分布式 Dask 数组
这项工作由 Continuum Analytics 和 XDATA Program 支持,是 Blaze Project 的一部分
在本文中,我们将使用 NumPy 并行配合 dask.array 分析集群上的气象数据。我们将重点介绍以下内容:
- 如何使用 Sun GridEngine 等作业调度器设置分布式调度器。
- 如何将网络文件系统 (NFS) 中的 NetCDF 数据加载到分布式 RAM 中
- 如何使用 dask.arrays 操作数据
- 如何使用 IPython 部件与分布式数据交互
这篇博文有一个配套的 截屏视频,可能比文字版本更有趣一些。
这是关于 dask.distributed 的系列博文中的第三篇
- Dask Bags 处理 GitHub 数据
- Dask DataFrames 处理 HDFS 数据
- Dask Arrays 处理 NetCDF 数据
设置
我们希望模拟典型的学术集群设置,使用 SunGridEngine 等作业调度器(类似于 SLURM、Torque、PBS 脚本和其他技术)、共享网络文件系统以及 NetCDF 文件(类似于 HDF5)中存储的典型二进制数组。
为此,我们使用了 Starcluster,这是一种在 EC2 上使用 SGE 和 NFS 快速设置此类集群的方法,并且我们从 European Centre for Meteorology and Weather Forecasting 下载了数据。
为了使用 SGE 部署 Dask 的分布式调度器,我们在主节点上创建了一个调度器。
sgeadmin@master:~$ dscheduler
distributed.scheduler - INFO - Start Scheduler at: 172.31.7.88:8786
然后使用 qsub 命令启动四个 Dask worker,并指向调度器地址。
sgeadmin@master:~$ qsub -b y -V dworker 172.31.7.88:8786
Your job 1 ("dworker") has been submitted
sgeadmin@master:~$ qsub -b y -V dworker 172.31.7.88:8786
Your job 2 ("dworker") has been submitted
sgeadmin@master:~$ qsub -b y -V dworker 172.31.7.88:8786
Your job 3 ("dworker") has been submitted
sgeadmin@master:~$ qsub -b y -V dworker 172.31.7.88:8786
Your job 4 ("dworker") has been submitted
几秒钟后,这些 worker 会在集群中的各个节点上启动并连接到调度器。
在单台机器上加载样本数据
在共享的 NFS 驱动器上,我们下载了几个 NetCDF3 文件,每个文件都包含单日每六小时的全球温度数据。
>>> from glob import glob
>>> filenames = sorted(glob('*.nc3'))
>>> filenames[:5]
['2014-01-01.nc3',
'2014-01-02.nc3',
'2014-01-03.nc3',
'2014-01-04.nc3',
'2014-01-05.nc3']
我们使用 conda 安装 netCDF4 库,并编写一个小型函数来从单个文件名读取 t2m 变量,该变量表示“两米海拔高度的温度”。
conda install netcdf4
import netCDF4
def load_temperature(fn):
with netCDF4.Dataset(fn) as f:
return f.variables['t2m'][:]
这将单个文件转换为内存中的单个 numpy 数组。我们可以在本地对单个文件调用此函数,如下所示:
>>> load_temperature(filenames[0])
array([[[ 253.96238624, 253.96238624, 253.96238624, ..., 253.96238624,
253.96238624, 253.96238624],
[ 252.80590921, 252.81070124, 252.81389593, ..., 252.79792249,
252.80111718, 252.80271452],
...
>>> load_temperature(filenames[0]).shape
(4, 721, 1440)
我们的数据集维度为 (time, latitude, longitude)。请注意,上面提到每天有四个时间条目(每六小时测量一次)。
不幸的是,Starcluster 设置的 NFS 相当小。我们只能在共享磁盘中存储大约五个月(136 天)的数据。
在集群上加载数据
我们希望在四个 worker 中的每一个上调用 load_temperature 函数处理我们的 filenames 列表。我们将一个 Dask Executor 连接到我们的调度器地址,然后将我们的函数映射到我们的 filenames 上。
>>> from distributed import Executor, progress
>>> e = Executor('172.31.7.88:8786')
>>> e
<Executor: scheduler=172.31.7.88:8786 workers=4 threads=32>
>>> futures = e.map(load_temperature, filenames)
>>> progress(futures)

完成后,我们将在每个 worker 的内存中分散存储多个 numpy 数组。
与 dask.array 协调
我们将这些 numpy 数组协调成一个逻辑上的单个 dask 数组,如下所示:
>>> from distributed.collections import futures_to_dask_arrays
>>> xs = futures_to_dask_arrays(futures) # many small dask arrays
>>> import dask.array as da
>>> x = da.concatenate(xs, axis=0) # one large dask array, joined by time
>>> x
dask.array<concate..., shape=(544, 721, 1440), dtype=float64, chunksize=(4, 721, 1440)>
这个逻辑上的单个 dask 数组由分布在集群中的 136 个 numpy 数组组成。对单个 dask 数组的操作将触发对每个 numpy 数组的多次操作。
与分布式数据交互
现在我们可以使用标准的 NumPy 语法和其他 PyData 库与我们的数据集交互。下面我们提取一个时间切片,并使用 matplotlib 将其渲染到屏幕上。
from matplotlib import pyplot as plt
plt.imshow(x[100, :, :].compute(), cmap='viridis')
plt.colorbar()

在这篇博文的 截屏视频版本 中,我们将此功能连接到 IPython 滑动部件并按时间滚动,这很有趣。
速度
我们对一些代表性操作进行了基准测试,以查看分布式系统的优点和缺点。
单个元素
这个单个元素计算访问我们数据集中单个 NumPy 数组中的一个数字。它受限于从客户端到调度器,再到 worker,然后返回的网络往返时间。
>>> %time x[0, 0, 0].compute()
CPU times: user 4 ms, sys: 0 ns, total: 4 ms
Wall time: 9.72 ms
单个时间切片
这个时间切片计算从单个 worker 上的单个 NumPy 数组中提取大约 8MB 数据。它可能受限于网络带宽。
>>> %time x[0].compute()
CPU times: user 24 ms, sys: 24 ms, total: 48 ms
Wall time: 274 ms
均值计算
这个均值计算涉及我们所有 worker 上每个 NumPy 数组中的每个数字。计算均值相当快,因此这可能受限于调度器开销。
>>> %time x.mean().compute()
CPU times: user 88 ms, sys: 0 ns, total: 88 ms
Wall time: 422 ms
交互式部件
为了让这些时间感觉更直观,我们将这些计算连接到 IPython 部件。
第一个例子看起来相当流畅。这只涉及单个 worker 并返回一个很小的结果。它很便宜,因为它索引的方式与我们的 NumPy 数组按时间分割的方式对齐得很好。
@interact(time=[0, x.shape[0] - 1])
def f(time):
return x[time, :, :].mean().compute()

第二个例子不太流畅,因为我们跨越了 NumPy 块进行索引。每次计算都会触及所有数据。尽管如此,它仍然不算太差,并且以当今交互式分布式数据科学的标准来看是相当可接受的。
@interact(lat=[0, x.shape[1] - 1])
def f(lat):
return x[:, lat, :].mean().compute()

归一化数据
到目前为止,我们只对数据执行了简单的计算,通常是提取均值。上面的温度图像看起来并不令人惊讶。该图像的主导因素是陆地比海洋温暖,赤道比两极温暖。这没什么可奇怪的。
为了让事情更有趣,我们减去均值并除以随时间的标准差。这将告诉我们某个特定点相对于该点随时间的所有测量值而言,其温度异常偏高或偏低。这为我们提供了一种类似于地理位置 Z 分数的数据。
z = (x - x.mean(axis=0)) / x.std(axis=0)
z = e.persist(z)
progress(z)
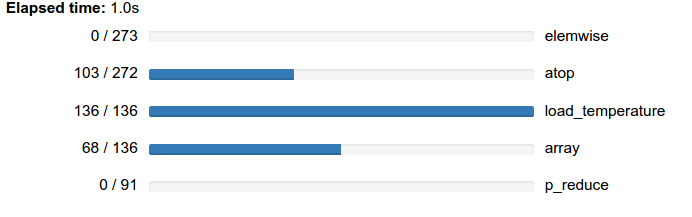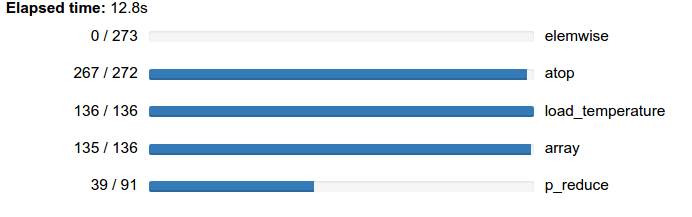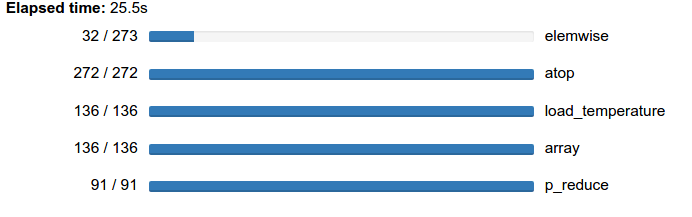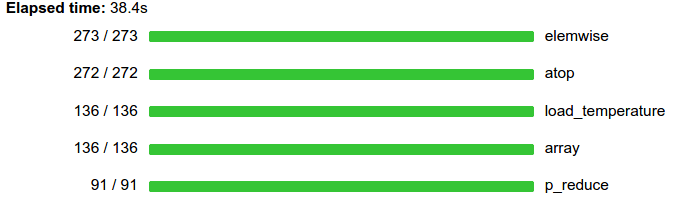
plt.imshow(z[slice].compute(), cmap='RdBu_r')
plt.colorbar()
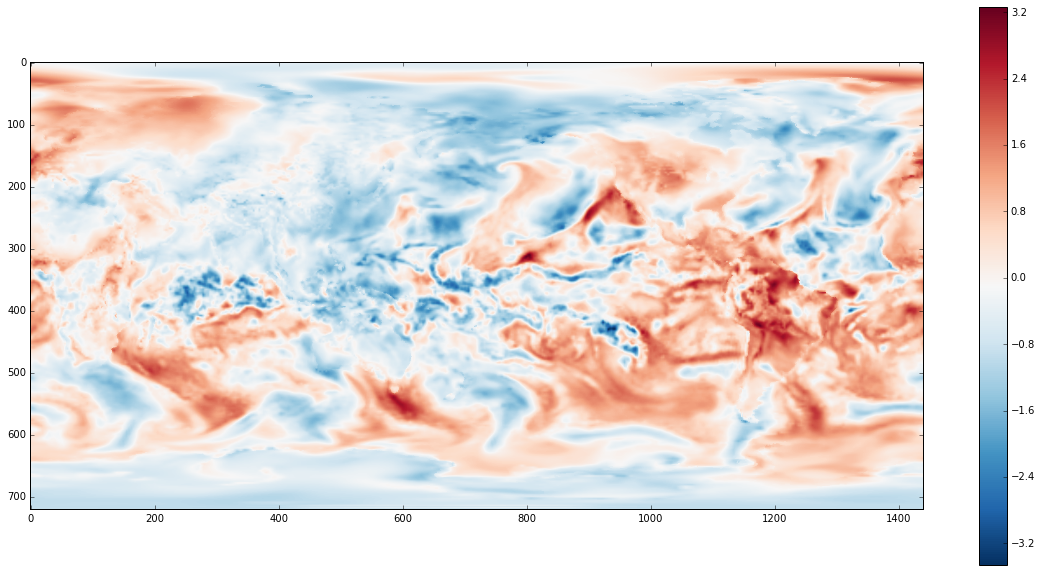
现在我们可以看到更多当天气流的精细结构。在 截屏视频版本 中,我们也将此数据集连接到滑动部件并查看不同时间的数据。
为了减小文件大小,我在本文中避免展示完整图像变化的 GIF 图,不过我们可以轻松地在这里渲染一个显示按纬度划分的平均温度随时间变化的图表。
import numpy as np
xrange = 90 - np.arange(z.shape[1]) / 4
@interact(time=[0, z.shape[0] - 1])
def f(time):
plt.figure(figsize=(10, 4))
plt.plot(xrange, z[time].mean(axis=1).compute())
plt.ylabel("Normalized Temperature")
plt.xlabel("Latitude (degrees)")
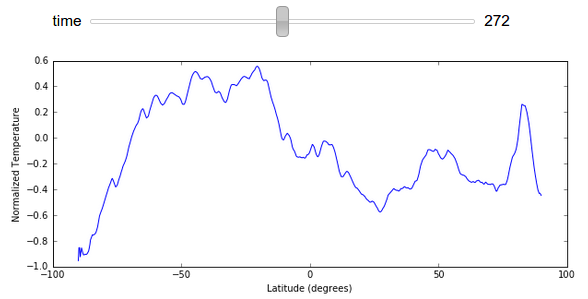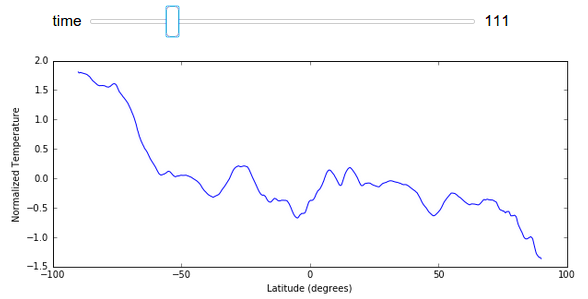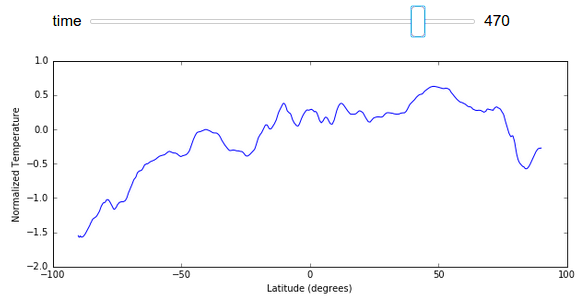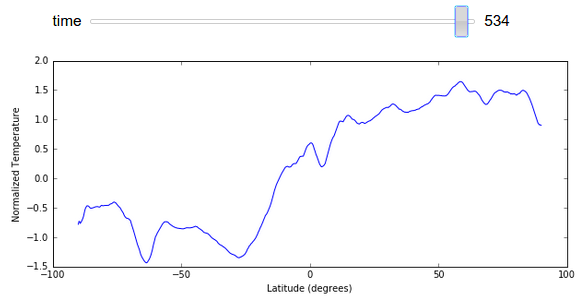
结论
我们展示了如何在典型的学术集群上使用分布式 dask.arrays。我就这个话题与不同的团队进行过几次交流;这似乎是一个常见的使用场景。我希望本文开头的说明对其他人有所帮助。
以直观的方式将交互式部件与集群上的数据结合起来,对我来说非常有成就感。这种在大数据集上的流畅交互是现代数据科学中的一个核心问题。
遇到的问题
一如既往,我将包含一个部分来介绍哪些方面做得不够好,或者如果时间充裕我会做些什么。
- 没有高级的
read_netcdf函数:我们不得不使用executor.map的中级 API 来构建我们的 dask 数组。这对初学者来说有点麻烦。我们应该改进 dask.array 中现有的高级函数,使其能够可靠地处理分布式数据的情况。 - 需要一个更大的问题:我们的数据集可以放入一台 Macbook Pro。一个无法从单台机器上有效研究的更大的数据集才能真正巩固这项技术的必要性。
- 更简单的部署:上面使用
qsub的解决方案虽然直接,但并非总是对初学者友好。此外,虽然 SGE 很常见,但还有其他几种同样常见的系统。我们需要思考更好的方法来为用户自动化此过程。 - XArray 集成:许多人在单台机器上通过 XArray 使用 dask.array,XArray 是一个用于分析带标签多维数组的优秀库,尤其在气候科学中很常见。将这种新的分布式工作集成到 XArray 项目中会很好。我怀疑这主要涉及处理上面描述的数据摄取问题。
- 归约速度:标准化温度
z的计算花费了惊人的长时间。我想研究一下是什么阻碍了这项计算。
链接
博客评论由 Disqus 提供