Dask Kubernetes Operator
作者:Jacob Tomlinson (NVIDIA)
我们很高兴地宣布,Dask Kubernetes Operator 现已正式发布 🎉!
值得注意的新功能包括:
- Dask 集群现在是 原生自定义资源
- 集群可以使用
kubectl或 Python API 进行管理 - 级联删除允许正确地销毁资源
- 多个 工作节点组 支持异构/标记部署
- DaskJob:使用 K8s 批处理作业基础设施运行 Dask 工作负载
- 集群可以在不同的 Python 进程之间复用
- 自动伸缩 由自定义 Kubernetes 控制器处理,而不是用户代码
- 调度器和工作节点 Pods 以及 Services 是 完全可配置的
$ kubectl get daskcluster
NAME AGE
my-cluster 4m3s
$ kubectl get all -A -l dask.org/cluster-name=my-cluster
NAMESPACE NAME READY STATUS RESTARTS AGE
default pod/my-cluster-default-worker-22bd39e33a 1/1 Running 0 3m43s
default pod/my-cluster-default-worker-5f4f2c989a 1/1 Running 0 3m43s
default pod/my-cluster-default-worker-72418a589f 1/1 Running 0 3m43s
default pod/my-cluster-default-worker-9b00a4e1fd 1/1 Running 0 3m43s
default pod/my-cluster-default-worker-d6fc172526 1/1 Running 0 3m43s
default pod/my-cluster-scheduler 1/1 Running 0 4m21s
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default service/my-cluster-scheduler ClusterIP 10.96.33.67 <none> 8786/TCP,8787/TCP 4m21s
在 2022 年初,我们开始了一项大型工作,即以 Operator 模式 重写 dask-kubernetes 包。这种设计模式在 Kubernetes 社区中变得非常流行,像 红帽(Red Hat)这样的公司将其整个 Kubernetes 产品 Openshift 都围绕它构建。
什么是 Operator?
如果您在 Kubernetes 社区待过一段时间,就会听到“Operator”这个术语被频繁提及,也会看到像 Golang 的 Operator Framework 这样的项目被用来部署现代应用程序。
Operator 的核心由两部分组成:一个用于描述您想要部署的事物(在我们的例子中是一个 Dask 集群)的数据结构,以及一个负责实际部署的控制器。在 Kubernetes 中,这些数据结构的模板称为 自定义资源定义(Custom Resource Definitions,CRDs),它们允许您使用自己设计的新的资源类型来扩展 Kubernetes API。
对于 dask-kubernetes,我们创建了一些 CRDs 来描述 Dask 集群、Dask 工作节点组、自适应自动伸缩器 以及新的 Dask 支持的批处理作业 等。
我们还使用 kopf 构建了一个控制器,它负责监视这些资源的更改,并创建/更新/删除较低级别的 Kubernetes 资源,如 Pods 和 Services。
我们为什么要构建它?
最初的 dask-kubernetes 实现 在 Kubernetes 发布 1.0 后不久,在任何成熟的设计模式出现之前就开始了。它的模型基于将 Dask 工作节点作为子进程生成,只不过这些子进程是在 Kubernetes 中运行的 Pods。这与 dask-jobqueue 将工作节点作为独立的作业调度器分配启动,或 dask-ssh 打开多个 SSH 连接到各种机器的方式相同。
随着时间的推移,这一实现被多次重构、重写和扩展。一个长期以来被要求进行更改的地方是也将 Dask 调度器放置在 Kubernetes 集群内部,以简化调度器与工作节点之间的通信和网络连接。这自然带来了更多关于配置调度器服务和对集群有更多控制的功能请求。随着我们不断扩展,在远程系统上生成工作节点子进程的原始前提变得越来越没有帮助。
原始设计的最后一根稻草是有人询问是否可以将集群保持运行,稍后再回来使用。无论是为了在不同的独立作业之间复用集群,还是仅仅为了多阶段流水线中的不同阶段。生成子进程的前提导致了一个假设:父进程将在集群的生命周期内存在,这使得它成为保存状态的合理位置,例如用于在扩缩容时启动新工作节点的模板。我们尝试实现这个功能,但在当前设计下这是不可能的。转向一个父进程可以终止而新的进程可以接管的模型意味着状态需要移动到其他地方,而事物耦合得太紧密,无法成功地将其剥离出来。
服务我们如此之久、表现良好的经典实现已经步履维艰,越来越难以修改和维护。是时候通过在一个新模型——Operator 模式下从头开始重建,来偿还我们的技术债务了。
在这个新模型中,Dask 集群是存在于 Kubernetes 集群中的一个抽象对象。我们使用自定义资源来存储每个集群的状态,并使用自定义控制器通过创建组成集群的各个组件,将该状态映射到实际。想要扩缩容您的集群?不再是本地 Python 代码在 Kubernetes 上启动一个新的 Pod,我们只需修改 Dask 集群资源的状态,指定期望的工作节点数量,控制器就会处理添加/删除 Pods 以匹配该数量。
新功能
虽然我们的主要目标是允许在 Python 进程之间复用集群并偿还技术债务,但切换到 Operator 模式使我们能够添加一系列令人满意的新功能。接下来让我们探索这些功能。
Python 或 YAML API
通过我们的新实现,我们通过在 Kubernetes 集群上创建一个 DaskCluster 资源来创建 Dask 集群。控制器看到它出现后,会为调度器、工作节点等启动子资源。
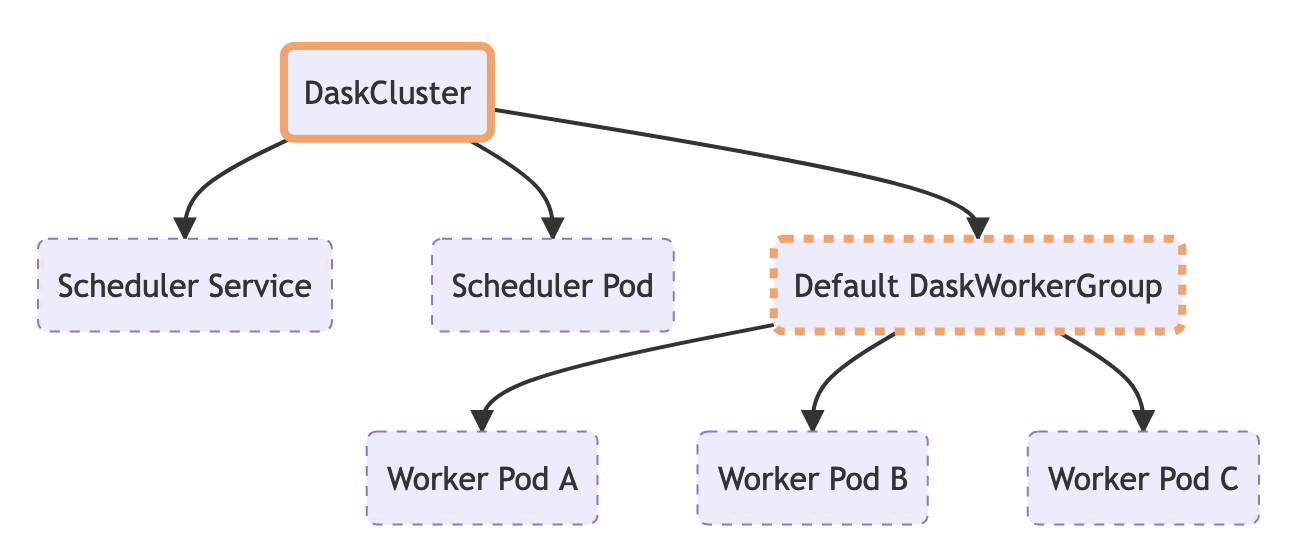
我们通过编辑 DaskCluster 资源来修改我们的集群,控制器会响应这些更改并相应地更新子资源。
我们通过删除 DaskCluster 资源来删除我们的集群,Kubernetes 会处理其余部分(请参阅下一节关于级联删除的内容)。
通过将我们所有的状态存储在资源中,并将所有逻辑存储在控制器中,这意味着 KubeCluster 类现在要简单得多。实际上,它如此简单以至于完全是可选的。
KubeCluster 类现在的主要目的是提供一个简洁美观的 API,用于在 Python 中创建/扩缩容/删除集群。它可以接受少量的关键字参数,并生成所有要提交给 Kubernetes 的 YAML。
from dask_kubernetes.operator import KubeCluster
cluster = KubeCluster(name="my-cluster", n_workers=3, env={"FOO": "bar"})
上述代码片段创建了以下资源。
apiVersion: kubernetes.dask.org/v1
kind: DaskCluster
metadata:
name: my-cluster
spec:
scheduler:
service:
ports:
- name: tcp-comm
port: 8786
protocol: TCP
targetPort: tcp-comm
- name: http-dashboard
port: 8787
protocol: TCP
targetPort: http-dashboard
selector:
dask.org/cluster-name: my-cluster
dask.org/component: scheduler
type: ClusterIP
spec:
containers:
- args:
- dask-scheduler
- --host
- 0.0.0.0
env:
- name: FOO
value: bar
image: ghcr.io/dask/dask:latest
livenessProbe:
httpGet:
path: /health
port: http-dashboard
initialDelaySeconds: 15
periodSeconds: 20
name: scheduler
ports:
- containerPort: 8786
name: tcp-comm
protocol: TCP
- containerPort: 8787
name: http-dashboard
protocol: TCP
readinessProbe:
httpGet:
path: /health
port: http-dashboard
initialDelaySeconds: 5
periodSeconds: 10
resources: null
worker:
cluster: my-cluster
replicas: 3
spec:
containers:
- args:
- dask-worker
- --name
- $(DASK_WORKER_NAME)
env:
- name: FOO
value: bar
image: ghcr.io/dask/dask:latest
name: worker
resources: null
如果我想将工作节点扩缩容到 5 个,我可以在 Python 中这样做。
cluster.scale(5)
所有这一切只是对资源应用一个补丁,并将 spec.worker.replicas 的值修改为 5,其余部分由控制器处理。
最终,我们的 Python API 生成 YAML 并将其传递给 Kubernetes 执行操作。我们集群的一切都包含在该 YAML 中。如果愿意,我们可以自己编写并存储这个 YAML,并完全通过 kubectl 管理我们的集群。
如果我们将上述 YAML 示例放入一个名为 my-cluster.yaml 的文件中,我们可以像这样创建它。无需 Python。
$ kubectl apply -f my-cluster.yaml
daskcluster.kubernetes.dask.org/my-cluster created
我们也可以使用 kubectl 扩缩容我们的集群。
$ kubectl scale --replicas=5 daskworkergroup my-cluster-default
daskworkergroup.kubernetes.dask.org/my-cluster-default
这对于希望与现有 Kubernetes 工具集成并真正修改其 Dask 集群一切的高级用户来说极其强大。
您将来仍然可以构造一个 KubeCluster 对象,并为了方便将其指向此现有集群。
from dask.distributed import Client
from dask_kubernetes.operator import KubeCluster
cluster = KubeCluster.from_name("my-cluster")
cluster.scale(5)
client = Client(cluster)
级联删除
拥有一个 DaskCluster 资源也使得删除更加愉快。
在旧实现中,您的本地 Python 进程会启动一堆 Pod 资源以及支持性资源,如 Service 和 PodDisruptionBudget 资源。它还有一些销毁功能,可以通过直接调用或通过 finalizer 在您完成后删除所有这些资源。
这种方式的一个缺点是,如果由于 dask-kubernetes 中的 bug 或更严重的故障导致 Python 进程在未调用 finalizer 的情况下退出,您会遗留下大量资源需要手动清理。我预计有些人会在他们的代码片段管理器中存储一个基于标签的选择器命令,但大多数人会手动进行此清理。
使用新模型,DaskCluster 资源被设置为由控制器启动的所有其他资源的 所有者。这意味着我们可以利用 级联删除 进行清理。无论您如何创建集群,也无论初始 Python 进程是否仍然存在,您只需删除 DaskCluster 资源,Kubernetes 就会知道自动删除它的所有子资源。
$ kubectl get daskcluster # Here we see our Dask cluster resource
NAME AGE
my-cluster 4m3s
$ kubectl get all -A -l dask.org/cluster-name=my-cluster # and all of its child resources
NAMESPACE NAME READY STATUS RESTARTS AGE
default pod/my-cluster-default-worker-22bd39e33a 1/1 Running 0 3m43s
default pod/my-cluster-default-worker-5f4f2c989a 1/1 Running 0 3m43s
default pod/my-cluster-default-worker-72418a589f 1/1 Running 0 3m43s
default pod/my-cluster-default-worker-9b00a4e1fd 1/1 Running 0 3m43s
default pod/my-cluster-default-worker-d6fc172526 1/1 Running 0 3m43s
default pod/my-cluster-scheduler 1/1 Running 0 4m21s
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default service/my-cluster-scheduler ClusterIP 10.96.33.67 <none> 8786/TCP,8787/TCP 4m21s
$ kubectl delete daskcluster my-cluster # We can delete the daskcluster resource
daskcluster.kubernetes.dask.org "my-cluster" deleted
$ kubectl get all -A -l dask.org/cluster-name=my-cluster # all of the children are removed
No resources found
多工作节点组
我们还借此机会添加了对 多工作节点组 作为一等公民原则的支持。有些工作流受益于集群中拥有少量具有额外资源的工作节点。这可能是一两个内存比其他工作节点高得多的工作节点,或者用于加速计算的 GPU。使用 资源注解,您可以将特定任务导向那些工作节点,因此如果您有一个步骤会创建大量中间内存,您可以确保该任务最终落在内存足够的工作节点上。
默认情况下,当您创建一个 DaskCluster 资源时,它会创建一个单一的 DaskWorkerGroup,进而创建我们集群的工作节点 Pod 资源。如果您愿意,您可以使用不同的资源配置自己添加更多工作节点组资源。
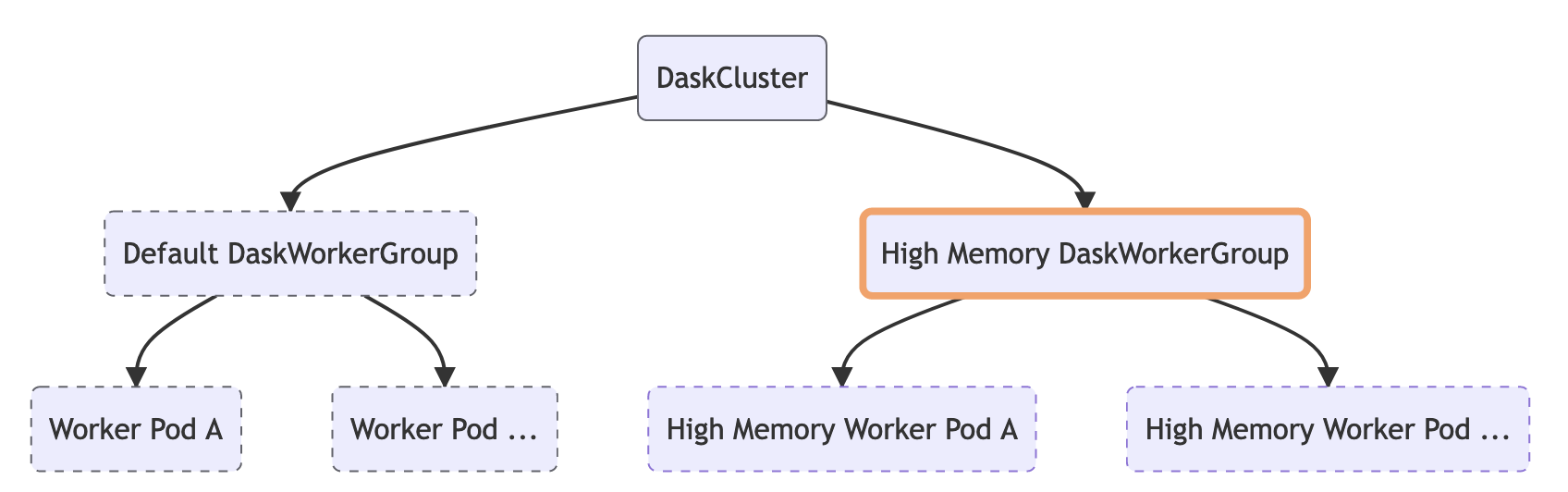
这是一个创建包含五个具有 16GB 内存的工作节点和两个具有 64GB 内存的额外工作节点的集群的示例。
from dask_kubernetes.operator import KubeCluster
cluster = KubeCluster(name='foo',
n_workers=5,
resources={
"requests": {"memory": "16Gi"},
"limits": {"memory": "16Gi"}
})
cluster.add_worker_group(name="highmem",
n_workers=2,
resources={
"requests": {"memory": "64Gi"},
"limits": {"memory": "64Gi"}
})
自动伸缩
经典 KubeCluster 实现中备受欢迎的功能之一是自适应自动伸缩。启用后,KubeCluster 对象会定期与调度器通信,询问是否需要更改工作节点的数量,然后相应地添加/移除 pod。
在新实现中,此逻辑已移至控制器,因此即使 KubeCluster 对象不存在,集群也可以自动伸缩。
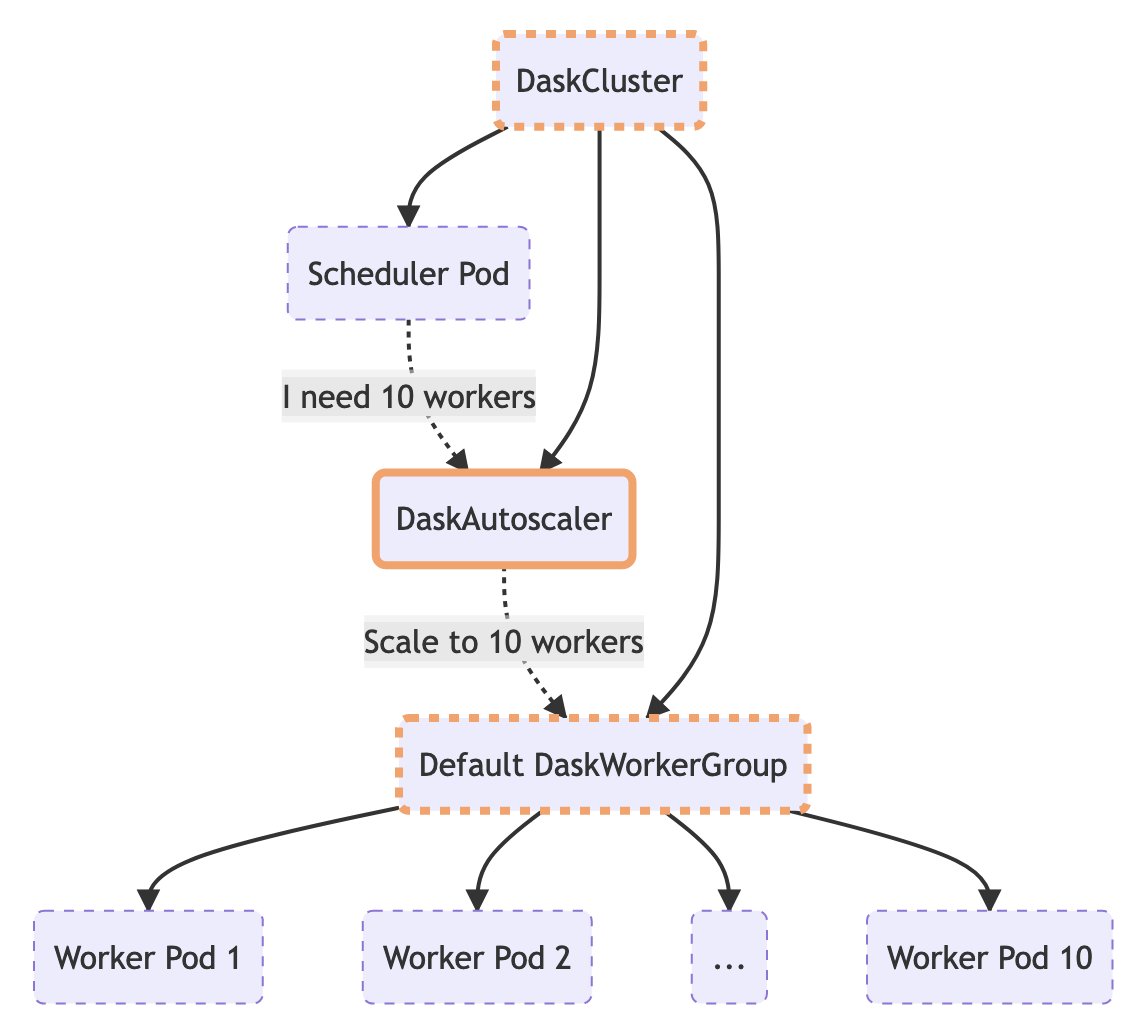
Python API 保持不变,因此您仍然可以使用 KubeCluster 将您的集群置于自适应模式。
from dask_kubernetes.operator import KubeCluster
cluster = KubeCluster(name="my-cluster", n_workers=5)
cluster.adapt(minimum=1, maximum=100)
此调用会创建一个 DaskAutoscaler 资源,控制器会看到该资源并定期采取行动,询问调度器需要多少工作节点,并在配置的界限内更新 DaskWorkerGroup。
apiVersion: kubernetes.dask.org/v1
kind: DaskAutoscaler
metadata:
name: my-cluster
spec:
cluster: my-cluster
minimum: 1
maximum: 100
调用 cluster.scale(5) 也将删除此资源,并将工作节点数量设置回 5。
DaskJob
拥有可组合的集群资源也允许我们组合出一个 新的 DaskJob 资源。
Kubernetes 具有一些内置的 批处理作业风格资源,这些资源确保一个 Pod 运行直至完成一次或多次。您可以控制它应该运行多少次,以及应该有多少并发 pod。这对于希望处理特定工作负载的即发即弃作业非常有用。
Dask Operator 引入了 DaskJob 资源,该资源会创建一个 DaskCluster 以及一个单独的客户端 Pod,并尝试运行直至完成。如果 Pod 异常退出,它将被重启,直到返回退出码 0,此时 DaskCluster 会自动清理。
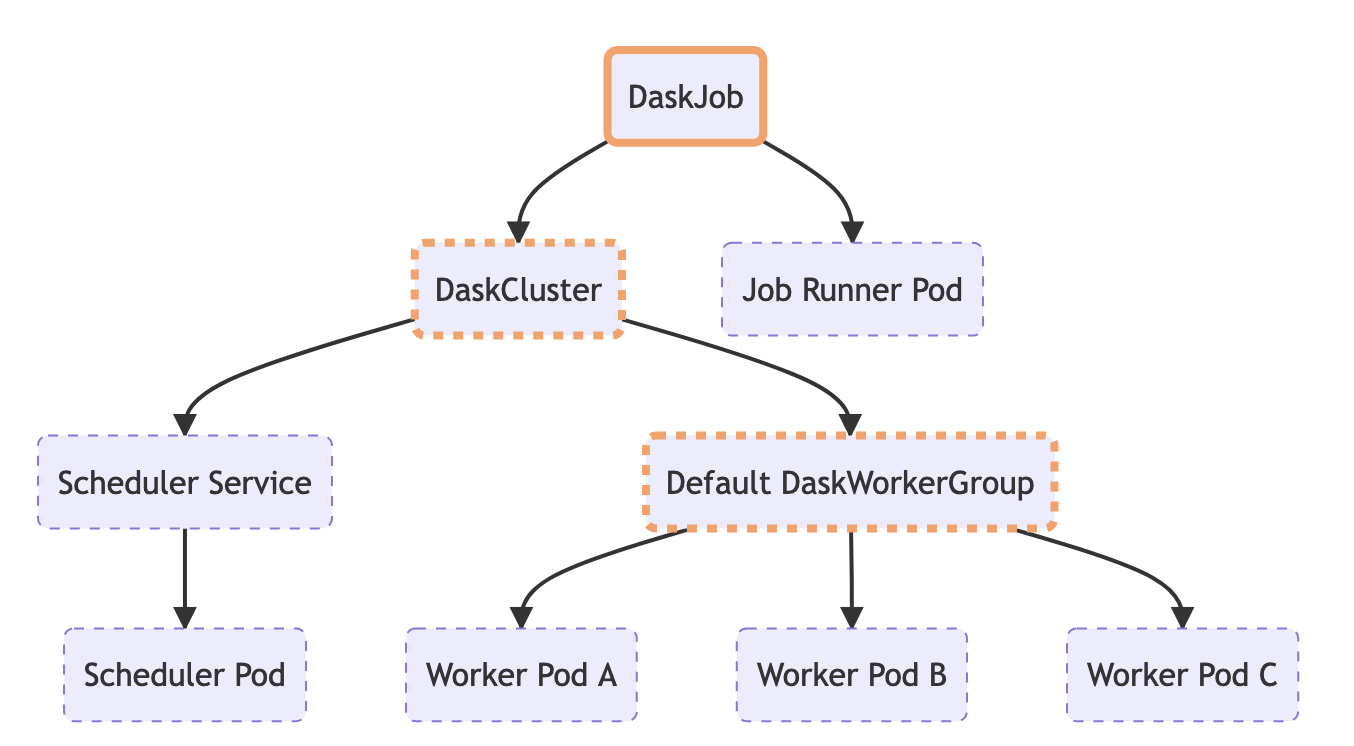
客户端 Pod 会在运行时通过环境变量注入 DaskCluster 的所有配置,这意味着您的客户端代码无需知道任何关于 Dask 集群是如何构建的细节,它只需连接并使用它即可。这使得您的业务逻辑和部署工具之间能够实现极好的关注点分离。
from dask.distributed import Client
# We don't need to tell the Client anything about the cluster as
# it will find everything it needs in the environment variables
client = Client()
# Do some work...
这种新资源类型对于某些批处理工作流很有用,但同时也展示了您如何可以使用自己的新资源类型扩展 Dask Operator,并将其与控制器插件连接起来。
可扩展性和插件
通过转向原生 Kubernetes 资源和支持 YAML API,高级用户可以将 DaskCluster 资源(或任何新的 Dask 资源)视为更大型应用程序中的构建块。Kubernetes 的一项超能力是将所有内容作为可组合的资源进行管理,这些资源可以组合起来创建复杂而灵活的应用程序。
您的 Kubernetes 集群是否安装了像 Istio 这样的附加工具,并有特定的配置?您过去是否因为 dask-kubernetes 依赖于 Python 来创建集群而难以与现有工具集成?
对于用户来说,需要同时创建 Dask 集群旁边的一些附加资源(例如 Istio Gateway 资源或 cert-manager Certificate 资源)变得越来越常见。现在 dask-kubernetes 中的一切都使用自定义资源,用户可以混搭来自许多不同 Operator 的资源来构建他们的应用程序。
如果这还不够,您还可以 扩展我们的自定义控制器。我们主要使用 kopf 构建控制器,因为 Dask 社区在 Python 方面很强,而在 Golang 方面较弱(这是构建 Operator 最常见的方式)。发挥我们的优势,而不是使用最流行的选项,这是合理的。
这也意味着我们的用户应该能够更容易地修改控制器逻辑,并且我们提供了一个插件系统,允许您通过在控制器容器镜像中安装自定义包并通过入口点注册它们来添加额外的逻辑规则。
# Source for my_controller_plugin.plugin
import kopf
@kopf.on.create("service", labels={"dask.org/component": "scheduler"})
async def handle_scheduler_service_create(meta, new, namespace, logger, **kwargs):
# Do something here like create an Istio Gateway
# See https://kopf.readthedocs.io/en/stable/handlers for documentation on what is possible here
# pyproject.toml for my_controller_plugin
[option.entry_points]
dask_operator_plugin =
my_controller_plugin = my_controller_plugin.plugin
# Dockerfile
FROM ghcr.io/dask/dask-kubernetes-operator:2022.10.0
RUN pip install my-controller-plugin
就是这样,当控制器启动时,它也会导入 dask_operator_plugin 入口点中列出的模块中的所有 @kopf 方法,以及核心功能。
迁移
切换到 Operator 模型的一个需要注意的地方是,在使用之前,您需要在 Kubernetes 上安装 CRDs 和控制器。虽然这是一个小小的障碍,但与经典实现相比,这确实是用户体验上的一个中断。
helm repo add dask https://helm.dask.org && helm repo update
kubectl create ns dask-operator
helm install --namespace dask-operator dask-operator dask/dask-kubernetes-operator
我们还借此机会对 KubeCluster 的构造函数进行了破坏性更改,以简化初学者或对默认选项满意的人的使用。通过采用 YAML API,高级用户可以随心所欲地修修补补,而无需修改 Python 库,因此简化 Python 库并使其对大多数用户更愉快使用是合理的。
我们做出了明确的决定,不只是原地用新的 KubeCluster 替换旧的,因为这样做会导致人们的代码无法工作。相反,我们要求人们 阅读迁移指南 并更新您的导入和构造代码。经典集群管理器的用户从 2022.10.0 版本开始将看到弃用警告,并且在某个时候经典实现将被完全移除。如果快速迁移有挑战性,您总是可以固定 dask-kubernetes 的版本,但从那时起,您显然无法获得错误修复或增强功能。但老实说,最近经典实现的这些更新也已经少之又少了。
我们乐观地认为,新的更整洁的实现、更快的集群启动时间以及一系列新功能足以说服您迁移是值得的。
如果您需要迁移方面的帮助,并且迁移指南未涵盖您的用例,请不要犹豫在 论坛上联系我们。我们也努力确保新实现与经典实现具有功能对等性,但如果有什么缺失或损坏,请在 GitHub 上提 issue。
博客评论由 Disqus 提供支持