Dask DataFrame 现在很快了
作者:Patrick Hoefler
这项工作由 Coiled 和 NVIDIA 工程师开发并支持。特别感谢 Patrick Hoefler 和 Rick Zamora。本文原始版本发布在 docs.coiled.io
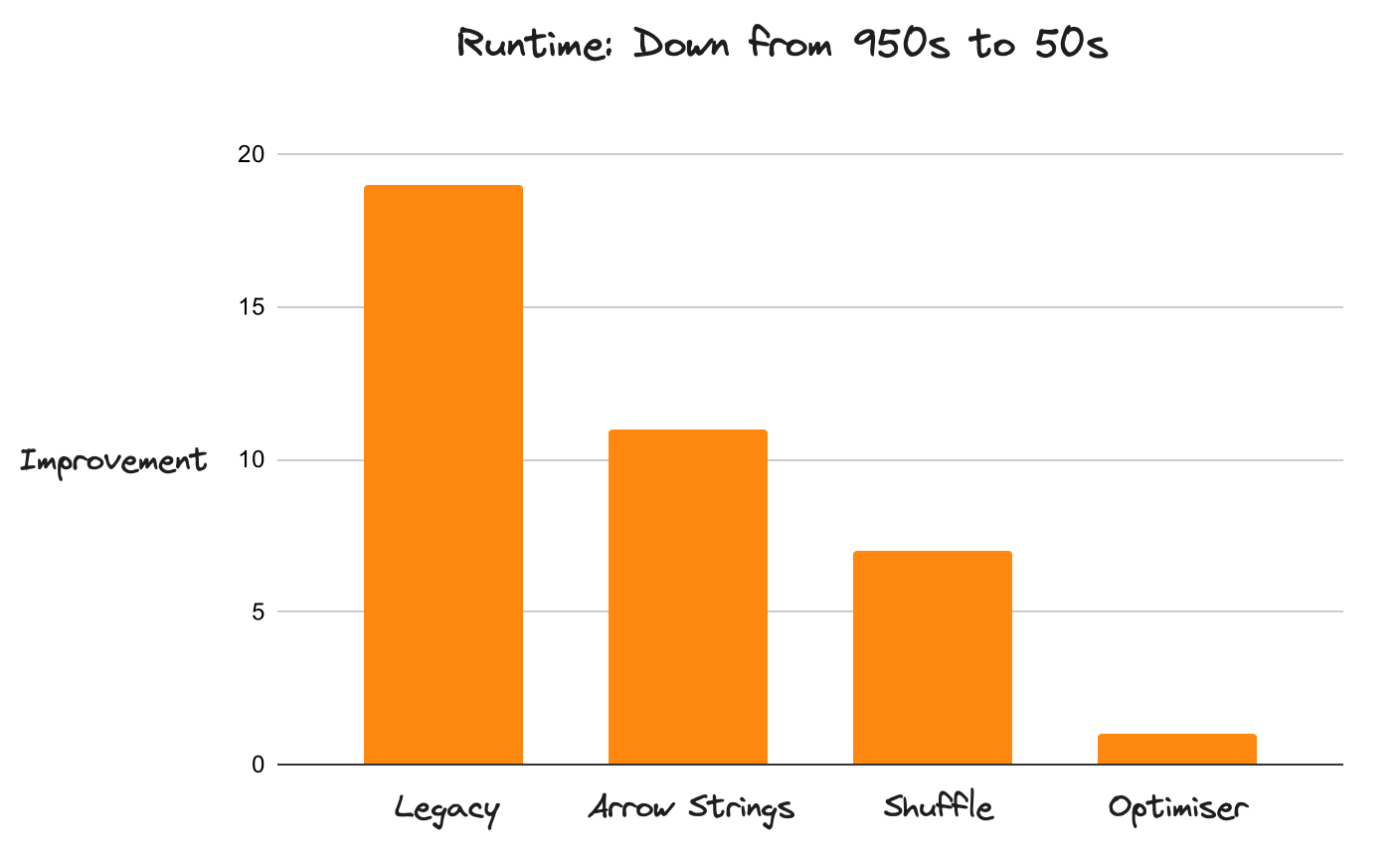
Dask DataFrames 的性能改进
引言
Dask DataFrame 扩展了 pandas DataFrames,使其能够在 100GB-100TB 的规模上运行。
历史上,与该领域的其他工具(如 Spark)相比,Dask 相当慢。由于专注于性能的一系列改进,它现在变得相当快(比以前快约 20 倍)。新的实现使 Dask 从在每个基准测试中都被 Spark 击败,转变为在 TPC-H 查询中经常以显著优势超越 Spark。
Dask DataFrame 的工作负载在许多方面存在问题。性能和内存使用是常见的痛点,对于更大的数据集,Shuffle 不稳定,使得扩展困难。编写高效的代码需要理解太多 Dask 的内部细节。
新的实现改变了这一切。不起作用的地方被完全从零开始重写,现有的实现也得到了改进。这为 Dask DataFrames 奠定了坚实的基础,从而能够在未来实现更快的迭代周期。
我们将介绍三个最突出的变化
我们将介绍这些变化如何影响性能,以及如何让不熟悉分布式计算的新用户也能更高效地使用 Dask。我们还将讨论未来的改进计划。
1. Apache Arrow 支持:高效字符串数据类型
一个 Dask DataFrame 由许多 pandas DataFrames 组成。历史上,pandas 使用 NumPy 处理数值数据,但使用 Python 对象处理文本数据,这效率低下,并且会大幅增加内存使用。对对象数据的操作也会持有 GIL,这对于 pandas 来说影响不大,但对于像 Dask 这样的并行系统来说,对性能是灾难性的。
pandas 2.0 版本引入了对通用 Arrow 数据类型的支持,因此 Dask 现在默认使用 PyArrow 支持的字符串。这要好得多。PyArrow 字符串将内存使用量减少高达 80%,并为字符串操作解锁了多线程。以前受限于可用内存的工作负载现在可以在更少的空间中轻松运行,并且由于不再不断将多余数据溢出到磁盘,它们也快得多。
![]()
旧版 DataFrames 与 Arrow 字符串的内存使用对比
2. 使用新 Shuffle 算法实现更快的 Join
Shuffle 是分布式系统实现排序、Join 和复杂 Group By 操作的关键组成部分。它是一种全对全、网络密集型操作,通常是工作流中最昂贵的部分。Dask 引入了一个新的 Shuffle 系统,这极大地影响了整体性能,尤其是在复杂、数据密集型的工作负载上。
Shuffle 操作本质上是一种全对全的通信操作,其中每个输入分区必须向每个输出分区提供一小部分数据。Dask 之前已经在使用其基于任务的算法,该算法成功地将任务复杂度从 O(n * n) 降低到了 O(log(n) * n),其中 n 是分区数量。这极大地减少了任务数量,但非线性扩展最终无法让 Dask 处理任意大的数据集。
Dask 引入了一种新的 P2P (点对点) Shuffle 方法,将任务复杂度降低到 O(n),这与数据集大小和集群大小呈线性扩展。它还集成了高效的磁盘整合,使得可以轻松地对远大于内存的数据集进行 Shuffle。新系统极其稳定,并且在任何数据规模下都能“正常工作”。
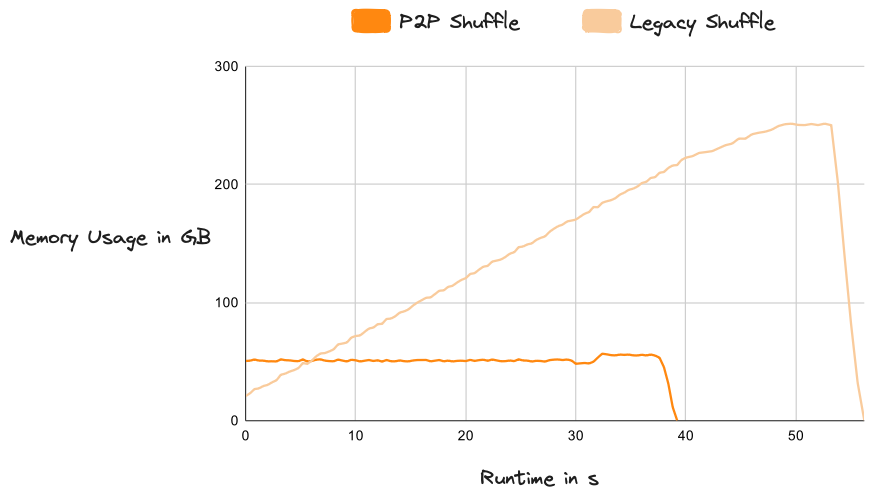
旧版 Shuffle 与 P2P 的内存使用对比
3. 优化器
Dask 本身是惰性的,这意味着它在执行任何实际工作之前会注册您的整个查询。这是一个强大的概念,可以实现许多优化,但历史上 Dask 在过去并没有利用这些知识。Dask 在隐藏内部复杂性方面做得也很差,让用户在应对分布式计算和运行大规模查询的困难时独自摸索。这使得非专业用户编写高效代码非常痛苦。
三月份发布的 Dask 版本 包含了 DataFrame API 的完全重写,以支持查询优化。这是一个重大的进展。新引擎围绕着一个查询优化器,该优化器会重写您的代码,使其更高效并更好地适应 Dask 的优势。让我们深入探讨一些优化策略,以及它们如何使 Dask 运行更快、扩展性更好。
我们将从几个通用优化开始
然后深入探讨更具体的技术,这些技术专门针对分布式系统,特别是 Dask
3.1 列投影
大多数数据集拥有的列都比实际需要的多。删除它们需要预见性(“我需要哪些列来执行此查询?🤔”),因此大多数人在加载数据时不会考虑这一点。这对性能不利,因为携带大量多余数据会拖慢一切。列投影会在不再需要列时立即将其删除。这是一个简单直接的优化,但非常有用。
旧版实现总是从存储中读取所有列,并且仅在用户明确指定时才删除列。只处理更少的数据对于性能和内存使用来说是一个巨大的优势。
优化器会查看查询并确定每个操作需要哪些列。它查看查询的最后一步,然后逐步向数据源回溯,注入删除操作以移除不必要的列。
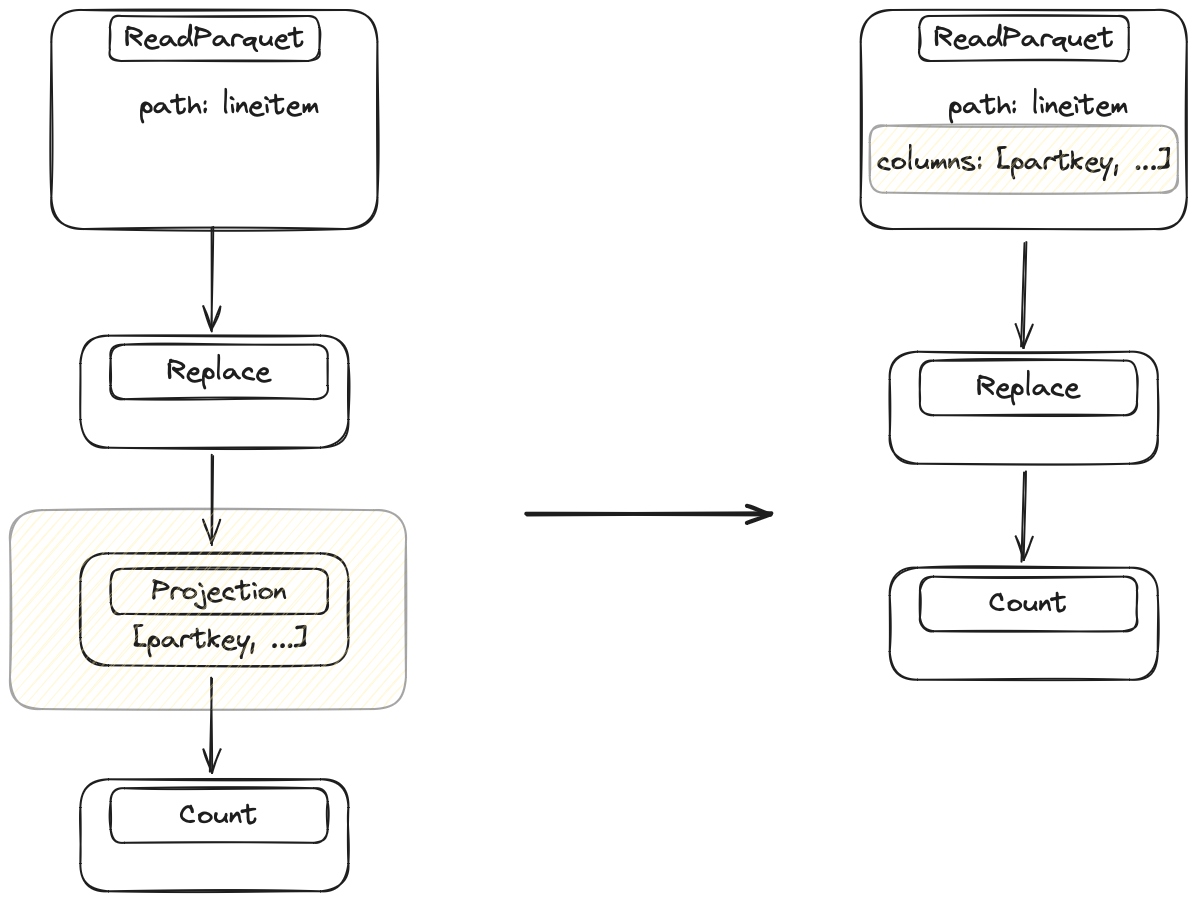
只需要一部分列。Replace 不需要访问所有列,因此 Dask 会直接在 IO 步骤中删除不必要的列。
3.2 过滤下推
过滤下推是另一个通用优化,目标与列投影相同:处理更少的数据。旧版实现不会重新排序过滤操作。新实现会在保持结果不变的情况下,尽可能早地执行过滤操作。
优化器识别查询中的每个过滤器,并查看之前的操作,以判断是否可以将过滤器移近数据源。它会重复此过程,直到找到一个无法与过滤器交换的操作。这比列投影稍微困难一些,因为 Dask 必须确保操作不会改变 DataFrame 的值。例如,交换过滤器和合并操作是没问题的(值不会改变),但交换过滤器和替换操作是无效的,因为值可能会改变,并且以前会被过滤掉的行现在不会被过滤,反之亦然。
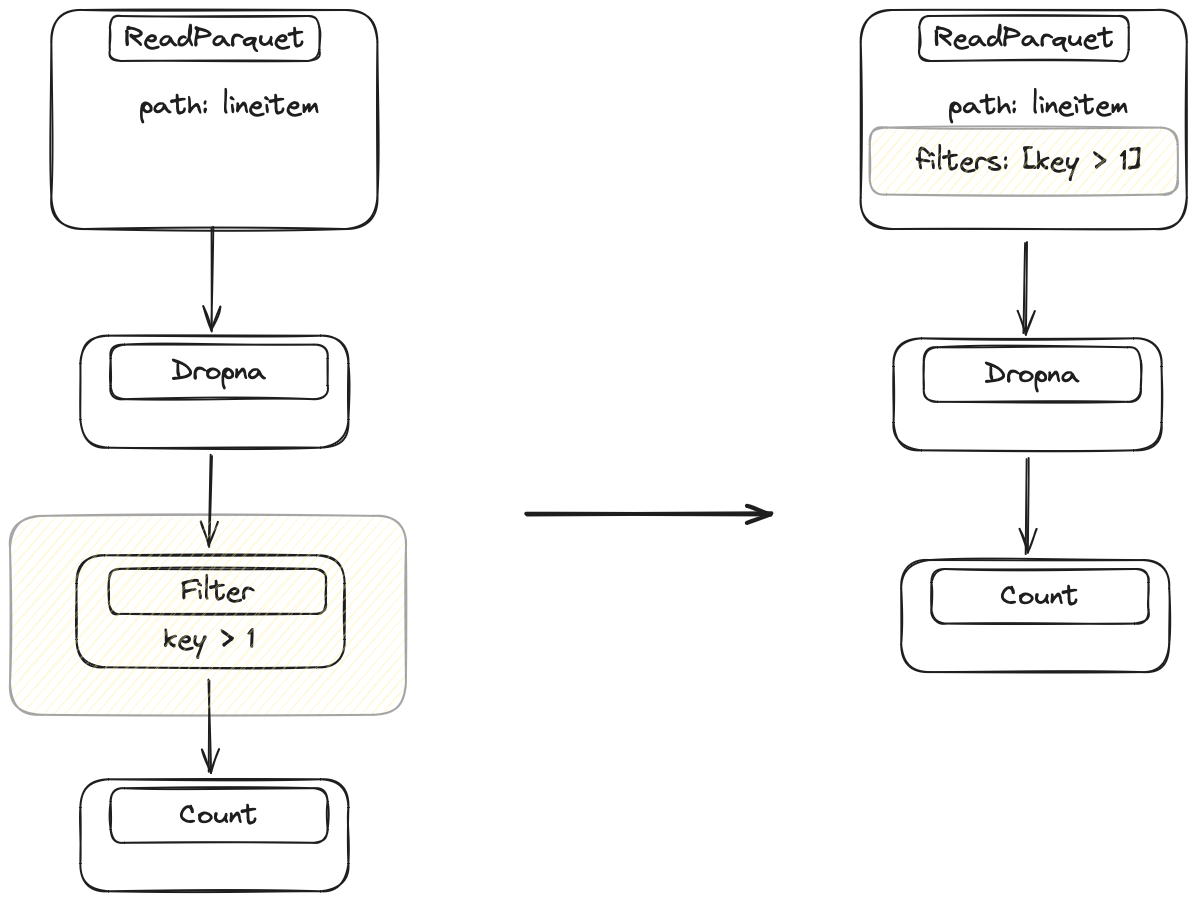
最初,过滤发生在 Dropna 之后,但 Dask 可以在不改变结果的情况下在 Dropna 之前执行过滤。这使得 Dask 可以将过滤器推入 IO 步骤。
此外,如果过滤器足够严格,Dask 甚至可以在 IO 步骤中删除完整的文件。这是最佳情况,更早的过滤带来了巨大的性能提升,甚至减少了从远程存储读取的数据量。
3.3 自动调整分区大小
除了实现上述常见的优化技术外,我们还改进了一个特定于分布式系统和 Dask 用户的常见痛点:最佳分区大小。
Dask DataFrames 由许多称为 分区 的小型 pandas DataFrames 组成。通常,分区数量是预先确定的,并且建议 Dask 用户在缩减或扩展数据后(例如通过删除列、过滤数据或通过 Join 扩展)手动“重新分区”(参见 Dask 文档)。如果没有这一额外步骤,如果 pandas DataFrames 变得太小,Dask 的(通常很小的)开销可能成为瓶颈,导致 Dask 工作流变得非常缓慢。
手动控制分区大小是一项繁琐的任务,作为 Dask 用户,我们不应该为此操心。它也很慢,因为它需要通过网络传输一些分区。Dask DataFrame 现在会自动执行两项操作来帮助解决分区过小的问题
-
根据要计算的数据与原始文件大小的比例,保持每个分区的大小恒定。例如,如果您过滤掉了原始数据集的 80%,Dask 会自动将产生的较小分区合并成数量更少、体积更大的分区。
-
将过小的分区合并成更大的分区,基于一个绝对最小值(默认为 75 MB)。例如,如果您的原始数据集被分割成许多微小文件,Dask 会自动将它们合并。
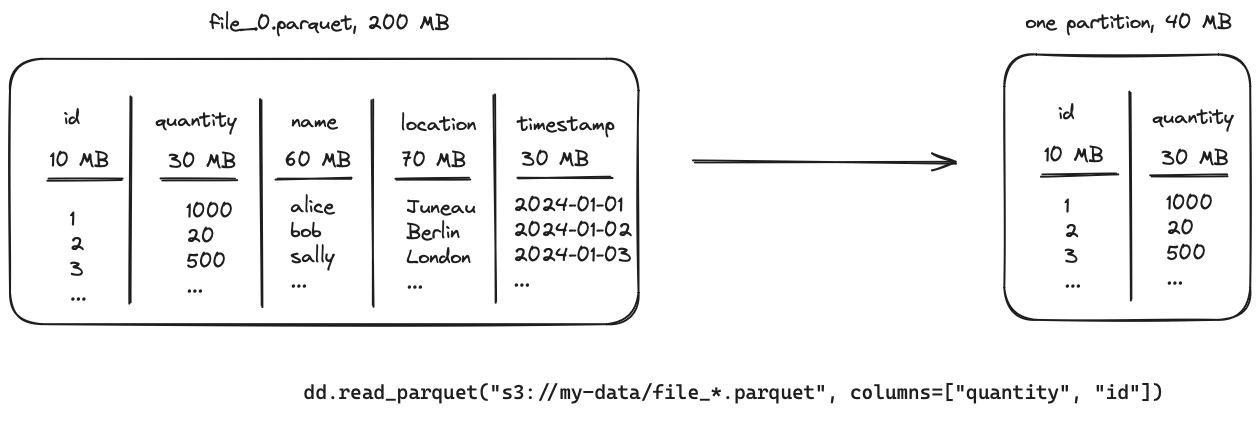
从整个 parquet 文件(共 200MB)中选择占用 40MB 内存的两列。
优化器会查看列的数量以及这些列中数据的大小。它会计算一个比率,用于将多个文件组合成一个分区。
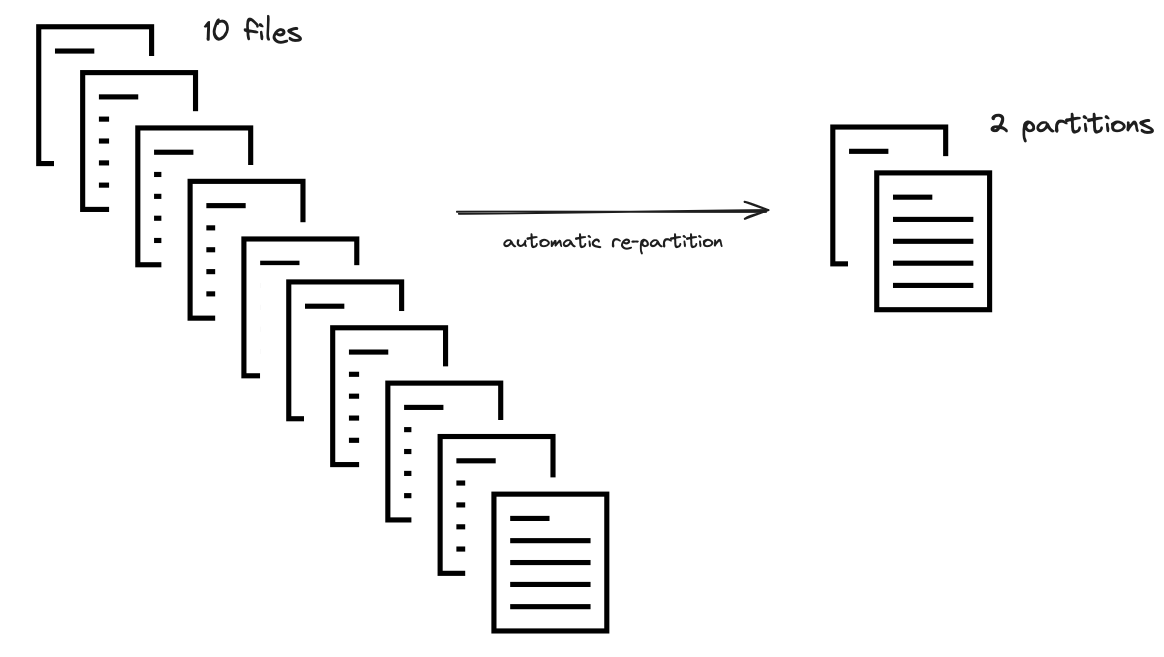
40/200 的比率会导致将五个文件组合成一个分区。
此步骤目前仅限于 IO 操作(如读取 parquet 数据集),但我们计划将其扩展到其他允许廉价合并分区的操作。
3.4 简单的合并和 Join 操作
在单机上使用 pandas 进行合并和 Join 操作通常很廉价,但在分布式环境中却很昂贵。在共享内存中合并数据很廉价,而跨网络合并数据则相当慢,这是由于前面解释的 Shuffle 操作所致。
这是分布式系统中最昂贵的操作之一。旧版实现对每次合并操作都会触发两个输入 DataFrame 的网络传输。这有时是必要的,但非常昂贵。
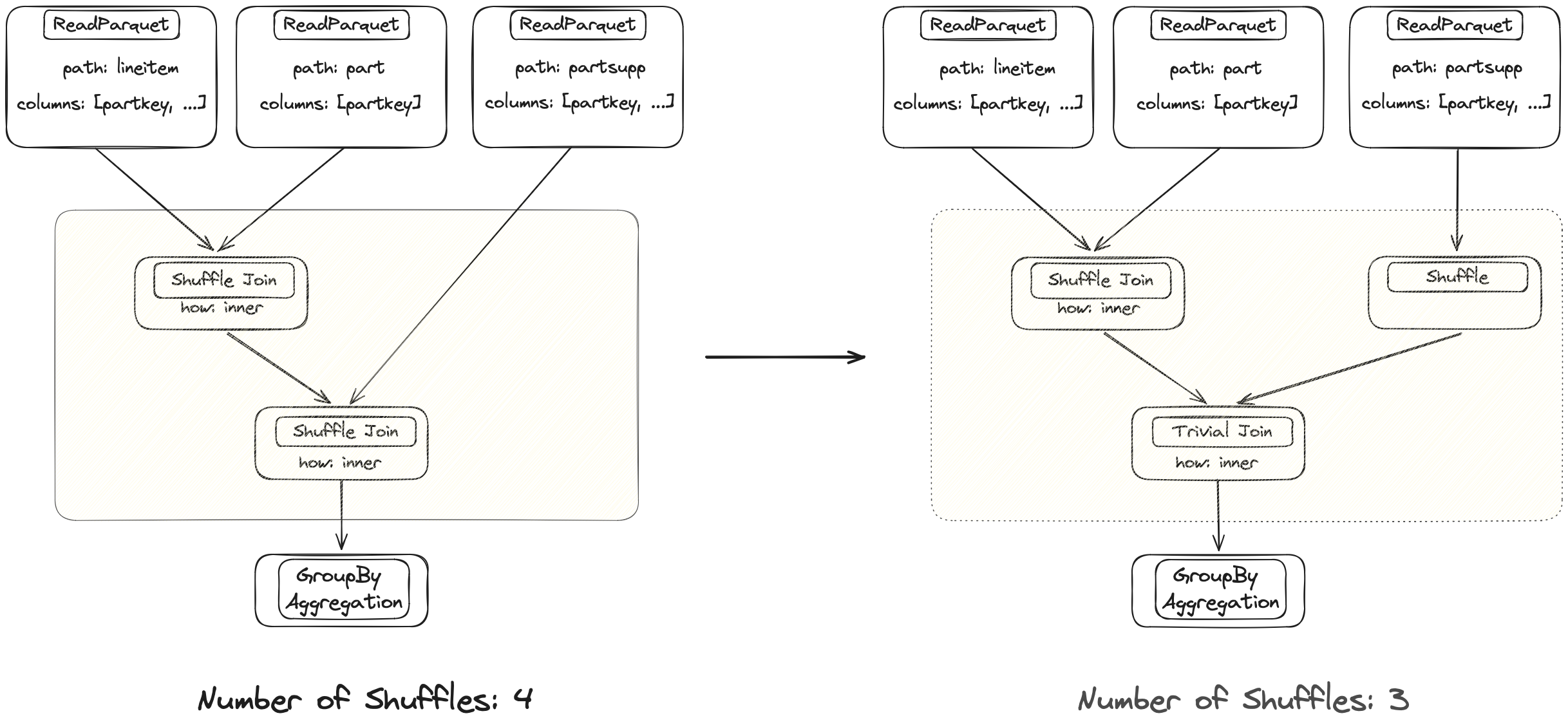
两个 Join 操作都在同一列上执行。左侧 DataFrame 在第一次 Join 后已经正确分区,因此在新实现中,Dask 可以避免再次 Shuffle。
优化器将确定何时需要 Shuffle 以及何时由于数据已经正确对齐而进行简单的 Join 就足够了。这可以使单个合并操作快一个数量级。这也适用于通常需要 Shuffle 的其他操作,例如 groupby().apply()。
Dask 合并操作过去效率低下,导致运行时间很长。优化器修复了这些操作连续发生时的简单情况,但该技术尚不先进。仍有很大的改进潜力。
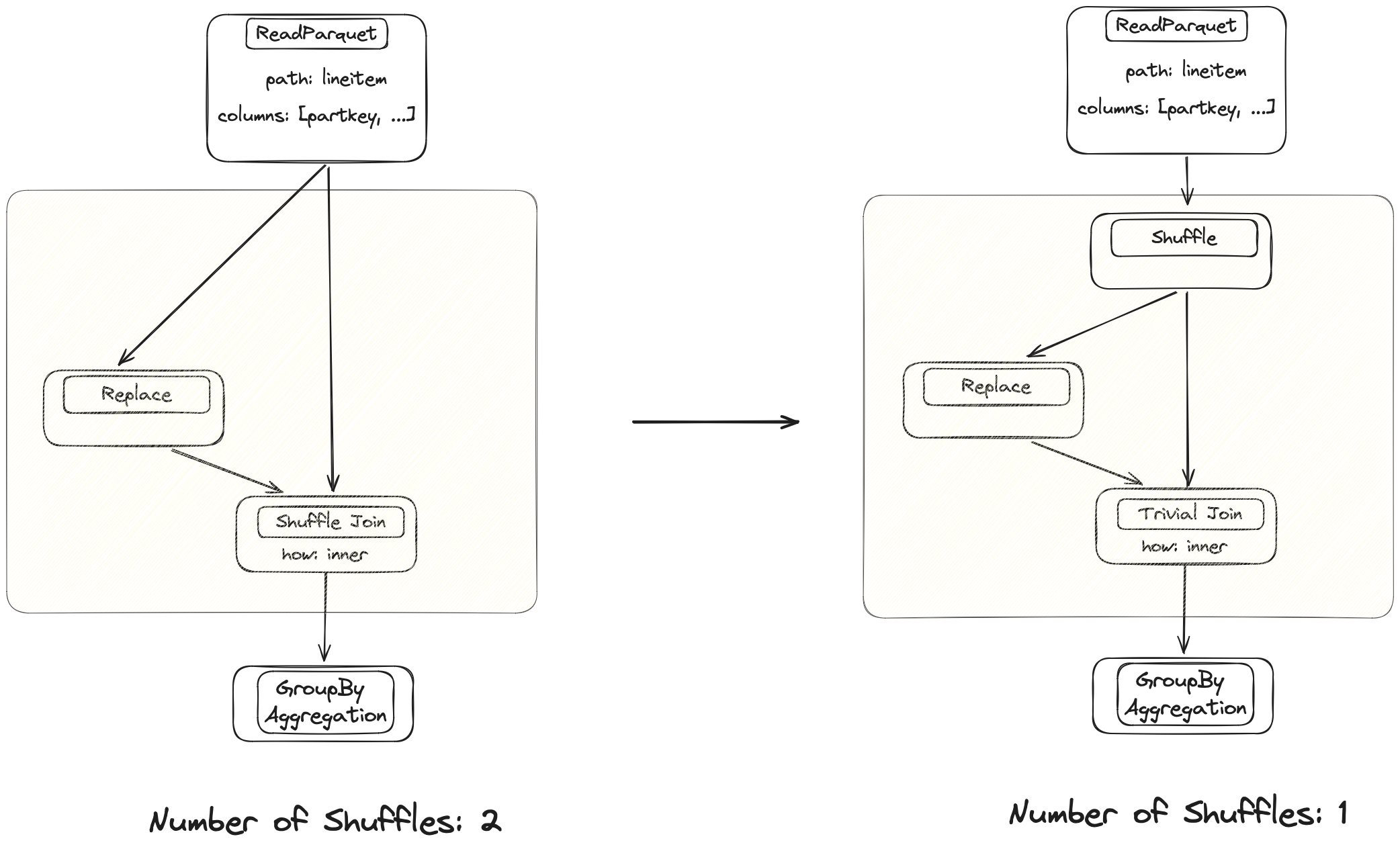
当前实现会 Shuffle 来自同一表的两个分支。在更上游注入一个 Shuffle 节点可以避免其中一个昂贵的操作。
优化器会查看表达式,并在必要时注入 Shuffle 节点,以避免不必要的 Shuffle。
这些改进与旧版实现相比如何?
Dask 现在比以前快了 20 倍。这一改进适用于整个 DataFrame API(而不仅仅是独立的组件),且没有已知的性能退化。Dask 现在可以运行以前在可接受的时间范围内无法完成的工作负载。这种性能提升得益于许多改进的叠加。这不是因为某个方面做得特别好,而是因为没有哪个方面做得特别差。
TPC-H 基准测试查询 3 的性能改进,来源:https://github.com/coiled/benchmarks/tree/main/tests/tpch
性能虽然是最吸引人的改进,但并非唯一变得更好的地方。优化器向用户隐藏了许多复杂性,使得从 pandas 到 Dask 的转换更加容易,因为现在编写性能差的代码要困难得多。整个系统也更加健壮。
新的 API 架构也更容易使用。旧版实现将许多内部复杂性泄露到高级 API 实现中,使得修改变得繁琐。现在添加改进几乎是微不足道的。
未来展望
在过去的 18 个月里,Dask DataFrame 发生了很大变化。旧版 API 通常很难使用,并且在扩展性方面存在问题。新实现废弃了不起作用的部分,并改进了现有实现。现在繁重的工作已经完成,这使得可以更快地迭代改进现状。增量改进现在添加起来几乎是微不足道的。
近期路线图上的几件事
- 自动重新分区:这已部分实现,但在优化过程中选择更高效的分区大小方面还有更多潜力。
- 更快的 Join:这里仍有很多微调工作要做。例如,有一个正在进行的 PR 可以带来 30-40% 的改进。
- Join 重新排序:Dask 尚未实现此功能,但已列入近期路线图
了解更多
本文重点介绍了 Dask DataFrame 的一系列改进,以及由此带来的速度和可靠性提升。如果您正在 Dask 和其他流行的 DataFrame 工具之间做选择,您可能还会考虑
- 大规模 DataFrame 对比:TPC-H,该对比研究了 Dask、Spark、Polars 和 DuckDB 在 10GB 到 10TB 数据集上的性能,包括本地和云端。
博客评论由 Disqus 提供支持