在Dask中以恒定内存混洗大数据
作者:Hendrik Makait
这项工作由 Coiled 提供工程支持。特别感谢 Florian Jetter、Gabe Joseph、Hendrik Makait 和 Matt Rocklin。本文的原始版本发布于 blog.coiled.io
随着 2023.2.1 版本的发布,dask.dataframe 引入了一种名为 P2P 的新混洗方法,使得排序、合并和连接操作更快并使用恒定内存。基准测试显示了显著的改进
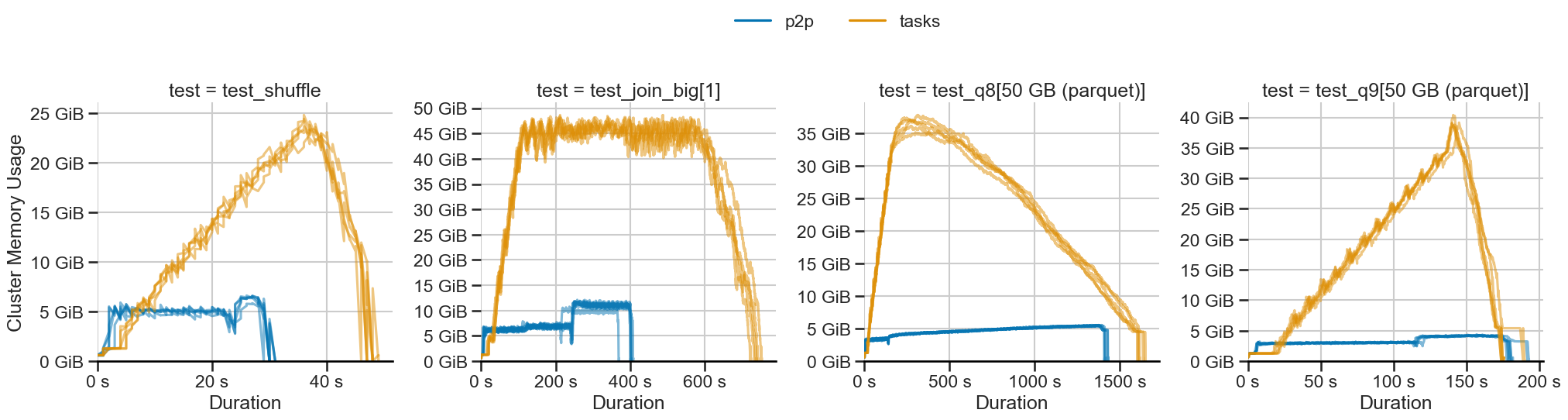
P2P 混洗(蓝色)使用恒定内存,而基于任务的混洗(橙色)则线性扩展。
本文介绍了问题、新的解决方案以及对性能的影响。
什么是混洗?
混洗是数据处理系统中的一个关键原语。它在需要以全对全方式移动数据集时使用,例如发生在排序、数据框连接或数组重分块中。混洗是一种难以高效运行的计算,涉及大量细小的任务来分片数据。
基于任务的混洗扩展性差
虽然分布式数据库和 Apache Spark 等系统使用专用的混洗服务在集群中移动数据,但 Dask 是基于任务调度的。基于任务的系统对于通用并行计算更灵活,但不太适合全对全混洗。这导致了三个主要问题
- 调度器压力:由于混洗所需任务量巨大,调度器会挂起。
- 完整数据集具体化:工作节点会将整个数据集具体化,导致集群内存不足。
- 许多细小操作:中间任务过于细小,降低了硬件性能。
总而言之,这些问题使得大规模混洗效率低下,导致用户过度配置集群。幸运的是,我们可以设计一个系统来解决这些问题。这项工作的早期开始于 2021年,现已成熟为 P2P 混洗系统
P2P 混洗
随着 2023.2.1 版本的发布,Dask 引入了一种名为 P2P 的新混洗方法,使得排序、合并和连接操作更快并使用恒定内存运行。
该系统设计考虑了三个方面,反映了上面列出的问题
-
点对点通信:减少调度器的介入
从调度器的角度来看,混洗变成了 O(n) 操作,消除了一个关键瓶颈。
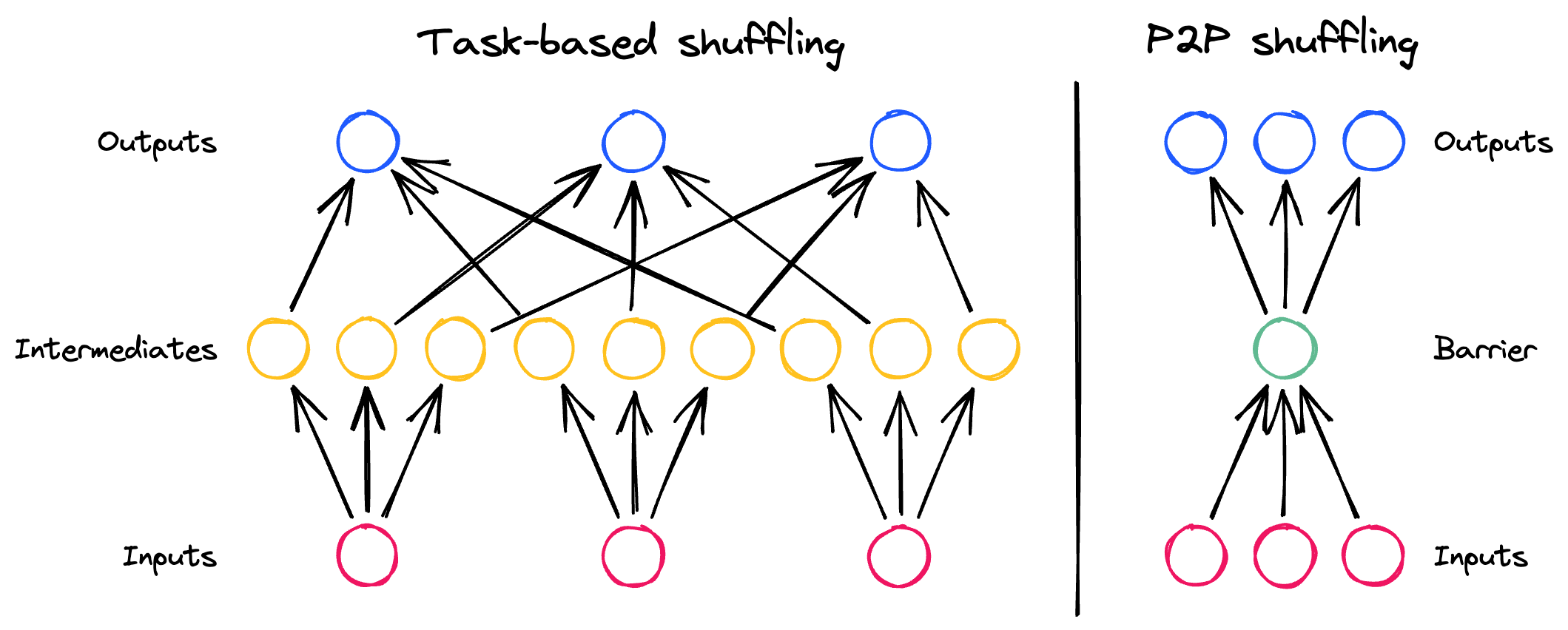
-
默认写入磁盘:数据到达时高效地存储到磁盘。
Dask 现在可以在少量内存下混洗任意大小的数据集,减少了调整集群大小的麻烦。
-
使用内存缓冲网络和磁盘:通过使用内存存储缓冲敏感硬件,避免大量小写入。
混洗涉及 CPU、网络和磁盘,在处理大量细小数据时,每个都会带来各自的瓶颈。我们明智地使用内存来权衡这些瓶颈,平衡网络和磁盘 I/O,以最大化整体吞吐量。
除了这三个方面,P2P 混洗还实现了许多细微的优化来提高性能,并且依赖于 pyarrow>=7.0 来高效处理数据和进行(反)序列化。
结果
为了评估 P2P 混洗,我们在基准测试套件中的常见工作负载上与基于任务的混洗进行了对比测试。有关此基准测试套件的更多信息,请参阅 GitHub 仓库 或 最新的测试结果。
内存稳定性
P2P 混洗的最大优势是恒定的内存使用。在所有工作负载中,内存使用量下降并保持恒定
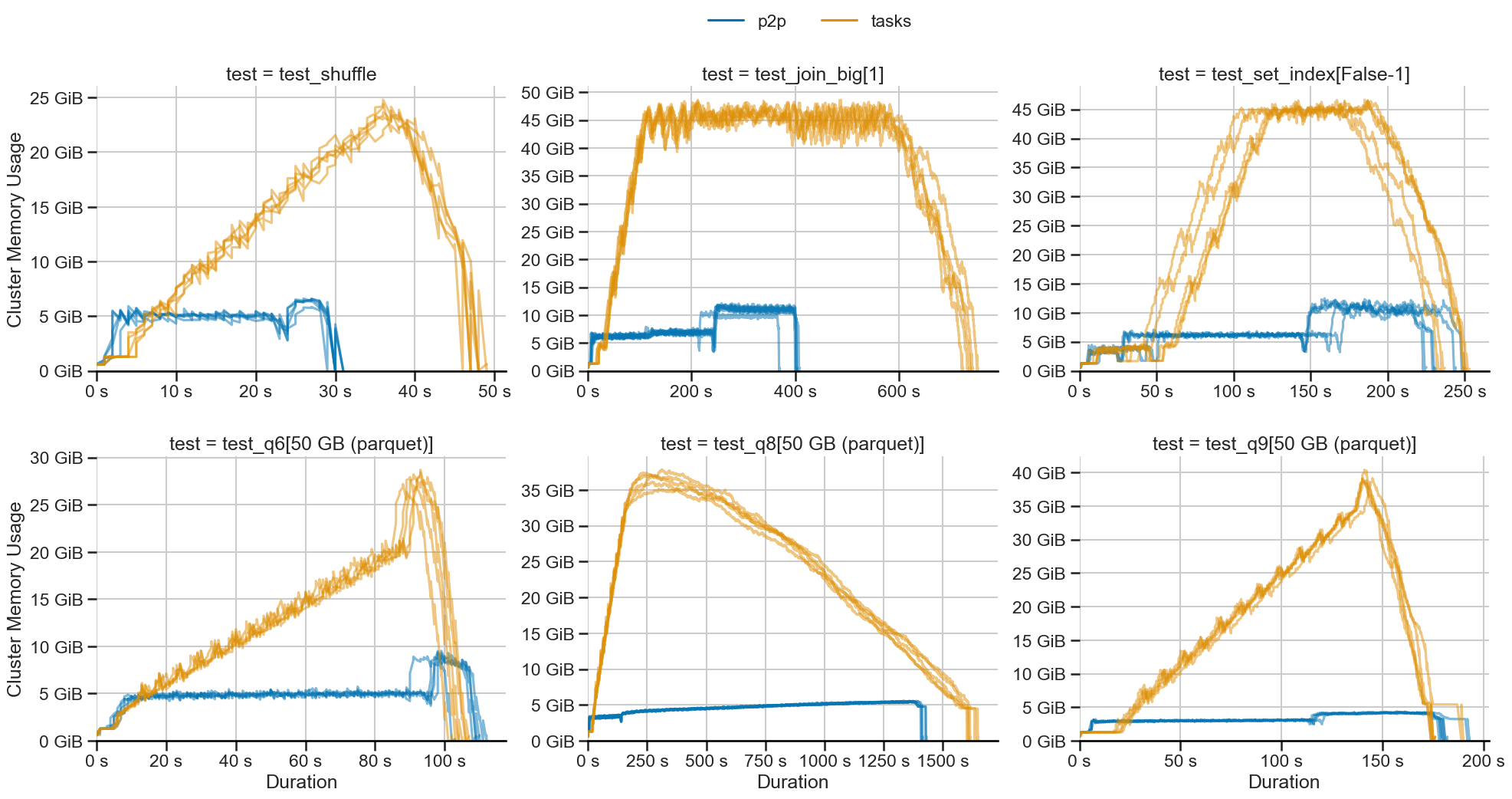
P2P 混洗(蓝色)使用恒定内存,而基于任务的混洗(橙色)则线性扩展。
对于测试的工作负载,我们观察到内存使用量降低高达 10 倍。对于更大的工作负载,这种差距只会增加。
性能和速度
在上图中,我们可以看到两项性能改进
- 执行速度更快:工作负载运行速度提高达 45%。
- 启动更快:图更小意味着 P2P 混洗启动更快。
将 P2P 和基于任务的混洗的调度器面板并排比较,有助于理解这些性能提升的原因
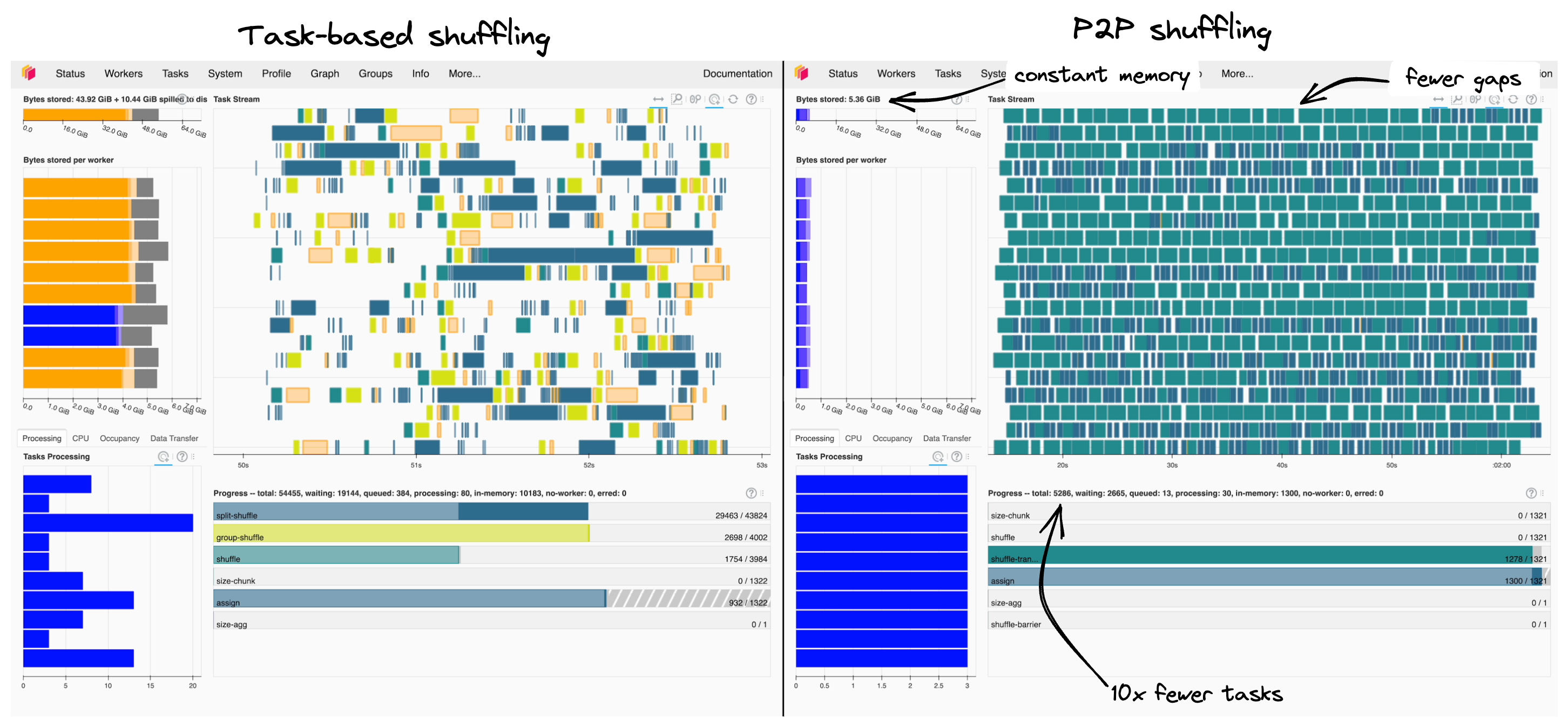
基于任务的混洗(左)相比 P2P 混洗(右),显示出任务流中更大的间隔和溢出。
- 图大小:任务数量减少 10 倍,部署更快,对调度器压力更小。
- 受控 I/O:P2P 混洗显式处理 I/O,避免了 Dask 效率较低的溢出。
- 更少中断:I/O 均衡良好,因此我们在任务流中看到的任务间隔更少。
总的来说,P2P 混洗更有效地利用了我们的硬件。
更改默认设置
这些结果惠及大多数用户,因此从 2023.2.1 版本开始,只要安装了 pyarrow>=7.0.0,P2P 混洗现已成为默认设置。以下数据框操作将受益
df.set_index(...)df.merge(...)df.groupby(...).apply(...)
分享您的经验
为了了解 P2P 如何在各种实际工作负载中表现,并确保将其设为默认设置是正确的选择,我们非常希望了解您运行它的体验。我们已在 GitHub 上开启了一个 讨论帖,以便收集关于此更改的反馈。请告诉我们它有何帮助(或无益)。
保留旧的行为
如果 P2P 混洗对您不起作用,您可以通过将 dataframe.shuffle.method 配置值设置为 "tasks" 或显式设置关键字参数来停用它,例如
使用 yaml 配置
dataframe:
shuffle:
method: tasks
或在使用集群管理器时
import dask
from dask.distributed import LocalCluster
# The dataframe.shuffle.method config is available since 2023.3.1
with dask.config.set({"dataframe.shuffle.method": "tasks"}):
cluster = LocalCluster(...) # many cluster managers send current dask config automatically
有关停用 P2P 混洗的更多信息,请参阅 讨论 #7509。
数组呢?
虽然最初的动机是优化大规模数据框连接,但 P2P 系统对于所有需要大量任务间通信的问题都很有用。对于数组工作负载,这通常发生在数据重分块时,例如将按列存储的矩阵按行组织。与数据框连接类似,过去数组重分块效率不高,这已成为一个问题,以至于数组社区构建了 rechunker 等专用工具来完全避免它。
目前有一个使用 P2P 系统的数组重分块 简单实现 可供实验使用。对该实现的基准测试显示结果喜忧参半
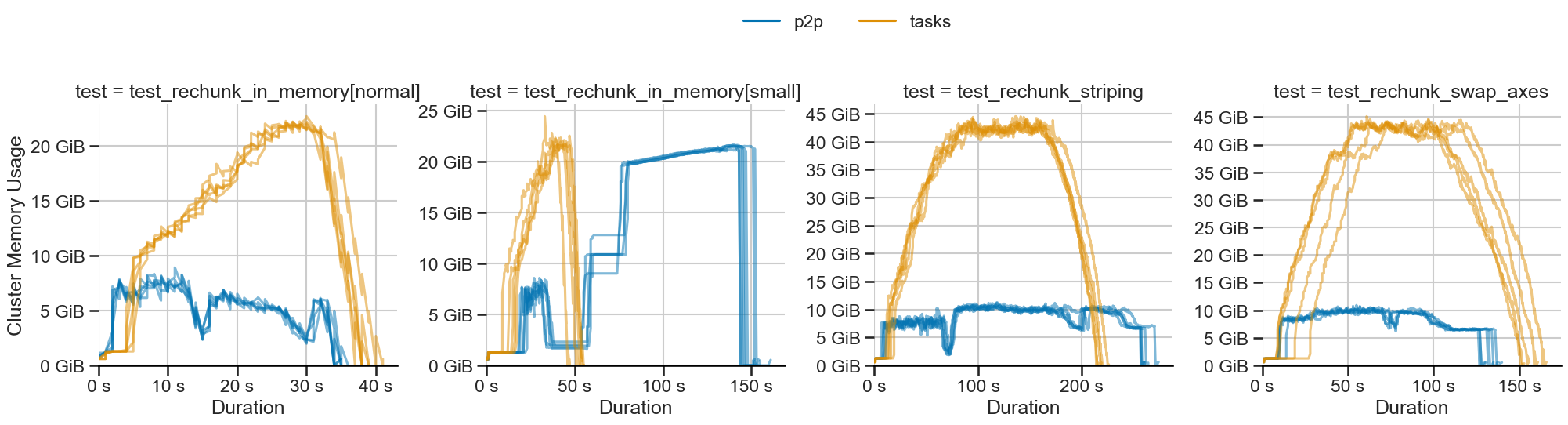
- 👍 恒定内存使用:与数据框操作一样,内存使用是恒定的。
- ❓ 可变运行时长:使用 P2P 后,工作负载的运行时长可能会增加。
- 👎 内存开销:对于许多小分区,存在较大的内存开销。
恒定的内存使用是一个非常有前景的结果。有几种方法可以解决当前的局限性。我们预计,随着我们与数组计算社区的合作者一起工作,这将得到改善。
后续步骤
P2P 混洗的开发尚未完成。未来我们计划进行以下工作
-
dask.array:虽然数组重分块的早期原型很有前景,但尚未达到理想状态。我们计划进行以下工作
- 智能选择要使用的算法(有时基于任务的重分块更好)
- 与重分块方面的合作者一起提高性能
- 寻找其他用例,例如
map_overlap,这可能有所帮助
-
故障恢复:
使 P2P 混洗能够容忍工作节点丢失;目前,它必须完全重启。
-
性能调优:
目前的性能很好,但尚未达到硬件峰值速度。我们可以通过几种方式改进
- 隐藏磁盘 I/O
- 在适合小规模混洗时使用更多内存
- 改进对小操作的批处理
- 更高效的序列化
要跟踪开发进展,请在 GitHub 上订阅 跟踪议题。
总结
数据混洗是数据框工作负载中的常见操作。自 2023.2.1 版本以来,Dask 对于分布式集群默认使用 P2P 混洗,并以更快、恒定内存的方式混洗数据。这一改进使得以前无法运行的工作负载规模成为可能,并高效地利用您的集群。最后,P2P 混洗展示了如何在利用其分布式引擎基础的同时扩展 Dask 以添加新的范式。
博客评论由 Disqus 提供支持