窃取,Dask 会根据需要移动数据在数据中心之间。
一次性完成的计算看起来是这样的:
%%time
with pool('ecmwf'):
predictions = xarray.open_dataset('/data/ecmwf/000490262cdd067721a34112963bcaa2b44860ab.nc').chunk('auto')
with pool('eumetsat'):
observations = xarray.open_dataset('/data/eumetsat/ad-hoc/observations.nc').chunk('auto')
averages = predictions.mean('realization')
diff = averages.isel(height=10) - observations
with propagate_pools():
show_all_workers()
plt.figure(figsize=(6, 6))
plt.imshow(diff.to_array()[0,...,0], origin='lower')
CPU times: user 234 ms, sys: 27.6 ms, total: 261 ms
Wall time: 6.04 s

就代码而言,与上面的本地版本相比,这只增加了 with 块的使用来标记数据和管理执行,执行速度提高了约 100 倍。
这是最好的情况,因为在演示中,文件实际上托管在工作机器上,因此本地读取文件与通过 NFS 读取文件的速度差异最大化了。也许更有说服力的是测量的网络流量。
| 方法 | 所需时间 | 测量的网络流量 |
|---|---|---|
| 通过 NFS 计算 | > 14 分钟 | 2.8 GiB |
| 分布式计算 | 约 10 秒 | 8 MiB |
除了一些控制和状态消息外,只有绘制图像所需的数据通过网络发送到这台计算机。
查看任务流,我们看到 ECMWF 工作节点(底部)完成了大部分读取和计算工作,红色的传输任务将这些结果与 EUMETSAT 的数据结合起来。
Image(filename="images/task-graph.png")
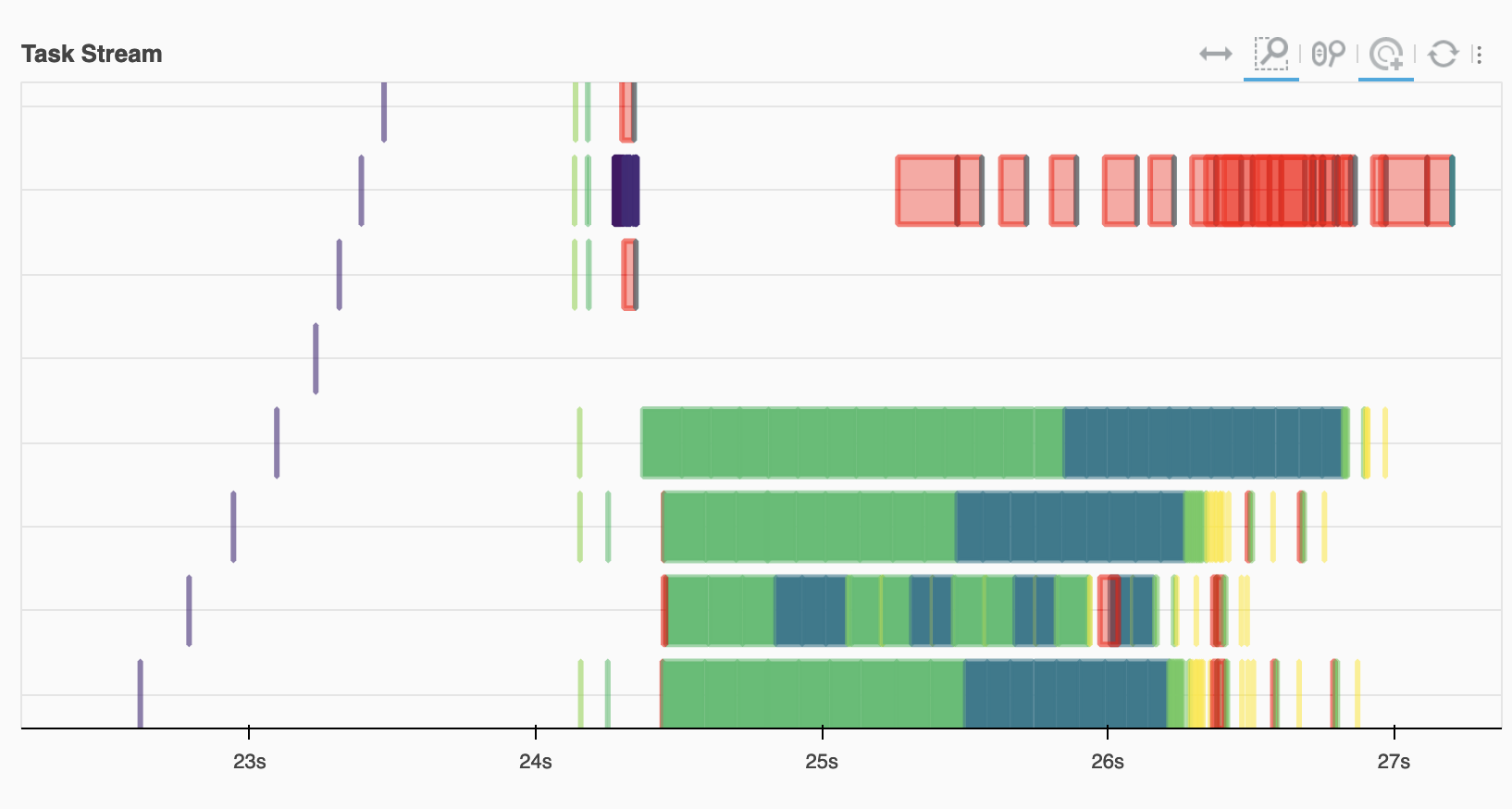
数据目录
我们可以进一步简化这段代码。因为数据加载任务已经标记了它们所属的资源池,所以这对科学家来说可以是透明的。因此我们可以这样写:
def load_from_catalog(path):
with pool(path.split('/')[2]):
return xarray.open_dataset(path).chunk('auto')
这使我们能够忽略数据的来源
predictions = load_from_catalog('/data/ecmwf/000490262cdd067721a34112963bcaa2b44860ab.nc')
observations = load_from_catalog('/data/eumetsat/ad-hoc/observations.nc')
averages = predictions.mean('realization')
diff = averages.isel(height=10) - observations
with propagate_pools():
show_all_workers()
diff.compute()
当然,集群必须在相应的数据中心配置计算资源,尽管稍作努力就可以通过数据目录代码使其成为动态的。
更多信息
此笔记本及其背后的代码发布在GitHub 存储库中。
有关原型实现的详细信息和增强思路,请参见dask-multi-cloud-details.ipynb。
致谢
感谢 Armagan Karatosun (EUMETSAT) 和 Vasileios Baousis (ECMWF) 在支持此概念验证的基础设施方面提供的帮助和支持。Gabe Joseph (Coiled) 编写了巧妙的池上下文管理器,Jacob Tomlinson (NVIDIA) 审阅了本文档。
© 版权所有 2022
博客评论由 Disqus 提供支持