Dask 和 Scikit-Learn -- 模型并行化 使用 Dask 并行化网格搜索
作者:Jim Crist
这篇文章由 Jim Crist 撰写。原文发布于 http://jcrist.github.io/dask-sklearn-part-1.html(排版更好)
这是探讨将 dask 和 scikit-learn 结合的一些最新实验系列文章的第一篇。这些实验已形成一个小型的(且处于极早期 alpha 阶段的)库,可在此处找到。
在开始之前,我想先说明以下几点:
- 我不是机器学习专家。不要将此文视为如何进行机器学习的指南,下面使用的 scikit-learn 可能过于简单。
- 这里讨论的所有代码都在变化中,不应视为稳定或健壮的代码。话虽如此,如果您对机器学习有所了解并愿意提供帮助,我非常乐意收到问题报告或拉取请求 :)。
机器学习中算法的并行化有几种方式。有些算法可以实现数据并行(跨特征或跨样本)。本文我们将重点关注模型并行(在不同模型中使用相同数据),并深入探讨 GridSearchCV 的一个 dask 化实现。
什么是网格搜索?
许多机器学习算法都有超参数,可以通过调整来提高结果估计器的性能。 网格搜索是优化这些参数的一种方法——它通过对这些参数的子集(“网格”)进行笛卡尔积式的参数遍历,然后选择最佳的结果估计器来实现。由于这是在同一数据集上拟合多个独立的估计器,因此可以相当容易地进行并行化。
使用 scikit-learn 进行网格搜索
在 scikit-learn 中,使用 GridSearchCV 类进行网格搜索,并且可以(可选地)使用 joblib 进行自动并行化。
最好通过一个例子来说明这一点。首先,我们将创建一个示例数据集用于分类:
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=10000,
n_features=500,
n_classes=2,
n_redundant=250,
random_state=42)
为了解决这个分类问题,我们将创建一个由 PCA 和 LogisticRegression 组成的 pipeline。
from sklearn import linear_model, decomposition
from sklearn.pipeline import Pipeline
logistic = linear_model.LogisticRegression()
pca = decomposition.PCA()
pipe = Pipeline(steps=[('pca', pca),
('logistic', logistic)])
这两个类都有几个超参数,我们将只对其中的几个进行网格搜索。
#Parameters of pipelines can be set using ‘__’ separated parameter names:
grid = dict(pca__n_components=[50, 100, 250],
logistic__C=[1e-4, 1.0, 1e4],
logistic__penalty=['l1', 'l2'])
最后,我们可以创建一个 GridSearchCV 的实例,并执行网格搜索。参数 n_jobs=-1 告诉 joblib 使用我所有的核心数(8)对应的进程数。
>>> from sklearn.grid_search import GridSearchCV
>>> estimator = GridSearchCV(pipe, grid, n_jobs=-1)
>>> %time estimator.fit(X, y)
CPU times: user 5.3 s, sys: 243 ms, total: 5.54 s
Wall time: 21.6 s
这里发生了什么:
- 为每个参数组合和测试-训练集创建了一个估计器(scikit-learn 的网格搜索默认也进行 3 折交叉验证)。
- 每个估计器都在其对应的训练数据集上进行了 fit(拟合)。
- 然后每个估计器都在其对应的测试数据集上进行了 score(评分)。
- 根据这些分数选择了最佳的参数集。
- 然后使用最佳参数在所有数据上重新 fit(拟合)了一个新的估计器。
相应地,最佳分数、参数和估计器都可以作为属性在结果对象上找到。
>>> estimator.best_score_
0.89290000000000003
>>> estimator.best_params_
{'logistic__C': 0.0001, 'logistic__penalty': 'l2', 'pca__n_components': 50}
>>> estimator.best_estimator_
Pipeline(steps=[('pca', PCA(copy=True, n_components=50, whiten=False)), ('logistic', LogisticRegression(C=0.0001, class_weight=None, dual=False,
fit_intercept=True, intercept_scaling=1, max_iter=100,
multi_class='ovr', n_jobs=1, penalty='l2', random_state=None,
solver='liblinear', tol=0.0001, verbose=0, warm_start=False))])<div class=md_output>
{'logistic__C': 0.0001, 'logistic__penalty': 'l2', 'pca__n_components': 50}
使用 dask-learn 进行网格搜索
这里我们将使用 dask-learn 重复相同的 fit(拟合)过程。我尽量使其与 scikit-learn 接口保持一致,尽管并非所有功能都已实现。这里唯一真正改变的是 GridSearchCV 的导入。我们不需要 n_jobs 关键字,因为它默认会跨所有核心进行并行化。
>>> from dklearn.grid_search import GridSearchCV as DaskGridSearchCV
>>> destimator = DaskGridSearchCV(pipe, grid)
>>> %time destimator.fit(X, y)
CPU times: user 16.3 s, sys: 1.89 s, total: 18.2 s
Wall time: 5.63 s
和之前一样,最佳分数、参数和估计器都可以作为对象的属性找到。这里我们仅展示它们是等效的。
>>> destimator.best_score_ == estimator.best_score_
True
>>> destimator.best_params_ == estimator.best_params_
True
>>> destimator.best_estimator_
Pipeline(steps=[('pca', PCA(copy=True, n_components=50, whiten=False)), ('logistic', LogisticRegression(C=0.0001, class_weight=None, dual=False,
fit_intercept=True, intercept_scaling=1, max_iter=100,
multi_class='ovr', n_jobs=1, penalty='l2', random_state=None,
solver='liblinear', tol=0.0001, verbose=0, warm_start=False))])<div class=md_output>
{'logistic__C': 0.0001, 'logistic__penalty': 'l2', 'pca__n_components': 50}
为什么 dask 版本更快?
如果您查看上面的时间,您会注意到 dask 版本比 scikit-learn 版本快了 约 4 倍。这并非因为我们优化了 Pipeline 的任何部分,也不是因为 joblib 有大量开销(相反,joblib 做了一些非常了不起的事情,我不得不构建一个有点刻意的例子才能如此大幅地击败它)。原因仅仅是 dask 版本做的工作更少。
这最好用伪代码来解释。上面 scikit-learn 版本(串行执行)的伪代码看起来像这样:
for X_train, X_test, y_train, y_test in cv:
for n in grid['pca__n_components']:
for C in grid['logistic__C']:
for penalty in grid['logistic__penalty']:
# Create and fit a PCA on the input data
pca = PCA(n_components=n).fit(X_train, y_train)
# Transform both the train and test data
X_train2 = pca.transform(X_train)
X_test2 = pca.transform(X_test)
# Create and fit a LogisticRegression on the transformed data
logistic = LogisticRegression(C=C, penalty=penalty)
logistic.fit(X_train2, y_train)
# Score the total pipeline
score = logistic.score(X_test2, y_test)
# Save the score and parameters
scores_and_params.append((score, n, C))
# Find the best set of parameters (for some definition of best)
find_best_parameters(scores)
这段代码循环遍历交叉验证集和所有参数组合的笛卡尔积,然后为每个组合创建并 fit(拟合)一个新的估计器。虽然这属于高度并行任务(embarrassingly parallel),但也可能导致重复工作,因为 pipeline 中较早的阶段会在相同的参数 + 数据组合上多次 refit(重新拟合)。
相比之下,dask 版本对所有输入进行哈希(形成一种 Merkle DAG),从而共享中间结果。与上面的伪代码类似,dask 版本可能看起来像这样:
for X_train, X_test, y_train, y_test in cv:
for n in grid['pca__n_components']:
# Create and fit a PCA on the input data
pca = PCA(n_components=n).fit(X_train, y_train)
# Transform both the train and test data
X_train2 = pca.transform(X_train)
X_test2 = pca.transform(X_test)
for C in grid['logistic__C']:
for penalty in grid['logistic__penalty']:
# Create and fit a LogisticRegression on the transformed data
logistic = LogisticRegression(C=C, penalty=penalty)
logistic.fit(X_train2, y_train)
# Score the total pipeline
score = logistic.score(X_test2, y_test)
# Save the score and parameters
scores_and_params.append((score, n, C, penalty))
# Find the best set of parameters (for some definition of best)
find_best_parameters(scores)
这仍然可以并行化,但方式不那么直接——图结构比简单的 map-reduce 模式要复杂一些。值得庆幸的是,dask 调度器完全能够处理任意的图拓扑结构。下面是一个 GIF,展示了 dask 调度器(特别是线程调度器)如何执行上述网格搜索。每个矩形代表数据,每个圆形代表任务。每个元素都按颜色分类:
-
红色表示正在积极占用资源。这些是正在线程中执行的任务,或占用内存的中间结果。
-
蓝色表示已完成或已释放。这些是已经完成的任务,或因不再需要而从内存中释放的数据。
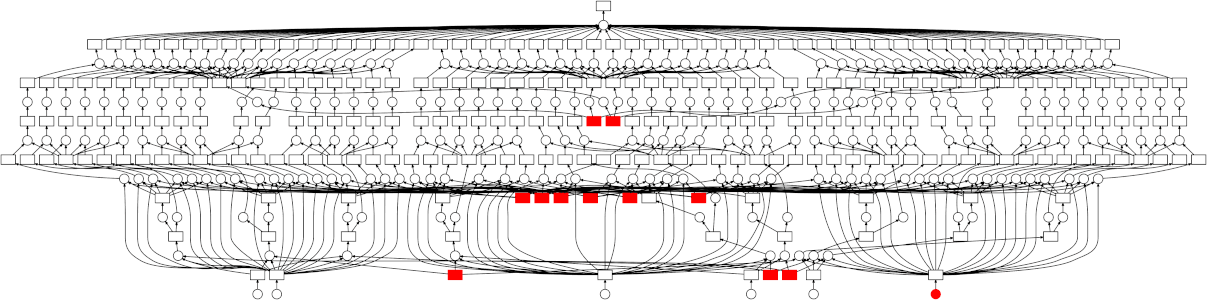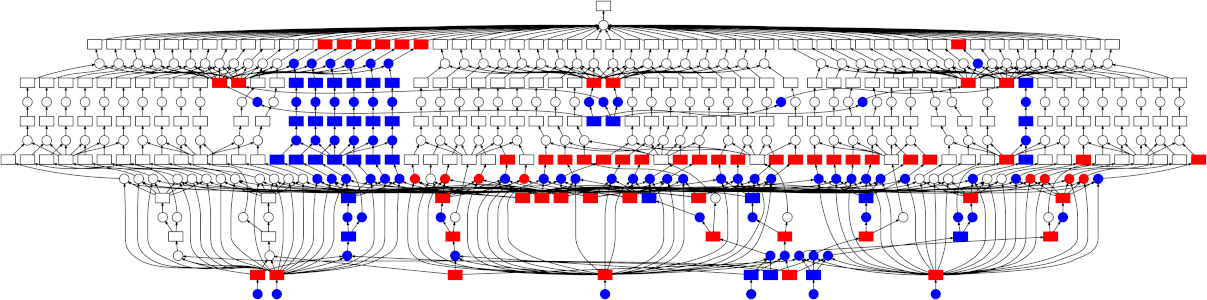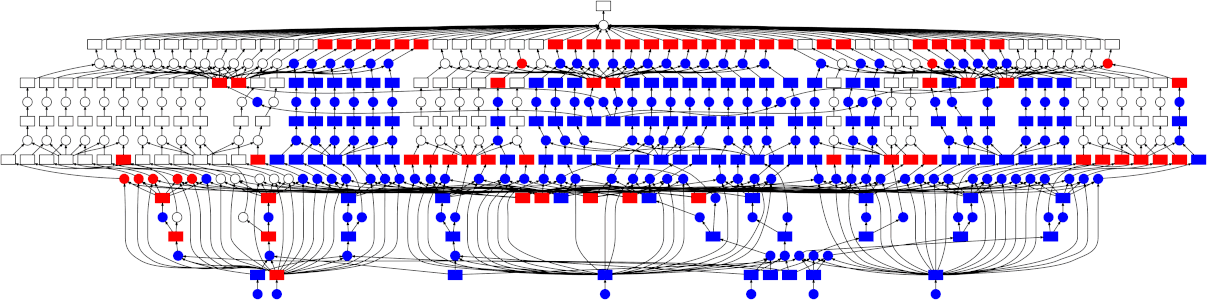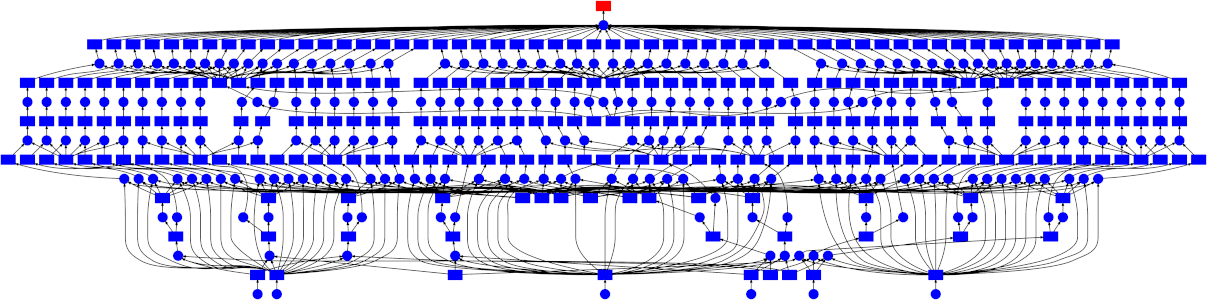
查看跟踪图,有几点比较突出:
-
我们很好地共享了中间结果。pipeline 中的每个步骤在相同的参数/数据下只会 fit(拟合)一次,导致某些中间结果有许多依赖任务。
-
调度器在快速完成释放数据所需的任务方面做得很好。这在这里不太重要(因为没有任何中间结果占用大量内存),但对于其他工作负载来说非常有用。有关此内容的更多讨论,请参阅 Matt Rocklin 此处精彩的博文。
使用 dask-learn 进行分布式网格搜索
dask 中使用的调度器是可配置的。默认调度器(上面使用的)是线程调度器 (threaded scheduler),但我们可以很方便地将其替换为分布式调度器 (distributed scheduler)。这里我只是启动了两个本地 worker 进行演示,但这在多台机器上同样有效。
>>> from distributed import Executor
>>> # Create an Executor, and set it as the default scheduler
>>> exc = Executor('10.0.0.3:8786', set_as_default=True)
>>> exc
<Executor: scheduler="10.0.0.3:8786" processes=2 cores=8>
>>> %time destimator.fit(X, y)
CPU times: user 1.69 s, sys: 433 ms, total: 2.12 s
Wall time: 7.66 s
>>> %time destimator.fit(X, y)
CPU times: user 1.69 s, sys: 433 ms, total: 2.12 s
Wall time: 7.66 s
>>> (destimator.best_score_ == estimator.best_score_ and
... destimator.best_params_ == estimator.best_params_)
True
请注意,这比线程执行稍微慢一些,因此对于这种工作负载来说意义不大,但对于其他工作负载可能有用。
效果好的方面
-
实现此功能的代码相当短。还有一个
RandomizedSearchCV的实现,也只额外增加了几行代码(优秀的类继承结构万岁!)。这两个实现都尽可能使用了 dask.delayed,而不是直接操作 dask 图,这也使代码易于阅读。 -
由于 dask 内部使用的哈希机制(它是可扩展的!),避免了重复计算。
-
由于图结构与调度器是分离的,只需额外增加几行代码,这就能在本地和分布式环境下工作。
注意事项和可以改进的地方
-
scikit-learn 的 API 使用了 mutation(修改)(
est.fit(X, y)会修改est),而 dask 的集合大多是 immutable(不可变的)。尝试了几种不同的思路后,我决定让 dask-learn 的估计器也是 immutable 的(网格搜索除外,稍后会详细说明)。这使得代码更容易理解,但也意味着在使用 dask-learn 估计器时需要写成est = est.fit(X, y)。 -
GridSearchCV带来了另一个问题。由于refit关键字,其实现无法在一次数据遍历中完成。这意味着我们无法构建一个同时描述网格搜索和 refit 的单一图,这阻止了它以惰性方式执行。我曾考虑移除这个关键字,但最终决定让fit方法立即执行。这意味着GridSearchCV与库中其他类之间存在一些脱节,我不喜欢这一点。但另一方面,这也意味着这个版本的GridSearchCV可以直接替代 scikit-learn 中的版本。 -
这里提出的方法很好,但实际上只有在需要避免重复工作且重复工作开销很大时才真正有益。如果只使用一个估计器(而不是 pipeline)重复上述过程,性能将与 joblib 版本相同(或稍差)。同样,如果重复步骤的开销很小,性能差异也会小得多(尝试使用 SelectKBest 而不是
PCA来尝试上述过程)。 -
从本地执行轻松切换到分布式执行的能力很好,但 distributed 也包含一个 joblib 前端,同样可以轻松实现这一点。
寻求帮助
我不是机器学习专家。这些内容有用吗?您有什么改进建议(或者更好的,能否提交改进的 PR :))?请随时在下方评论区或在 github 上与我联系。
本工作由 Continuum Analytics 和 XDATA 项目(作为 Blaze Project 的一部分)支持。
博客评论由 Disqus 提供支持