在集群上使用 Dask DataFrames 的分布式 Pandas
这项工作由 Continuum Analytics、XDATA 项目以及来自 Moore 基金会 的数据驱动发现计划支持。
摘要
Dask Dataframe 扩展了流行的 Pandas 库,使其能够在分布式集群上处理大数据集。我们通过在一个通用数据集上运行常见的数据框操作来展示其能力。我们将这些计算分解为以下几个部分:
- 引言:Pandas 直观且快速,但需要 Dask 来扩展规模
- 读取 CSV 和基本操作
- 读取 CSV
- 基本聚合和分组
- 连接和相关性
- 重洗和时间序列
- Parquet 输入/输出
- 总结思考
- 我们可以做得更好的地方
附带图表
在整篇文章中,我们在计算示例中附带运行配置文件,准确地说明在我们的集群上何时何地运行了哪些任务。这些配置文件是交互式的 Bokeh 图表,其中包含集群中每个 worker 在一段时间内运行的每个任务。例如,以下 read_csv 计算会生成以下配置文件:
>>> df = dd.read_csv('s3://dask-data/nyc-taxi/2015/*.csv')
如果您正在通过联合网站(例如 planet.python.org)或通过 RSS 阅读器阅读此文,则这些图表将不会显示。您可能需要直接访问 /2017/01/12/dask-dataframes。
Dask.dataframe 将数据读取分解为许多不同类型的小任务。例如,读取字节并将这些字节解析为 pandas dataframes。每个矩形对应一个任务。Y 轴列出了每个 worker 进程。我们在 8 台机器上分布了 64 个进程,所以有 64 行。您可以将鼠标悬停在任何矩形上,以获取关于该任务的更多信息。您还可以使用右上角的工具来缩放并聚焦于计算中的不同区域。在此计算中,我们可以看到 worker 交替进行从 S3 读取字节(浅绿色)和将字节解析为 dataframes(深绿色)。整个计算花费了大约一分钟,并且大部分 worker 在整个过程中都很忙碌(空白区域很少)。Worker 间的通信总是用红色表示(在此相对简单的计算中没有)。
引言
Pandas 为表格数据提供了直观、强大且快速的数据分析体验。然而,由于 Pandas 仅使用一个执行线程并要求所有数据同时加载到内存中,它对远超千兆字节规模的数据集扩展性不好。这部分功能是缺失的。人们通常会转向 HDFS 上的 Spark DataFrames 或适当的关系型数据库以解决此扩展性问题。Dask 是一个用于并行和分布式计算的 Python 库,旨在填补 PyData 项目(NumPy、Pandas、Scikit-Learn 等)之间对并行性的需求。Dask dataframes 结合了 Dask 和 Pandas,提供了一个忠实的 Pandas“大数据”版本,可在集群上并行运行。
我之前写过关于这个主题的文章。这篇博客文章更新,并将重点关注性能和新特性,例如快速重洗和 Parquet 格式。
CSV 数据和基本操作
我在 EC2 上有一个八节点的集群,类型为 m4.2xlarges(每个有八个核心,30GB 内存)。Dask 在每个节点上运行,每个核心一个进程。
我们有作为 S3 上的 12 个 CSV 文件的2015 年纽约市黄出租车数据。我们使用 s3fs 简要查看数据。
>>> import s3fs
>>> s3 = S3FileSystem()
>>> s3.ls('dask-data/nyc-taxi/2015/')
['dask-data/nyc-taxi/2015/yellow_tripdata_2015-01.csv',
'dask-data/nyc-taxi/2015/yellow_tripdata_2015-02.csv',
'dask-data/nyc-taxi/2015/yellow_tripdata_2015-03.csv',
'dask-data/nyc-taxi/2015/yellow_tripdata_2015-04.csv',
'dask-data/nyc-taxi/2015/yellow_tripdata_2015-05.csv',
'dask-data/nyc-taxi/2015/yellow_tripdata_2015-06.csv',
'dask-data/nyc-taxi/2015/yellow_tripdata_2015-07.csv',
'dask-data/nyc-taxi/2015/yellow_tripdata_2015-08.csv',
'dask-data/nyc-taxi/2015/yellow_tripdata_2015-09.csv',
'dask-data/nyc-taxi/2015/yellow_tripdata_2015-10.csv',
'dask-data/nyc-taxi/2015/yellow_tripdata_2015-11.csv',
'dask-data/nyc-taxi/2015/yellow_tripdata_2015-12.csv']
这些数据太大,无法在单台计算机上放入 Pandas 中。然而,如果我们将其分解成许多小块并将这些小块加载到集群中的不同计算机上,则可以放入内存中。
我们将一个客户端连接到我们的 Dask 集群,该集群由一个集中式的 dask-scheduler 进程和在集群中每台机器上运行的几个 dask-worker 进程组成。
from dask.distributed import Client
client = Client('scheduler-address:8786')
然后我们使用 dask.dataframe 加载 CSV 数据,它看起来和用起来就像 Pandas,尽管它实际上协调着数百个小的 Pandas dataframes。这需要大约一分钟来加载和解析。
import dask.dataframe as dd
df = dd.read_csv('s3://dask-data/nyc-taxi/2015/*.csv',
parse_dates=['tpep_pickup_datetime', 'tpep_dropoff_datetime'],
storage_options={'anon': True})
df = client.persist(df)
这将我们在 S3 上的 12 个 CSV 文件切分成几百个字节块,每个大小为 64MB。然后在每个这样的 64MB 块上,我们调用 pandas.read_csv 在我们的集群上创建几百个 Pandas dataframes,每个字节块对应一个。我们的单个 Dask Dataframe 对象 df 协调着所有这些 Pandas dataframes。因为我们只是使用 Pandas 调用,所以 Dask dataframes 可以非常容易地使用 Pandas 的所有技巧。例如,我们可以在 dd.read_csv 中使用 pd.read_csv 中的大多数关键字参数,而无需重新学习任何东西。
这些数据在磁盘上约 20GB,或在内存中约 60GB。它不算巨大,但也比我们希望在笔记本电脑上管理的数据量要大,特别是当我们看重交互性时。上面的交互式图像是一个随时间变化的轨迹图,显示了我们 64 个核心在任何给定时刻正在做什么。通过将鼠标悬停在矩形上,您可以看到核心在从 S3 下载字节范围和使用 pandas.read_csv 解析这些字节之间切换。
我们的数据集包括 2015 年纽约市的每一次出租车行程,包括行程的开始时间和地点、结束时间和地点、票价明细等等。
>>> df.head()
| VendorID | tpep_pickup_datetime | tpep_dropoff_datetime | passenger_count | trip_distance | pickup_longitude | pickup_latitude | RateCodeID | store_and_fwd_flag | dropoff_longitude | dropoff_latitude | payment_type | fare_amount | extra | mta_tax | tip_amount | tolls_amount | improvement_surcharge | total_amount | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 2015-01-15 19:05:39 | 2015-01-15 19:23:42 | 1 | 1.59 | -73.993896 | 40.750111 | 1 | N | -73.974785 | 40.750618 | 1 | 12.0 | 1.0 | 0.5 | 3.25 | 0.0 | 0.3 | 17.05 |
| 1 | 1 | 2015-01-10 20:33:38 | 2015-01-10 20:53:28 | 1 | 3.30 | -74.001648 | 40.724243 | 1 | N | -73.994415 | 40.759109 | 1 | 14.5 | 0.5 | 0.5 | 2.00 | 0.0 | 0.3 | 17.80 |
| 2 | 1 | 2015-01-10 20:33:38 | 2015-01-10 20:43:41 | 1 | 1.80 | -73.963341 | 40.802788 | 1 | N | -73.951820 | 40.824413 | 2 | 9.5 | 0.5 | 0.5 | 0.00 | 0.0 | 0.3 | 10.80 |
| 3 | 1 | 2015-01-10 20:33:39 | 2015-01-10 20:35:31 | 1 | 0.50 | -74.009087 | 40.713818 | 1 | N | -74.004326 | 40.719986 | 2 | 3.5 | 0.5 | 0.5 | 0.00 | 0.0 | 0.3 | 4.80 |
| 4 | 1 | 2015-01-10 20:33:39 | 2015-01-10 20:52:58 | 1 | 3.00 | -73.971176 | 40.762428 | 1 | N | -74.004181 | 40.742653 | 2 | 15.0 | 0.5 | 0.5 | 0.00 | 0.0 | 0.3 | 16.30 |
基本聚合和分组
作为一项快速练习,我们计算数据框的长度。当我们调用 len(df) 时,Dask.dataframe 会将其转化为在每个组成的 Pandas dataframe 上进行多次 len 调用,随后将中间结果通信到一个节点,最后对所有中间长度求 sum。
>>> len(df)
146112989
这大约需要 400-500ms。您可以看到左侧快速执行了几百次长度计算,随后有一些延迟,然后是一些数据传输(图中红色条),最后是一个求和调用。
更复杂的操作,例如简单的分组,看起来类似,尽管有时会有更多的通信。在整篇文章中,我们将进行越来越复杂的计算,我们的配置文件也将因此变得越来越丰富。这里我们计算按乘客数量分组的平均行程距离。我们发现单人和双人行程平均距离更长。我们通过执行许多小的 Pandas 分组,然后巧妙地组合它们的结果来实现这个大数据分组。
>>> df.groupby(df.passenger_count).trip_distance.mean().compute()
passenger_count
0 2.279183
1 15.541413
2 11.815871
3 1.620052
4 7.481066
5 3.066019
6 2.977158
9 5.459763
7 3.303054
8 3.866298
Name: trip_distance, dtype: float64
作为一个更复杂的操作,我们来看看纽约人按一天中的小时和一周中的天给小费的慷慨程度。
df2 = df[(df.tip_amount > 0) & (df.fare_amount > 0)] # filter out bad rows
df2['tip_fraction'] = df2.tip_amount / df2.fare_amount # make new column
dayofweek = (df2.groupby(df2.tpep_pickup_datetime.dt.dayofweek)
.tip_fraction
.mean())
hour = (df2.groupby(df2.tpep_pickup_datetime.dt.hour)
.tip_fraction
.mean())
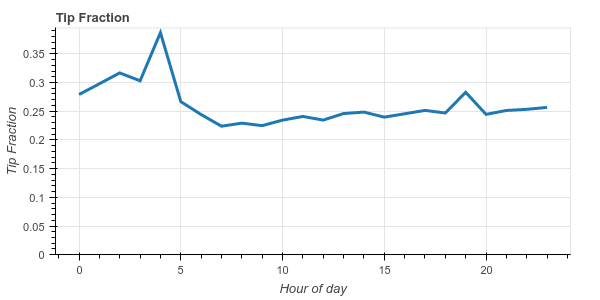
我们看到纽约人通常相当慷慨,平均小费约为 20%-25%。我们还注意到,他们在凌晨 4 点变得非常慷慨,平均小费达到 38%。
这个更复杂的操作使用了更多 Dask dataframe API 的功能(它模仿了 Pandas API)。Pandas 用户应该觉得上面的代码相当熟悉。我们移除票价为零或小费为零的行(并非所有小费都记录下来),创建一个新列,它是小费金额与票价金额的比率,然后按一周中的天和一天中的小时进行分组,计算每个小时/天的平均小费比例。
Dask 通过在集群上执行数千个小的 Pandas 调用来评估此计算(尝试单击上面图像右上角的滚轮缩放图标并放大)。结果在大约 3 秒内返回。
连接和相关性
为了展示更多基本功能,我们将这个 Dask dataframe 与一个包含一些更隐晦列名称的较小 Pandas dataframe 进行连接。然后我们将关联两个派生列,以确定支付现金与记录的小费之间是否存在关系。
>>> payments = pd.Series({1: 'Credit Card',
2: 'Cash',
3: 'No Charge',
4: 'Dispute',
5: 'Unknown',
6: 'Voided trip'})
>>> df2 = df.merge(payments, left_on='payment_type', right_index=True)
>>> df2.groupby(df2.payment_name).tip_amount.mean().compute()
payment_name
Cash 0.000217
Credit Card 2.757708
Dispute -0.011553
No charge 0.003902
Unknown 0.428571
Name: tip_amount, dtype: float64
我们看到,信用卡交易的平均小费是 2.75 美元,而现金交易的平均小费非常接近零。初看起来,似乎现金小费没有被报告。为了进一步调查这一点,让我们计算支付现金和零小费之间的皮尔逊相关性。同样,这段代码对于 Pandas 用户来说应该非常熟悉。
zero_tip = df2.tip_amount == 0
cash = df2.payment_name == 'Cash'
dd.concat([zero_tip, cash], axis=1).corr().compute()
| tip_amount | payment_name | |
|---|---|---|
| tip_amount | 1.000000 | 0.943123 |
| payment_name | 0.943123 | 1.000000 |
因此,我们看到标准操作,例如行过滤、列选择、分组聚合、与 Pandas dataframe 连接、相关性等等,都看起来和用起来像 Pandas 接口。此外,通过配置文件图,我们看到大部分时间都花在 worker 上运行 Pandas 函数,因此在大多数情况下,Dask.dataframe 增加的开销相对较小。这些图中矩形表示的小函数就是 Pandas 函数。例如,如果您将鼠标悬停在上面图中的矩形上,会看到许多标有 merge 的矩形。这只是标准的 pandas.merge 函数,我们喜欢并知道它在内存中非常快。
重洗和时间序列
分布式数据框专家知道,上述操作都不需要进行重洗(shuffle)。也就是说,我们可以用相对较少的节点间通信完成大部分工作。然而并非所有操作都能避免这种通信,有时我们需要在不同 worker 之间交换大部分数据。
例如,如果我们的数据集按客户 ID 排序,但我们想按时间排序,那么我们需要将所有一月份的行收集到一个 Pandas dataframe 中,将所有二月份的行收集到另一个中,等等。这个操作称为重洗(shuffle),并且是分组应用(groupby-apply)、在非索引列上的分布式连接等计算的基础。
使用 dask.dataframe 无需执行重洗也可以做很多事情,但有时是必要的。在下面的示例中,我们按上车时间排序数据。这将允许快速查找、快速连接和快速时间序列操作,这些都是常见情况。我们提前执行一次重洗,以使未来的所有计算都快速。
我们将上车时间列设置为索引。这需要 25-40 秒不等,并且很大程度上受限于网络(60GB 数据,一些文本,AWS 上八台各有八个核心的机器,非增强网络)。这还需要在集群上运行大约 16000 个微小任务。值得放大查看下面的图。
>>> df = c.persist(df.set_index('tpep_pickup_datetime'))
这个操作是昂贵的,比 Pandas 在所有数据都在同一台计算机的同一内存空间中时昂贵得多。现在是一个好时机指出,您应该只在 Pandas 等工具无法满足需求时才使用 Dask.dataframe 和 Spark 等分布式工具。我们只有在绝对必要时才应转向分布式系统。然而,当它变得必要时,很高兴知道 Dask.dataframe 可以忠实地执行 Pandas 操作,即使其中一些操作需要更长时间。
作为这次重洗的结果,我们的数据现在按时间很好地排序了,这将使未来的操作接近最优。我们可以通过快速查看第一项、最后一项和特定日期项来了解数据集是如何按上车时间排序的。
>>> df.head() # has the first entries of 2015
| VendorID | tpep_dropoff_datetime | passenger_count | trip_distance | pickup_longitude | pickup_latitude | RateCodeID | store_and_fwd_flag | dropoff_longitude | dropoff_latitude | payment_type | fare_amount | extra | mta_tax | tip_amount | tolls_amount | improvement_surcharge | total_amount | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tpep_pickup_datetime | ||||||||||||||||||
| 2015-01-01 00:00:00 | 2 | 2015-01-01 00:00:00 | 3 | 1.56 | -74.001320 | 40.729057 | 1 | N | -74.010208 | 40.719662 | 1 | 7.5 | 0.5 | 0.5 | 0.0 | 0.0 | 0.3 | 8.8 |
| 2015-01-01 00:00:00 | 2 | 2015-01-01 00:00:00 | 1 | 1.68 | -73.991547 | 40.750069 | 1 | N | 0.000000 | 0.000000 | 2 | 10.0 | 0.0 | 0.5 | 0.0 | 0.0 | 0.3 | 10.8 |
| 2015-01-01 00:00:00 | 1 | 2015-01-01 00:11:26 | 5 | 4.00 | -73.971436 | 40.760201 | 1 | N | -73.921181 | 40.768269 | 2 | 13.5 | 0.5 | 0.5 | 0.0 | 0.0 | 0.0 | 14.5 |
>>> df.tail() # has the last entries of 2015
| VendorID | tpep_dropoff_datetime | passenger_count | trip_distance | pickup_longitude | pickup_latitude | RateCodeID | store_and_fwd_flag | dropoff_longitude | dropoff_latitude | payment_type | fare_amount | extra | mta_tax | tip_amount | tolls_amount | improvement_surcharge | total_amount | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tpep_pickup_datetime | ||||||||||||||||||
| 2015-12-31 23:59:56 | 1 | 2016-01-01 00:09:25 | 1 | 1.00 | -73.973900 | 40.742893 | 1 | N | -73.989571 | 40.750549 | 1 | 8.0 | 0.5 | 0.5 | 1.85 | 0.0 | 0.3 | 11.15 |
| 2015-12-31 23:59:58 | 1 | 2016-01-01 00:05:19 | 2 | 2.00 | -73.965271 | 40.760281 | 1 | N | -73.939514 | 40.752388 | 2 | 7.5 | 0.5 | 0.5 | 0.00 | 0.0 | 0.3 | 8.80 |
| 2015-12-31 23:59:59 | 2 | 2016-01-01 00:10:26 | 1 | 1.96 | -73.997559 | 40.725693 | 1 | N | -74.017120 | 40.705322 | 2 | 8.5 | 0.5 | 0.5 | 0.00 | 0.0 | 0.3 | 9.80 |
>>> df.loc['2015-05-05'].head() # has the entries for just May 5th
| VendorID | tpep_dropoff_datetime | passenger_count | trip_distance | pickup_longitude | pickup_latitude | RateCodeID | store_and_fwd_flag | dropoff_longitude | dropoff_latitude | payment_type | fare_amount | extra | mta_tax | tip_amount | tolls_amount | improvement_surcharge | total_amount | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tpep_pickup_datetime | ||||||||||||||||||
| 2015-05-05 | 2 | 2015-05-05 00:00:00 | 1 | 1.20 | -73.981941 | 40.766460 | 1 | N | -73.972771 | 40.758007 | 2 | 6.5 | 1.0 | 0.5 | 0.00 | 0.00 | 0.3 | 8.30 |
| 2015-05-05 | 1 | 2015-05-05 00:10:12 | 1 | 1.70 | -73.994675 | 40.750507 | 1 | N | -73.980247 | 40.738560 | 1 | 9.0 | 0.5 | 0.5 | 2.57 | 0.00 | 0.3 | 12.87 |
| 2015-05-05 | 1 | 2015-05-05 00:07:50 | 1 | 2.50 | -74.002930 | 40.733681 | 1 | N | -74.013603 | 40.702362 | 2 | 9.5 | 0.5 | 0.5 | 0.00 | 0.00 | 0.3 | 10.80 |
因为我们确切知道哪个 Pandas dataframe 包含哪些数据,所以我们可以非常快速地执行像这样的行级局部查询。在解释器或 Notebook 中按下 Enter 键到获取结果的总往返时间约为 40ms。作为参考,40ms 是以 25 Hz 播放的电影中两帧之间的延迟。这意味着它足够快,人类用户感觉此查询完全流畅。
时间序列
此外,一旦我们有了好的日期时间索引,Pandas 的所有时间序列功能都可供我们使用。
例如,我们可以按天进行重采样
>>> (df.passenger_count
.resample('1d')
.mean()
.compute()
.plot())
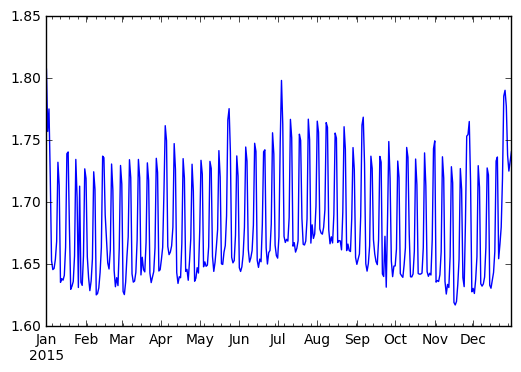
我们在此观察到强烈的周期性信号。周末的乘客数量可靠地更高。
我们可以在大约一秒钟内执行一个滚动聚合
>>> s = client.persist(df.passenger_count.rolling(10).mean())
因为 Dask.dataframe 继承了 Pandas 索引,所有这些操作都变得非常快速和直观。
Parquet
Pandas 标准的“快速”推荐存储解决方案通常是 HDF5 数据格式。不幸的是,HDF5 文件格式对于分布式计算来说并不理想,因此大多数 Dask dataframe 用户过去不得不改用 CSV。这是不幸的,因为 CSV 很慢,不支持部分查询(您无法只读取一列),并且也不受另一种标准分布式 Dataframe 解决方案 Spark 的良好支持。这使得数据来回迁移变得困难。
幸运的是,现在有两个不错的 Python Parquet 读取器可用,Parquet 是一种快速的列式二进制存储格式,可以在分布式数据存储上很好地分片,例如 Hadoop 文件系统(HDFS,不要与 HDF5 混淆)和亚马逊 S3。已经很快的 Parquet-cpp 项目通过 Arrow 增加了对 Python 和 Pandas 的支持,而 Fastparquet 项目(它是 纯 Python parquet 库的一个分支)通过使用 NumPy 和 Numba 提高了速度。
在底层使用 Fastparquet,Dask.dataframe 用户现在可以愉快地读写 Parquet 文件。这提高了速度,降低了存储成本,并提供了一种 Dask dataframes 和 Spark dataframes 都能理解的共享格式,提高了在同一工作流程中使用这两个计算系统的能力。
将我们的 Dask dataframe 写入 S3 可以像下面这样简单:
df.to_parquet('s3://dask-data/nyc-taxi/tmp/parquet')
然而,我们还可以使用各种选项,通过压缩、编码等方式更紧凑地存储我们的数据。专家用户可能会认出下面的一些术语。
df = df.astype({'VendorID': 'uint8',
'passenger_count': 'uint8',
'RateCodeID': 'uint8',
'payment_type': 'uint8'})
df.to_parquet('s3://dask-data/nyc-taxi/tmp/parquet',
compression='snappy',
has_nulls=False,
object_encoding='utf8',
fixed_text={'store_and_fwd_flag': 1})
然后我们可以使用 dd.read_parquet 函数读回我们已良好索引的 dataframe。
>>> df2 = dd.read_parquet('s3://dask-data/nyc-taxi/tmp/parquet')
这里的主要好处是我们可以快速地对单列进行计算。以下计算在大约 6 秒内运行完成,即使我们开始时内存中没有任何数据(回想一下,我们开始这篇博客文章时调用 read_csv 和 Client.persist 花费了一分钟)。
>>> df2.passenger_count.value_counts().compute()
1 102991045
2 20901372
5 7939001
3 6135107
6 5123951
4 2981071
0 40853
7 239
8 181
9 169
Name: passenger_count, dtype: int64
总结思考
随着最近增加了更快的重洗和 Parquet 支持,Dask dataframes 变得显著更具吸引力。这篇博客文章给出了一些常见计算类别,并附带它们在小集群上执行的精确配置文件。希望人们觉得这种 Pandas 语法和可伸缩计算的组合很有用。
现在也是一个好时机提醒大家,Dask dataframe 只是 Dask 项目中的众多模块之一。Dataframes 当然很好,但 Dask 的主要优势在于其灵活性,可以超越简单的数据框计算来处理更复杂的问题。
了解更多
如果您想了解更多关于 Dask dataframe、Dask 分布式系统或其他组件,您应该查看以下文档:
此处介绍的工作流程已收录在以下 Notebook 中(以及其他示例):
我们可以做得更好的地方
和所有计算相关的文章一样,我们包含一个关于出现的问题或可以改进的地方的部分。
len(df)的 400ms 计算时间相较于先前版本有所退步,先前版本中约为 100ms。我们在许多小的 worker 间通信中陷入了困境。- 如果能在更大规模下重复此计算会很好。实际应用中的 Dask 部署通常接近 1000 个核心,而非我们这里的 64 个核心集群;数据集通常在 TB 规模,而非我们 60 GB 的纽约出租车数据集。不幸的是,很难找到具有代表性的大型开放数据集。
- Parquet 的计时结果不错,但仍有改进空间。在读取 Thrift 头部时,我们似乎正在对 S3 执行许多耗时的小查询。
- 如果能支持两种 Python Parquet 读取器会很好,即使用 Numba 的解决方案 fastparquet 和 C++ 解决方案 parquet-cpp。
博客评论由 Disqus 提供支持