理解 Dask 的 meta 关键字参数
作者:Pavithra Eswaramoorthy
如果你曾经使用过 Dask DataFrame 或 Dask Array,你可能遇到过 meta 关键字参数。也许是在使用 apply() 等方法时。
import dask
import pandas as pd
ddf = dask.datasets.timeseries()
def my_custom_arithmetic(r):
if r.id > 1000:
return r.x * r.x + r.y + r.y
else:
return 0
ddf["my_computation"] = ddf.apply(
my_custom_arithmetic, axis=1, meta=pd.Series(dtype="float64")
)
ddf.head()
# Output:
#
# id name x y my_computation
# timestamp
# 2000-01-01 00:00:00 1055 Victor -0.575374 0.868320 2.067696
# 2000-01-01 00:00:01 994 Zelda 0.963684 0.972240 0.000000
# 2000-01-01 00:00:02 982 George -0.997531 -0.876222 0.000000
# 2000-01-01 00:00:03 981 Ingrid 0.852159 -0.419733 0.000000
# 2000-01-01 00:00:04 1029 Jerry -0.839431 -0.736572 -0.768500
你可能还见过以下一个或多个警告/错误:
UserWarning: You did not provide metadata, so Dask is running your function on a small dataset to guess output types. It is possible that Dask will guess incorrectly.
UserWarning: `meta` is not specified, inferred from partial data. Please provide `meta` if the result is unexpected.
ValueError: Metadata inference failed in …
如果上面的信息你看起来很熟悉,那么这篇博文就是为你准备的。:)
我们将讨论
meta关键字参数是什么,- Dask 为什么需要
meta,以及 - 如何有效使用它。
我们将主要在 Dask DataFrame 的上下文中讨论 meta,不过类似的原则也适用于 Dask Array。
meta 是什么?
在回答这个问题之前,让我们快速讨论一下 Dask DataFrame。
Dask DataFrame 是一个惰性对象,由多个 pandas DataFrame 组成,其中每个 pandas DataFrame 称为一个“分区”(partition)。这些分区沿索引堆叠,Dask 使用“分段”(divisions)来跟踪这些分区,分段是一个元组,表示每个分区的起始和结束索引。

当你创建一个 Dask DataFrame 时,通常会看到如下内容
>>> import pandas as pd
>>> import dask.dataframe as dd
>>> ddf = dd.DataFrame.from_dict(
... {
... "x": range(6),
... "y": range(10, 16),
... },
... npartitions=2,
... )
>>> ddf
Dask DataFrame Structure:
x y
npartitions=2
0 int64 int64
3 ... ...
5 ... ...
Dask Name: from_pandas, 2 tasks
在这里,Dask 使用关于列名及其数据类型的一些“元数据”信息创建了 DataFrame 的结构。这种元数据信息就称为 meta。Dask 使用 meta 来理解 Dask 操作并创建准确的任务图(即,你的计算逻辑)。
在各种 Dask DataFrame 函数中,meta 关键字参数允许你显式地与 Dask 共享此元数据信息。请注意,该关键字参数与这些函数输出的元数据有关。
Dask 为什么需要 meta?
Dask 计算是惰性评估的。这意味着 Dask 会立即创建计算的逻辑和流程,称为任务图,但只有在必要时才会评估它们——通常是在调用 .compute() 时。
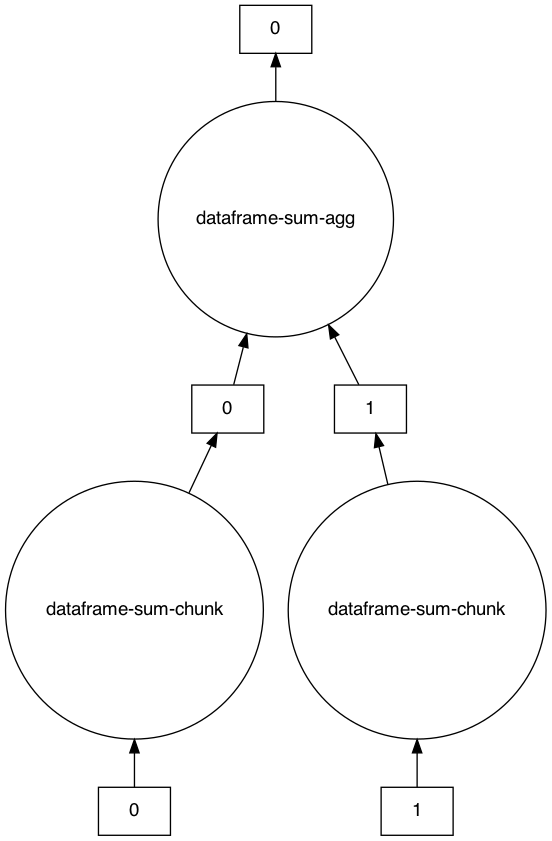
计算 DataFrame 总和生成的任务图示例
>>> s = ddf.sum()
>>> s
Dask Series Structure:
npartitions=1
x int64
y ...
dtype: int64
Dask Name: dataframe-sum-agg, 5 tasks
>>> s.visualize()
>>> s.compute()
x 15
y 75
dtype: int64
这是一个单一操作,但 Dask 工作流程通常包含多个此类操作链式组合。因此,为了有效创建任务图,Dask 需要知道每次操作后 DataFrame 的结构和数据类型。特别是因为 Dask 此时还不知道 DataFrame 的实际值/结构。
这就是 meta 发挥作用的地方。
在上面的示例中,Dask DataFrame 在执行 sum() 后变成了 Series。Dask 知道这一点(甚至在我们调用 compute() 之前)正是因为 meta。
在内部,meta 表示为一个空的 pandas DataFrame 或 Series,其结构与 Dask DataFrame 相同。要了解更多关于 meta 在内部如何定义的信息,请查阅 DataFrame 内部设计文档。
要查看集合的实际元数据信息,你可以查看 ._meta 属性[1]
>>> s._meta
Series([], dtype: int64)
如何指定 meta?
你可以通过几种不同的方式指定 meta,但对于 Dask DataFrame,推荐的方式是
“一个空的
pd.DataFrame或pd.Series,其数据类型和列名与输出匹配。”
例如
>>> meta_df = pd.DataFrame(columns=["x", "y"], dtype=int)
>>> meta_df
Empty DataFrame
Columns: [x, y]
Index: []
>>> ddf2 = ddf.apply(lambda x: x, axis=1, meta=meta_df).compute()
>>> ddf2
x y
0 0 0
1 1 1
2 2 2
3 0 3
4 1 4
5 2 5
-
对于 DataFrame,你可以将
meta指定为- Python 字典:
{column_name_1: dtype_1, column_name_2: dtype_2, …} - 元组可迭代对象:
[(column_name_1, dtype_1), (columns_name_2, dtype_2, …)]
注意:如上所示,在使用字典或元组可迭代对象描述
meta时,提及列名的顺序很重要。Dask 将使用相同的顺序来为meta创建 pandas DataFrame。如果顺序不匹配,你将看到以下错误ValueError: The columns in the computed data do not match the columns in the provided metadata - Python 字典:
-
对于 Series 输出,你可以使用单个元组指定
meta:(coulmn_name, dtype)
你不应只使用一个 dtype 来描述 meta(例如:meta="int64"),即使是对于标量输出。如果这样做,你将看到以下警告
FutureWarning: Meta is not valid, `map_partitions` and `map_overlap` expects output to be a pandas object. Try passing a pandas object as meta or a dict or tuple representing the (name, dtype) of the columns. In the future the meta you passed will not work.
在像 map_partitions 或 apply(其内部使用 map_partitions)这样的操作中,Dask 会将每个分区的标量输出强制转换为 pandas 对象。因此,接受 meta 参数的函数的输出永远不会是标量。
例如
>>> ddf = ddf.repartition(npartitions=1)
>>> result = ddf.map_partitions(lambda x: len(x)).compute()
>>> type(result)
pandas.core.series.Series
在这里,Dask DataFrame ddf 只有一个分区。因此,对该分区执行 len(x) 会产生一个整数数据类型的标量输出。然而,当我们计算它时,我们看到的是一个 pandas Series。这证实了 Dask 正在将输出强制转换为 pandas 对象。
另请注意,Dask Array 可能并非总是执行此转换。你可以查阅特定 Array 操作的 API 参考获取详细信息。
>>> import numpy as np
>>> import dask.array as da
>>> my_arr = da.random.random(10)
>>> my_arr.map_blocks(lambda x: len(x)).compute()
10
meta 不会强制结构或数据类型
meta 可以被视为对 Dask 的一个建议。Dask 使用这个 meta 来生成任务图,直到它可以从实际值中推断出真实的元数据。它不会强制输出具有指定的 meta 所描述的结构或数据类型。
考虑以下示例,请记住我们在前几节中定义 ddf 时使用了 x 和 y 列名。
如果我们在 meta 描述中提供了不同的列名(a 和 b),Dask 会使用这些新名称来创建任务图
>>> meta_df = pd.DataFrame(columns=["a", "b"], dtype=int)
>>> result = ddf.apply(lambda x:x*x, axis=1, meta=meta_df)
>>> result
Dask DataFrame Structure:
a b
npartitions=2
0 int64 int64
3 ... ...
5 ... ...
Dask Name: apply, 4 tasks
然而,如果我们计算 result,我们将得到以下错误
>>> result.compute()
ValueError: The columns in the computed data do not match the columns in the provided metadata
Extra: ['x', 'y']
Missing: ['a', 'b']
在计算时,Dask 会评估具有 x 和 y 列的实际元数据。这与我们提供的 meta 不匹配,因此 Dask 会引发一个有用的错误消息。请注意 Dask 在这里并没有将输出更改为包含 a 和 b,而只是将 a 和 b 用作中间任务图的列名。
直接使用 ._meta
在某些罕见情况下,你也可以直接为 Dask DataFrame 设置 ._meta 属性[1]。例如,如果 DataFrame 以不正确的数据类型创建,如下所示
>>> ddf = dd.DataFrame.from_dict(
... {
... "x": range(6),
... "y": range(10, 16),
... },
... dtype="object", # Note the “object” dtype
... npartitions=2,
... )
>>> ddf
Dask DataFrame Structure:
x y
npartitions=2
0 object object
3 ... ...
5 ... ...
Dask Name: from_pandas, 2 tasks
值明显是整数,但数据类型显示为 object,因此我们无法执行加法等整数操作
>>> add = ddf + 2
ValueError: Metadata inference failed in `add`.
Original error is below:
------------------------
TypeError('can only concatenate str (not "int") to str')
在这里,我们可以显式定义 ._meta[1]
>>> ddf._meta = pd.DataFrame(columns=["x", "y"], dtype="int64")
然后,执行加法
>>> add = ddf + 2
>>> add
Dask DataFrame Structure:
x y
npartitions=2
0 int64 int64
3 ... ...
5 ... ...
Dask Name: add, 4 tasks
感谢阅读!
你之前遇到过与 meta 相关的问题吗?请在 Discourse 上告知我们,我们将考虑将其包含在此处,或更新 Dask 文档。:)
[1] 注意:._meta 不是一个公有属性,因此我们建议仅在必要时使用它。目前有一项正在进行的讨论,关于创建公有方法来获取、设置和查看 ._meta 中的信息,当这些公有方法创建后,这篇博文将更新以使用它们。
博客评论由 Disqus 提供支持