Dask 中的高级查询优化
作者:Patrick Hoefler
这项工作由 Coiled 和 NVIDIA 工程师实现和支持。特别感谢 Patrick Hoefler 和 Rick Zamora。本文的原始版本发布在 blog.coiled.io。
引言
Dask DataFrame 目前不会(像 Spark 或 SQL 数据库那样)为你优化代码。这意味着用户会浪费很多计算资源。我们来看一个常见的例子,它乍一看没问题,但实际上效率很低。
import dask.dataframe as dd
df = dd.read_parquet(
"s3://coiled-datasets/uber-lyft-tlc/", # unnecessarily reads all rows and columns
)
result = (
df[df.hvfhs_license_num == "HV0003"] # could push the filter into the read parquet call
.sum(numeric_only=True)
["tips"] # should read only necessary columns
)
通过几个简单的步骤,我们可以让它运行得更快
df = dd.read_parquet(
"s3://coiled-datasets/uber-lyft-tlc/",
filters=[("hvfhs_license_num", "==", "HV0003")],
columns=["tips"],
)
result = df.tips.sum()
目前,Dask DataFrame 不会为你优化这一点,但一项围绕 Dask DataFrame 逻辑查询规划的新工作将为你实现这一目标。本文介绍了一些在 dask-expr 中开发的这些变化。
你可以使用以下方式安装和尝试 dask-expr
pip install dask-expr
本文中使用的是 纽约市出租车 数据集。
Dask 表达式
Dask expressions 在 Dask DataFrames 之上提供了一个逻辑查询规划层。我们来看看最初的例子,并研究如何通过查询优化层提高效率。正如最初指出的,有几点不理想
- 我们将所有行读入内存,而不是在读取 parquet 文件时进行过滤。
- 我们将所有列读入内存,而不是只读取必需的列。
- 我们将过滤和聚合应用于所有列,而不是只应用于
"tips"列。
dask-expr 的查询优化层可以帮助我们解决这个问题。它会查看这个表达式并确定并非所有行都是必需的。一个中间层会将过滤器转换为 read_parquet 的有效过滤表达式
df = dd.read_parquet(
"s3://coiled-datasets/uber-lyft-tlc/",
filters=[("hvfhs_license_num", "==", "HV0003")],
)
result = df.sum(numeric_only=True)["tips"]
这仍然会将所有列读入内存,并将计算每个数值列的总和。下一个优化步骤是将列选择也推入 read_parquet 调用中。
df = dd.read_parquet(
"s3://coiled-datasets/uber-lyft-tlc/",
columns=["tips"],
filters=[("hvfhs_license_num", "==", "HV0003")],
)
result = df.sum(numeric_only=True)
这是一个可以手动重写的简单示例。更接近实际工作流程的使用场景可能有数百列,如果你需要其中的非简单子集,重写会非常耗时耗力。
让我们看看如何实现这一点。dask-expr 将用户提供的表达式记录在表达式树中
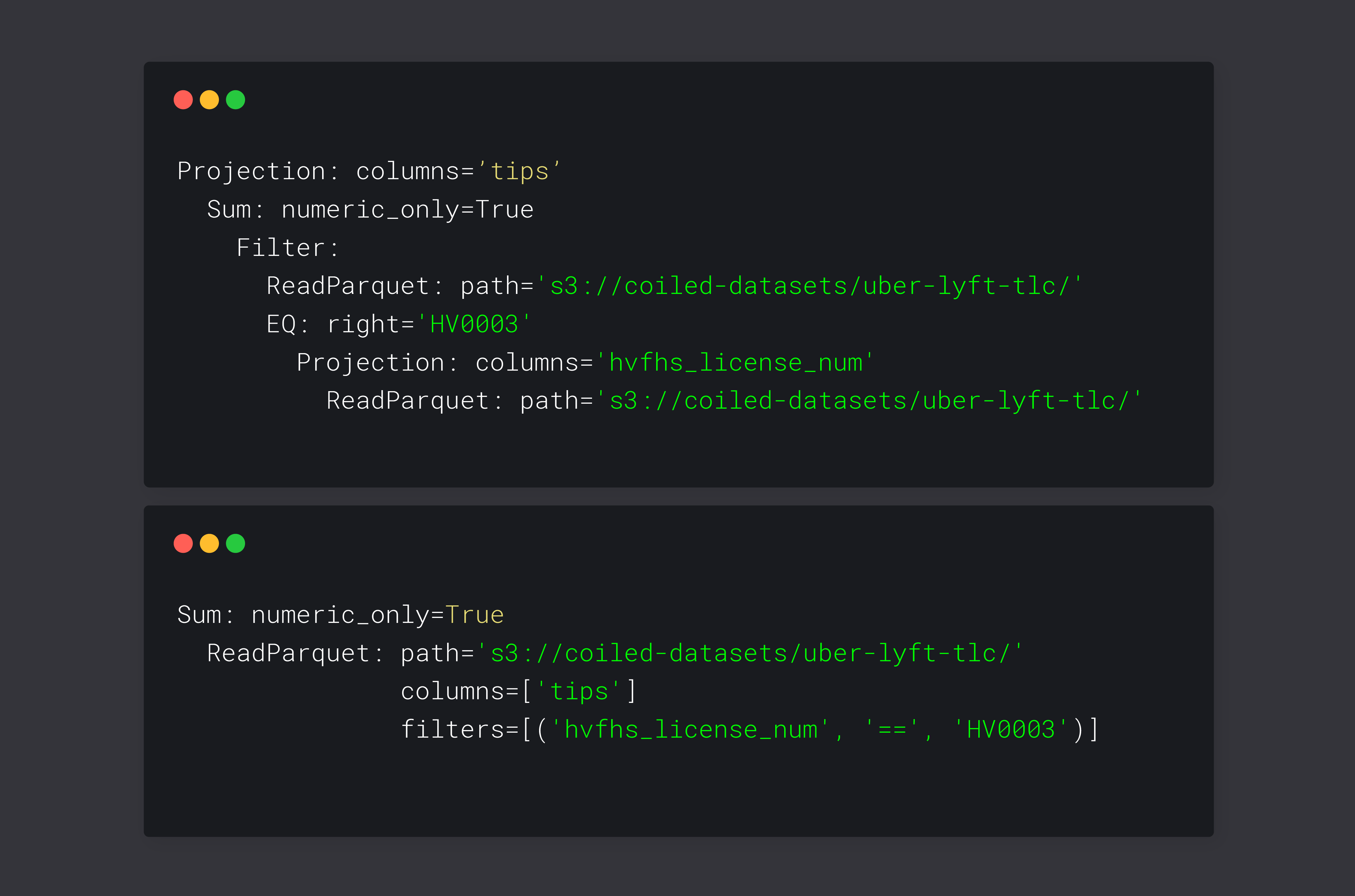
result.pprint()
Projection: columns='tips'
Sum: numeric_only=True
Filter:
ReadParquet: path='s3://coiled-datasets/uber-lyft-tlc/'
EQ: right='HV0003'
Projection: columns='hvfhs_license_num'
ReadParquet: path='s3://coiled-datasets/uber-lyft-tlc/'
这棵树表示表达式的原始形式。我们可以看到,在应用投影和过滤之前,我们会将整个数据集读入内存。值得注意的一点是:看起来我们正在读取数据集两次,但 Dask 能够融合执行相同任务的作业以避免重复计算。让我们重新排序表达式以使其更高效
result.simplify().pprint()
Sum: numeric_only=True
ReadParquet: path='s3://coiled-datasets/uber-lyft-tlc/'
columns=['tips']
filters=[('hvfhs_license_num', '==', 'HV0003')]
这看起来简单多了。dask-expr 重新排序了查询,并将过滤器和列投影推入了 read_parquet 调用中。我们成功地从表达式树中移除了一些步骤,并使剩余的表达式更加高效。这代表了我们最初手动完成的步骤。dask-expr 可以对任意多列执行这些步骤,而不会增加开发人员的负担。
这些只是 dask-expr 中最常见且最容易说明的两种优化技术。一些其他有用的优化已经可用
len(...)将只使用索引计算长度;此外,我们可以忽略许多不会改变 DataFrame 形状的操作,例如replace调用。set_index和sort_values不会立即触发计算。- 更智能地选择
merge算法。 - …
我们仍在添加更多优化技术,以使 Dask DataFrame 查询更高效。
试用一下
该项目目前的状态是,有兴趣的用户应该尝试一下。我们已经发布了一些版本。API 涵盖了 Dask DataFrame API 的很大一部分,并且我们还在不断添加更多内容。我们已经观察到,对于受益于查询优化的工作流程,性能有了非常显著的提升。这些工作流程的内存使用量也有所下降。
我们非常期待您的反馈意见以及改进库的潜在途径。请试用一下,并与我们分享您的体验。
dask-expr 尚未集成到主要的 Dask DataFrame 实现中。您可以使用以下方式安装它
pip install dask-expr
该 API 与 Dask DataFrame 提供的非常相似。它暴露了与 Dask DataFrame 大致相同的方法。在大多数情况下,您可以使用相同的方法。
import dask_expr as dd
您可以在 Readme 中找到支持的操作列表。这个项目仍在积极开发中。API 可能会在没有警告的情况下发生变化。我们的目标是每周发布版本,以便尽快推出新功能。
我们为什么要现在添加这个?
从历史上看,Dask 专注于灵活性和智能调度,而不是查询优化。Dask 内置的分布式调度器使用复杂的算法来确保单个任务的理想调度。它试图确保你的资源得到尽可能高效的利用。图构建过程使 Dask 用户能够构建非常灵活和复杂的图,这些图超出了 SQL 操作的范围。Dask futures API 提供的灵活性需要非常智能的算法,但它使用户能够构建高度复杂的图。下图显示了一个信用风险模型的图

强大的调度器和物理优化的特性使我们能够构建非常复杂的程序,然后这些程序将高效运行。不幸的是,这些优化的特性并不能帮助我们避免调度不必要的工作。这就是目前将高级查询优化构建到 Dask 中的工作重点。
结论
Dask 带有非常智能的分布式调度器,但没有多少逻辑查询规划。这正是我们目前通过在 Dask DataFrame 中构建高级查询优化器来纠正的问题。我们期望改进普通 Dask 工作流程的性能并减少内存使用。
这个 API 已经准备好供有兴趣的用户试用。它涵盖了 DataFrame API 的很大一部分。该库正在积极开发中,我们预计在未来几周和几个月内添加更多有趣的功能。
博客评论由 Disqus 提供支持