将 Dask 工作负载的内存使用量降低 80%
作者:Gabe Joseph (Coiled)
本文原文发表于 https://www.coiled.io/blog/reducing-dask-memory-usage
应急响应中有一句格言:“慢即是稳,稳即是快”。
这句格言一直困扰着我,因为它乍听起来不合逻辑,但却完全正确。
通过将这一理念应用于 Dask 最新版本中的调度算法,我们看到常见工作负载的内存使用量比以前减少了高达 80%。这意味着一些过去根本无法运行的工作负载现在可以平稳运行了——这简直是无限倍的加速!
历史上点赞和评论数排名第二的议题在 dask/distributed 仓库中描述了:“我的计算图早期阶段的任务生成数据的速度比下游消费数据的速度要快,导致数据堆积,最终压垮了我的工作节点(worker)”。
Dask 用户经常遇到因内存耗尽而失败的工作负载。通过研究这些情况,我们意识到 Dask 调度器并未遵循“慢即是稳,稳即是快”的格言。
问题在于此,以及我们如何解决的
从历史上看,Dask 努力让每个单独的任务都尽可能快地完成:如果一个任务可以运行,它就会运行。因此有时,任务会运行,即使它们的输出不会立即被使用——从而让它们滞留在内存中。
如果你有数千个初始任务用于加载数据——比如,从 S3 获取 Parquet 文件,从磁盘读取 CSV 文件,或者从数据库中读取行——所有这些任务都会被提前调度并发送给工作节点。
工作节点会快速处理这些任务,尽可能快地抓取数据块(并将其累积在内存中)。工作节点会在每个数据块加载完成后告知调度器,调度器会回复下一步该如何处理——但在收到回复之前,还有更多的数据加载任务可以立即运行,那为何不运行呢?

这种微小的时间差——工作节点立即开始执行一个不太有用的任务,随后才得知应该执行一个更有用的任务——导致这些低优先级数据在内存中堆积。我们称之为“根任务过度生产”。
总的来说,内存中同时存在的数据量至少是必需的两倍——因此,中间结果的数量也是两倍。(参见此评论,了解为什么会出现两倍内存使用的详细解释。)
当这给工作节点带来内存压力时,最初的问题会滚雪球般变成一个更大的问题。工作节点不得不将数据溢出到磁盘(慢),然后从磁盘读回数据以使用或传输(慢)。工作节点可能会超出其内存限制并崩溃,导致进度丢失,并且需要在已处于困境的工作节点池上重新计算任务。
最终,这意味着一整类工作负载变得缓慢,甚至无法运行,除非使用超大规格的集群。
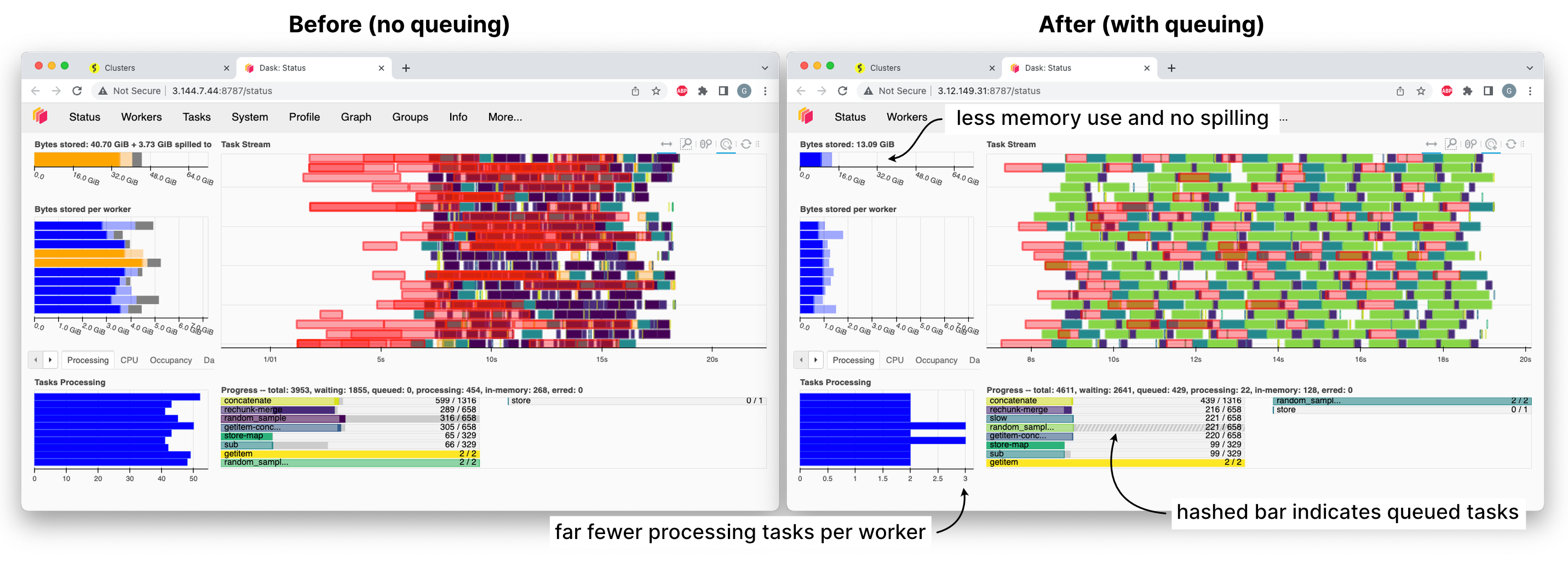
有很多方法可以解决这个问题,但我们想先尝试最简单的方法:只是不告诉工作节点它们一次能运行的任务数量之外的更多任务。
我们将这种调度模式称为“排队(queuing)”,或“根任务抑制(root task withholding)”。调度器将数据加载任务放入内部队列,只有当工作节点完成当前工作并且没有更优先的任务可以利用刚刚完成的工作时,才会分配一个任务给工作节点。
慢即是稳
排队会增加延迟成本。每次工作节点完成一个任务时,它们都必须询问调度器下一步做什么,并在等待回复期间处于未充分利用甚至空闲状态。(以前,在收到回复之前,它们有一堆可以做的事情的待办列表。)
一段时间以来,我们并未考虑这种方法,因为凭直觉,我们认为延迟会导致速度下降太多。
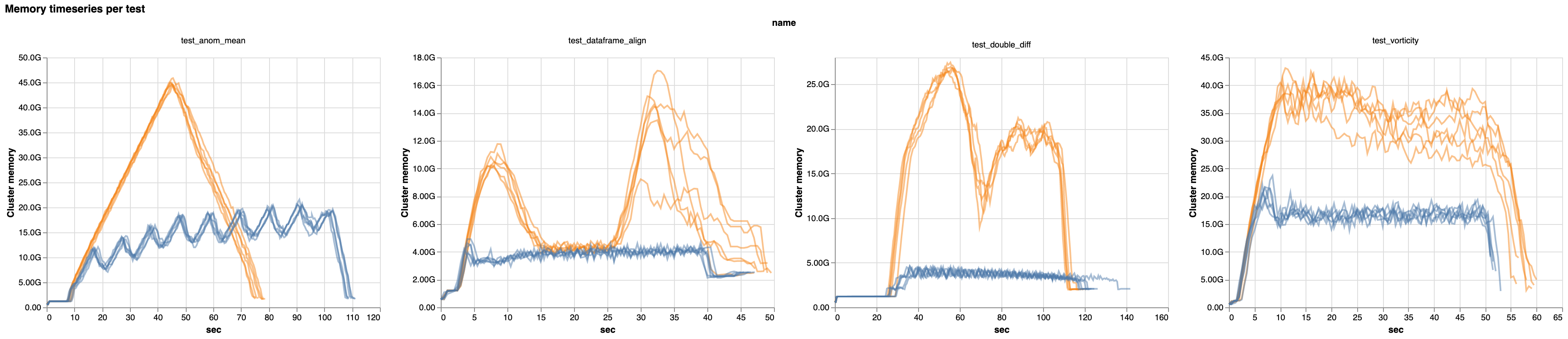
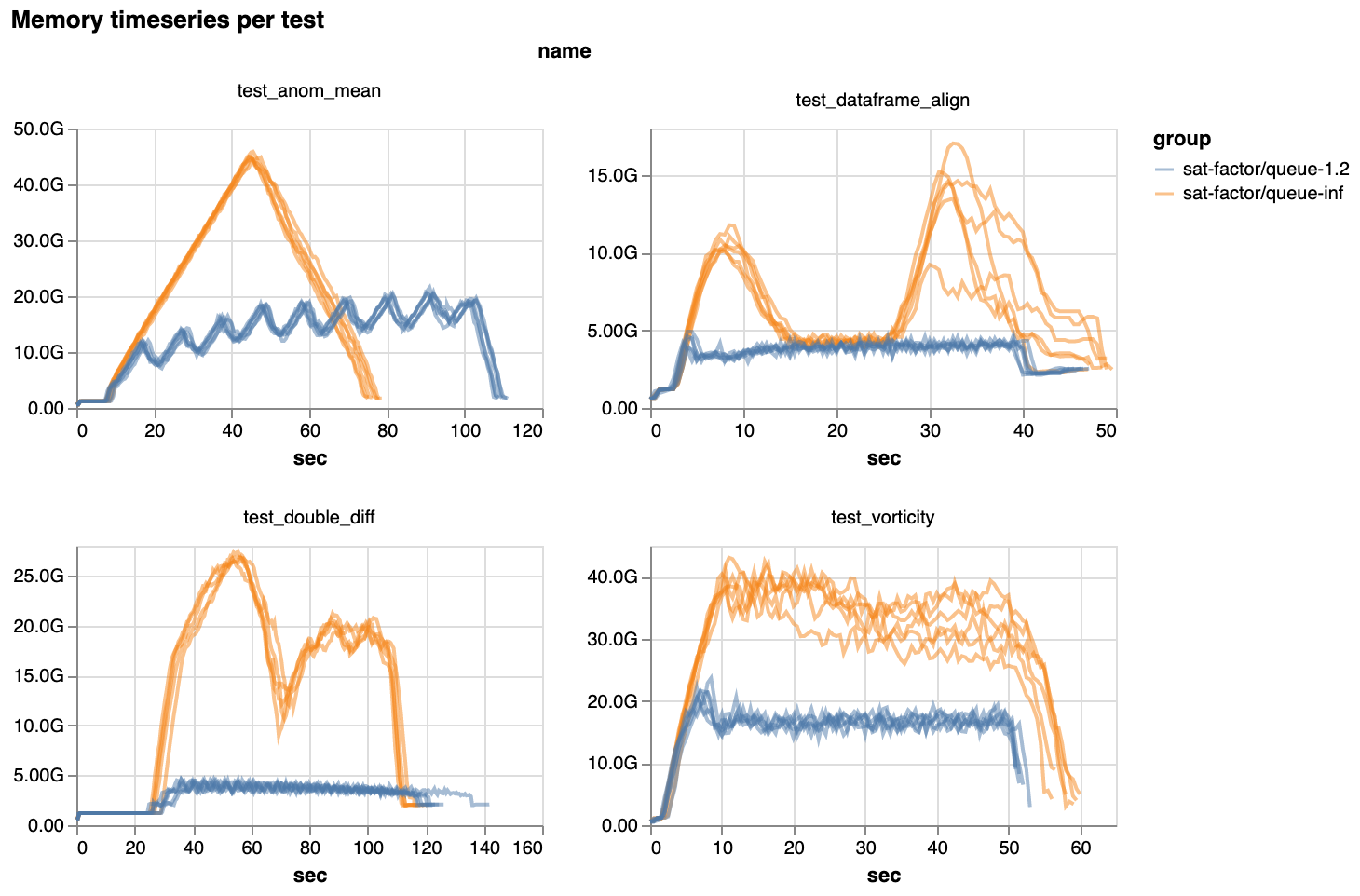
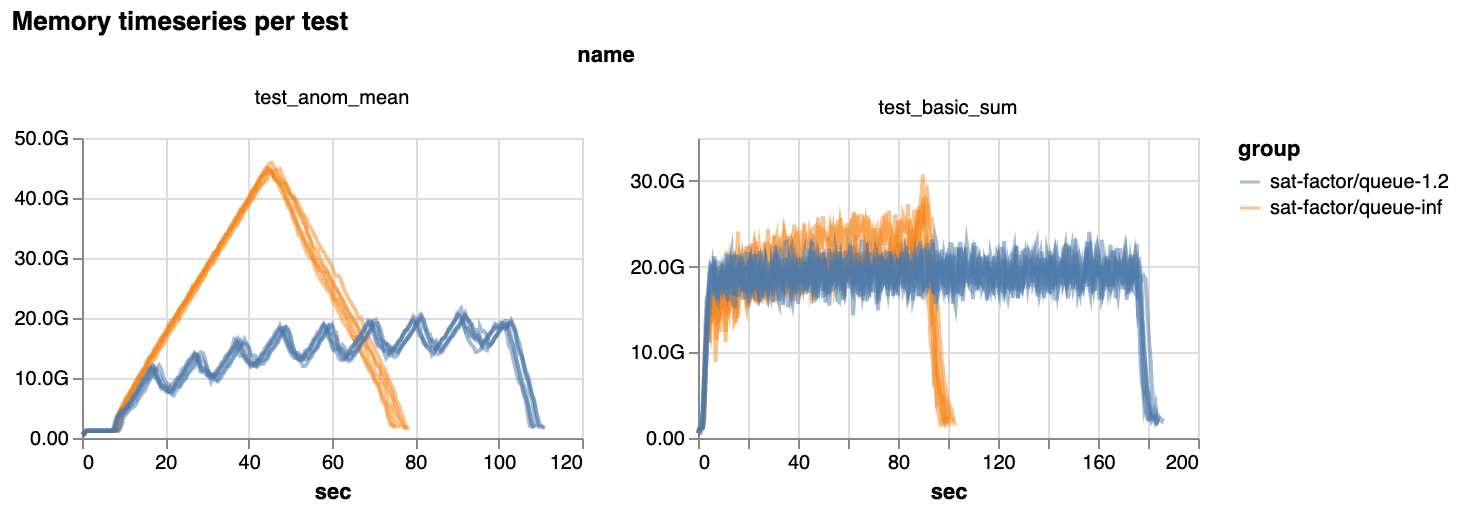
然而,通过放慢任务分配的速度,并只运行最优的任务,调度变得更加平稳。随之而来的平稳性,我们看到大多数基准工作负载的内存使用量全面大幅下降
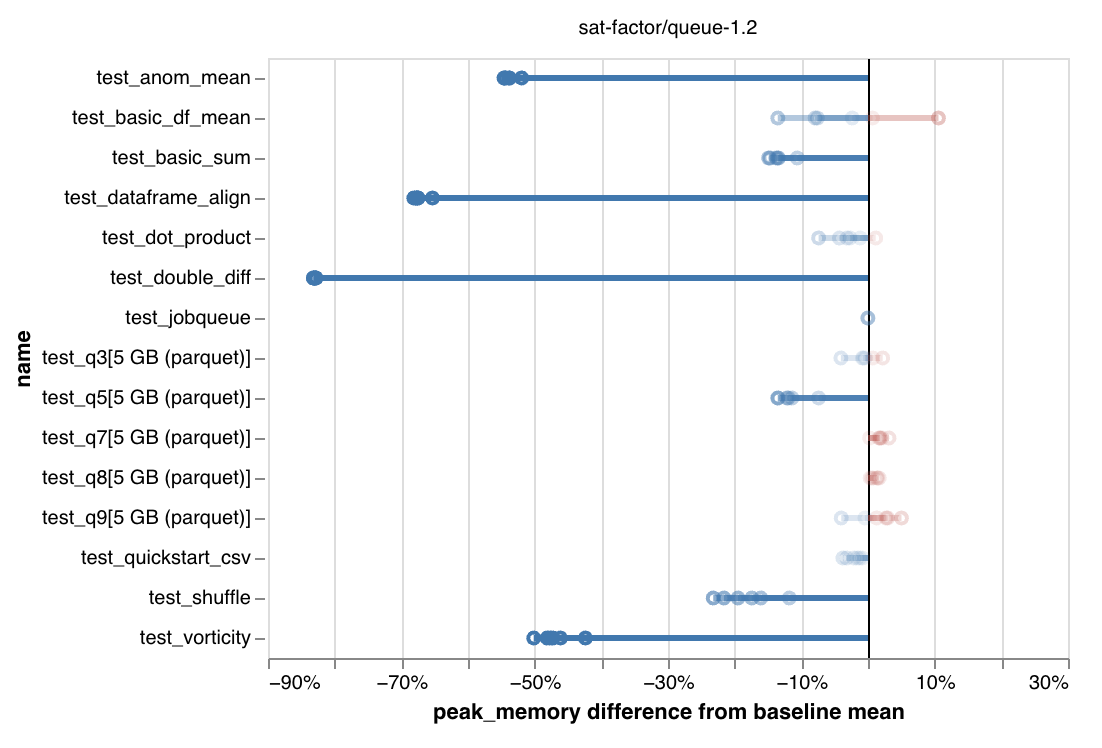
最新版本中峰值内存使用量的百分比下降。注意坐标轴:降低高达 80%。
如此大幅度的内存使用量下降意义重大!
对于许多用户来说,这意味着以前无法运行的工作负载现在可以平稳运行了。

Julius Busecke 报告说,一个过去总是崩溃的常见地球科学任务现在使用新的调度模式就可以直接运行了。
一些工作负载在云中运行的成本也会更低,因为它们可以使用内存较小的实例。我们看到一些基准测试,理论上可以以 30-50% 的总成本运行。但这并非普遍适用:其他一些工作负载会花费更多,因为它们变慢了。稍后将详细介绍。
除此之外,执行也更加可预测。内存使用更加稳定,不易发生快速飙升。
稳即是快
在少数情况下,平稳的调度甚至可以更快。
平均而言,一个具有代表性的海洋学工作负载快了 20%。其他一些工作负载也表现出适度的加速。这主要是因为它们不再将过多数据加载到内存中然后不得不溢出到磁盘,这会造成显著的减速。
此外,我们发现我们担心的额外延迟在典型情况下并未导致速度变慢。在具有快速网络和多 CPU 工作节点的集群上,比如 Coiled 集群或单机 LocalCluster,纯任务吞吐量没有可测量的变化。这为我们上了很好的一课,即先尝试最简单的方法。
有时,慢还是慢(但原因可能出乎意料)
然而,我们确实注意到一些基准测试在使用调度器端排队时运行得更慢。典型的减速是 5-10%,但在最坏的情况下,它们会慢约 50%(尽管它们的内存使用量也减少了约一半)。
问题在于,实现排队意味着放弃去年引入的一个名为协同分配(co-assignment)的调度功能。
正如文档中所述,协同分配尝试将初始任务调度到同一个工作节点上,如果它们的输出稍后会被合并。这避免了在下游任务运行时需要将数据从一个工作节点传输到另一个工作节点,因为所有数据都已在一个工作节点上。
在像这样的计算图中,我们希望 a 和 b 在同一个工作节点上运行。否则,在 i 运行之前,e 或 f 之一就必须在工作节点之间传输。
i j
/ \ / \
e f g h
| | | |
a b c d
避免这些传输可以加快速度,因为网络相对较慢。它还通过避免在多个工作节点上保留相同数据的副本而减少内存使用。
不幸的是,当前协同分配的实现与排队不兼容,并且更新它并非易事。我们计划下一步处理这个问题,以达到两全其美的效果。
但在短期内,我们必须决定排队机制是否足够有益,值得立即默认启用,尽管牺牲了协同分配功能。
调度的全新默认设置
在运行了大量基准测试,并获得了一些社区初步反馈后,我们认为这是值得的。
排队机制使得过去根本无法完成的事情成为可能。但这并不会破坏目前正常运行的功能:所有一切仍然可以工作,只是有些事情可能会变慢。考虑到 Dask 用户在内存问题上挣扎已久,我们认为这是一个足够值得权衡取舍的改变,可以默认启用。
此外,为了避免影响可能受延迟限制的工作负载,新算法仍然会进行少量的过度生产。它会提前向工作节点推送少量额外的根任务(而不是像以前那样推送所有任务)。这会牺牲一些额外的内存使用,但可以防止在高延迟集群中出现令人痛苦的速度下降。
因此,在最新版本中,排队机制已默认启用。大多数内存密集型的 Array 和 DataFrame 工作负载应该会开箱即用地看到内存使用量的减少,从显著减少到令人惊喜🤩。
请告诉我们您的使用体验
我们在 GitHub 上开启了一个讨论,征集关于此更改的反馈。请告诉我们它是否带来了帮助(或没有)。
保留旧行为
对于对运行时敏感且内存使用量较低的用户,您可以通过 Dask 配置来禁用排队并使用旧的调度模式(包括协同分配),方法是将新的配置值 distributed.scheduler.worker-saturation 设置为 inf。
您可以在文档中阅读更多关于调整此设置的信息。
在 Coiled 上,您可以通过以下方式设置:
import dask
import coiled
with dask.config.set({"distributed.scheduler.worker-saturation": "inf"}):
cluster = coiled.Cluster(...) # coiled sends current dask config automatically
您可以在讨论议题中查看针对各种部署系统设置此配置的示例(复制粘贴时,请务必将 1.0 更改为 inf!)。如果您发现需要将 worker-saturation 设置回 inf,请在讨论中告知我们。
博客评论由 Disqus 提供支持