Dask 0.14.3 发布
这项工作得到了 Continuum Analytics 以及 Moore Foundation 的数据驱动发现倡议的支持。
我很高兴地宣布 Dask 版本 0.14.3 发布了。此版本包含各种性能和功能改进。这篇博文介绍了自 3 月 22 日上次发布以来的一些值得注意的特性和变化。
像往常一样,您可以通过 conda-forge 进行 conda 安装
conda install -c conda-forge dask distributed
或者您可以通过 PyPI 进行 pip 安装
pip install dask[complete] --upgrade
Conda 包应在几天内出现在默认通道中。
数组
稀疏数组
Dask.arrays 现在支持稀疏数组以及密集/稀疏混合数组。
>>> import dask.array as da
>>> x = da.random.random(size=(10000, 10000, 10000, 10000),
... chunks=(100, 100, 100, 100))
>>> x[x < 0.99] = 0
>>> import sparse
>>> s = x.map_blocks(sparse.COO) # parallel array of sparse arrays
为了支持稀疏数组,我们做了两件事
- 让 dask.array 支持 NumPy 以外的 ndarray 容器,只要它们与 API 兼容
- 构建了一个小的 稀疏 数组库,它与 numpy.ndarray 兼容 API
这个过程非常容易,并且可以扩展到其他系统。这还允许在同一个 Dask 数组中使用不同类型的 ndarrays,只要数组之间的交互定义良好(使用标准 NumPy 协议,如 __array_priority__ 等)。
文档: https://dask.org.cn/en/latest/array-sparse.html
更新:已有一个 pull request 用于 Masked 数组
重构的 FFT 代码
da.fft 子模块已扩展到包含 np.fft 中的大多数函数,但需要注意的是多维 FFT 仅沿单块维度工作。尽管如此,考虑到当前的重新分块速度尚可,这对于大型图像堆栈非常有用。
文档: https://dask.org.cn/en/latest/array-api.html#fast-fourier-transforms
构造函数插件
现在,每当构造 dask 数组时,您都可以运行任意代码。这使用户能够构建自己的策略,如重新分块、警告用户或急切评估。dask.array 插件接收一个 dask.array,并返回一个新的 dask 数组,或者返回 None,在这种情况下将返回原始数组。
>>> def f(x):
... print('%d bytes' % x.nbytes)
>>> with dask.set_options(array_plugins=[f]):
... x = da.ones((10, 1), chunks=(5, 1))
... y = x.dot(x.T)
80 bytes
80 bytes
800 bytes
800 bytes
例如,这可用于将 dask.array 代码转换为 numpy 代码,以便快速识别 bug
>>> with dask.set_options(array_plugins=[lambda x: x.compute()]):
... x = da.arange(5, chunks=2)
>>> x # this was automatically converted into a numpy array
array([0, 1, 2, 3, 4])
或者在用户不小心生成大块数组时发出警告
def warn_on_large_chunks(x):
shapes = list(itertools.product(*x.chunks))
nbytes = [x.dtype.itemsize * np.prod(shape) for shape in shapes]
if any(nb > 1e9 for nb in nbytes):
warnings.warn("Array contains very large chunks")
with dask.set_options(array_plugins=[warn_on_large_chunks]):
...
这些功能受到了气候科学界的强烈要求,该领域既服务于高技能的计算机科学家,也服务于那些在分块细节方面遇到问题的技术水平较低的气候科学家。
DataFrames
Dask.dataframe 的变化既多又小,因此很难在一篇博文中对近期变化进行代表性说明。这些变化通常包括追踪新的 Pandas 开发,或修复角落案例中的细微不一致(这种情况有很多)。
不过,以下是两个亮点
按时间间隔的滚动窗口
>>> s.rolling('2s').count().compute()
2017-01-01 00:00:00 1.0
2017-01-01 00:00:01 2.0
2017-01-01 00:00:02 2.0
2017-01-01 00:00:03 2.0
2017-01-01 00:00:04 2.0
2017-01-01 00:00:05 2.0
2017-01-01 00:00:06 2.0
2017-01-01 00:00:07 2.0
2017-01-01 00:00:08 2.0
2017-01-01 00:00:09 2.0
dtype: float64
使用 Arrow 读取 Parquet 数据
Dask 现在支持使用 fastparquet(一个 Numpy/Numba 解决方案)以及 Arrow 和 Parquet-CPP 读取 Parquet 数据。
df = dd.read_parquet('/path/to/mydata.parquet', engine='fastparquet')
df = dd.read_parquet('/path/to/mydata.parquet', engine='arrow')
希望这项功能能增加这两个项目的使用,并为这些库带来更多反馈,以便它们能够继续提升 Python 对 Parquet 格式的访问能力。
图优化
Dask 在将任务图发送到调度器之前,会执行几轮简单的线性时间图优化。这些优化目前因集合类型而异,例如 dask.arrays 的优化与 dask.dataframes 不同。这些优化在某些情况下可以极大地提高性能,但也会增加开销,这对于大型图来说非常重要。
随着 Dask 深入更多社区,每个社区都有强大且不同的性能约束,我们发现需要允许每个社区定义自己的优化方案。默认设置没有改变,但现在您可以用自己的方案覆盖它们。这可以全局设置,也可以使用上下文管理器设置。
def my_optimize_function(graph, keys):
""" Takes a task graph and a list of output keys, returns new graph """
new_graph = {...}
return new_graph
with dask.set_options(array_optimize=my_optimize_function,
dataframe_optimize=None,
delayed_optimize=my_other_optimize_function):
x, y = dask.compute(x, y)
文档: https://dask.org.cn/en/latest/optimize.html#customizing-optimization
速度改进
此外,任务融合也得到了显著加速。这对于大型图来说非常重要,尤其是在 dask.array 计算中。
Web 诊断
分布式调度器的 Web 诊断页面现在从 dask 调度器进程内部提供服务。这既有好的一面,也有不好的一面
- 好:创建新的可视化效果更容易
- 坏:Dask 和 Bokeh 现在共享一个 CPU
由于 Bokeh 和 Dask 现在共享同一个 Tornado 事件循环,我们不再需要在它们之间发送消息,然后再发送到 Web 浏览器。Bokeh 服务器可以完全访问调度器的所有状态。这使得我们可以更容易地构建新的诊断页面。这已经存在一段时间了,但主要用于开发。在此版本中,我们已将新版本设置为默认,并关闭了旧版本。
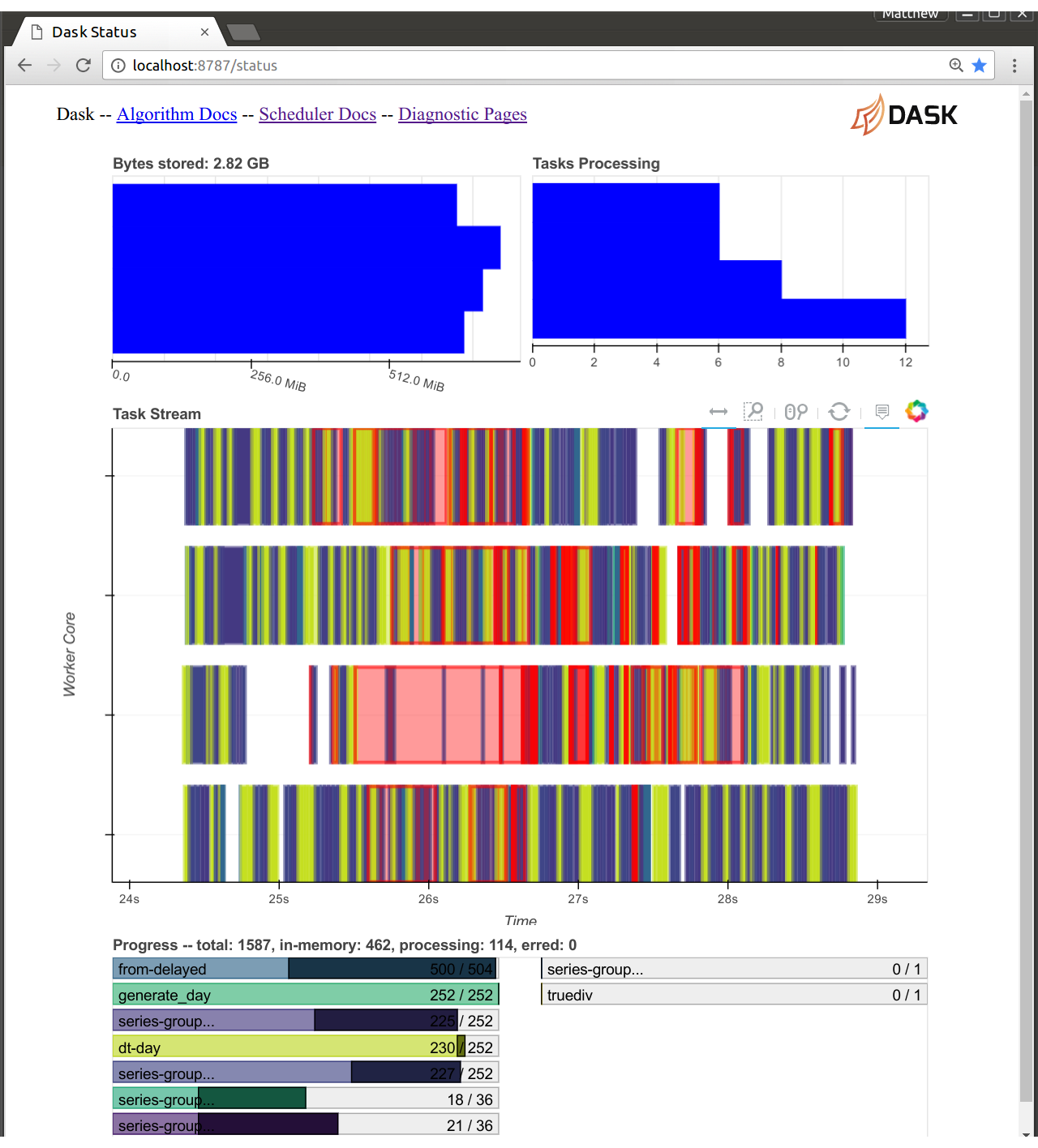
这里的代价是 Bokeh 调度器可能会占用 10-20% 的 CPU 使用率。如果您正在运行一个对调度器负担很重的计算,那么您可能需要关闭您的诊断页面。幸运的是,这种情况几乎不会发生。dask 调度器通常足够快,永远不会接近这个限制。
Tornado 困难
请注意,当前版本的 Bokeh (0.12.5) 和 Tornado (4.5) 不兼容。这已在开发版本中修复,使用 conda 安装没有问题,但如果您直接使用 pip 安装,可能会遇到不良行为。
Joblib
Dask.distributed Joblib 后端现在包含一个 scatter= 关键字,允许您将选定的变量预先分散到所有 Dask worker。这显著降低了开销,尤其是在大部分数据变化不大的机器学习工作负载中。
# Send the training data only once to each worker
with parallel_backend('dask.distributed', scheduler_host='localhost:8786',
scatter=[digits.data, digits.target]):
search.fit(digits.data, digits.target)
早期试验表明,scikit-learn 的 RandomForest 等计算可以在集群上很好地扩展,无需任何额外代码。
文档: https://distributed.dask.org.cn/en/latest/joblib.html
预加载脚本
启动 dask.distributed 调度器或 worker 时,人们通常希望包含一些自定义设置代码,例如配置日志记录器、通过某些网络系统进行身份验证等。如果从 Python 内部 启动调度器和 worker,这始终是可能的,但如果您想使用命令行界面,则比较麻烦。现在,您可以将自定义代码编写为单独的独立脚本,并让命令行界面在启动时为您运行它
# scheduler-setup.py
from distributed.diagnostics.plugin import SchedulerPlugin
class MyPlugin(SchedulerPlugin):
""" Prints a message whenever a worker is added to the cluster """
def add_worker(self, scheduler=None, worker=None, **kwargs):
print("Added a new worker at", worker)
def dask_setup(scheduler):
plugin = MyPlugin()
scheduler.add_plugin(plugin)
dask-scheduler --preload scheduler-setup.py
这使得人们更容易将 Dask 适应其特定机构的需求。
文档: https://distributed.dask.org.cn/en/latest/setup.html#customizing-initialization
网络接口(适用于 Infiniband)
许多人在高性能超级计算机上使用 Dask。这种硬件在许多方面与典型的商用集群或云服务不同,包括非常高性能的网络互连,如 InfiniBand。通常这些系统也拥有普通以太网和其他网络。当您自己的笔记本电脑同时拥有以太网和无线网络时,您可能对此很熟悉
$ ifconfig
lo Link encap:Local Loopback # Localhost
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
eth0 Link encap:Ethernet HWaddr XX:XX:XX:XX:XX:XX # Ethernet
inet addr:192.168.0.101
...
ib0 Link encap:Infiniband # Fast InfiniBand
inet addr:172.42.0.101
Dask 用于确定网络接口的默认系统通常会默认选择以太网。如果您在 HPC 系统上,这可能不是最佳选择。您可以使用 --interface 关键字指示 Dask 选择特定的网络接口
$ dask-scheduler --interface ib0
distributed.scheduler - INFO - Scheduler at: tcp://172.42.0.101:8786
$ dask-worker tcp://172.42.0.101:8786 --interface ib0
高效的 as_completed
as_completed 迭代器按照 futures 完成的顺序返回它们。它是许多使用 Dask 的异步应用程序的基础。
>>> x, y, z = client.map(inc, [0, 1, 2])
>>> for future in as_completed([x, y, z]):
... print(future.result())
2
0
1
它现在也可以等到结果也到达后才生成一个元素
>>> for future, result in as_completed([x, y, z], with_results=True):
... print(result)
2
0
1
并且还生成到目前为止已完成的所有 futures(和结果)。
>>> for futures in as_completed([x, y, z]).batches():
... print(client.gather(futures))
(2, 0)
(1,)
这两项改进都有助于减少异步应用程序中紧密内循环的开销。
示例博文在此:/2017/04/19/dask-glm-2
共同发布的库
此版本与许多其他相关库对齐发布,特别是 Pandas,以及一些用于访问数据的较小库,包括 s3fs、hdfs3、fastparquet 和 python-snappy,这些库在过去几个月都进行了大量更新。后者的许多工作由 Martin Durant 协调。
致谢
自 3 月 22 日 0.14.1 版本发布以来,以下人员为 dask/dask 仓库做出了贡献
- Antoine Pitrou
- Dmitry Shachnev
- Erik Welch
- Eugene Pakhomov
- Jeff Reback
- Jim Crist
- John A Kirkham
- Joris Van den Bossche
- Martin Durant
- Matthew Rocklin
- Michal Ficek
- Noah D Brenowitz
- Stuart Archibald
- Tom Augspurger
- Wes McKinney
- wikiped
自 3 月 22 日 1.16.1 版本发布以来,以下人员为 dask/distributed 仓库做出了贡献
- Antoine Pitrou
- Bartosz Marcinkowski
- Ben Schreck
- Jim Crist
- Jens Nie
- Krisztián Szűcs
- Lezyes
- Luke Canavan
- Martin Durant
- Matthew Rocklin
- Phil Elson
博客评论由 Disqus 提供支持