使用 Flyte 管理 Dask 工作负载
作者:Bernhard Stadlbauer
现在可以使用 Flyte 管理 dask 工作负载了 🎉!
主要优势包括:
- 每个 Flyte
task都会使用为该任务量身定制的 Docker 镜像启动一个临时的dask集群,确保客户端、调度器和工作节点之间的 Python 环境一致性。 - Flyte 将利用现有的 Kubernetes 基础设施来启动
dask集群。 - 原生支持 Spot/抢占式实例。
- 整个
dask任务可以被缓存。 - 在已有的 Flyte 环境中启用
dask支持只需几分钟。
这就是一个由四个工作节点组成的 dask 集群支持的 Flyte task 的样子:
from typing import List
from distributed import Client
from flytekit import task, Resources
from flytekitplugins.dask import Dask, WorkerGroup, Scheduler
def inc(x):
return x + 1
@task(
task_config=Dask(
scheduler=Scheduler(
requests=Resources(cpu="2")
),
workers=WorkerGroup(
number_of_workers=4,
limits=Resources(cpu="8", mem="32Gi")
)
)
)
def increment_numbers(list_length: int) -> List[int]:
client = Client()
futures = client.map(inc, range(list_length))
return client.gather(futures)
这个任务可以在本地使用标准的 distributed.Client() 运行,并且一旦在 Flyte 中注册后,可以扩展到任意大小的集群。
什么是 Flyte?
Flyte 是一个 Kubernetes 原生的工作流编排引擎。它最初在 Lyft 开发,现在是一个开源项目(Github)并成为 Linux 基金会下的一个毕业项目。它因其主要特性而区别于 Airflow 或 Argo 等类似工具,这些特性包括:
- 缓存/记忆先前执行的任务以提升性能
- Kubernetes 原生
- 使用 Python 定义工作流,而不是例如
YAML - 使用
Protobuf在任务和工作流之间实现强类型 - 在运行时动态生成工作流 DAG
- 能够在本地运行工作流
一个简单的工作流示例如下:
from typing import List
import pandas as pd
from flytekit import task, workflow, Resources
from flytekitplugins.dask import Dask, WorkerGroup, Scheduler
@task(
task_config=Dask(
scheduler=Scheduler(
requests=Resources(cpu="2")
),
workers=WorkerGroup(
number_of_workers=4,
limits=Resources(cpu="8", mem="32Gi")
)
)
)
def expensive_data_preparation(input_files: List[str]) -> pd.DataFrame:
# Expensive, highly parallel `dask` code
...
return pd.DataFrame(...) # Some large DataFrame, Flyte will handle serialization
@task
def train(input_data: pd.DataFrame) -> str:
# Model training, can also use GPU, etc.
...
return "s3://path-to-model"
@workflow
def train_model(input_files: List[str]) -> str:
prepared_data = expensive_data_preparation(input_files=input_files)
return train(input_data=prepared_data)
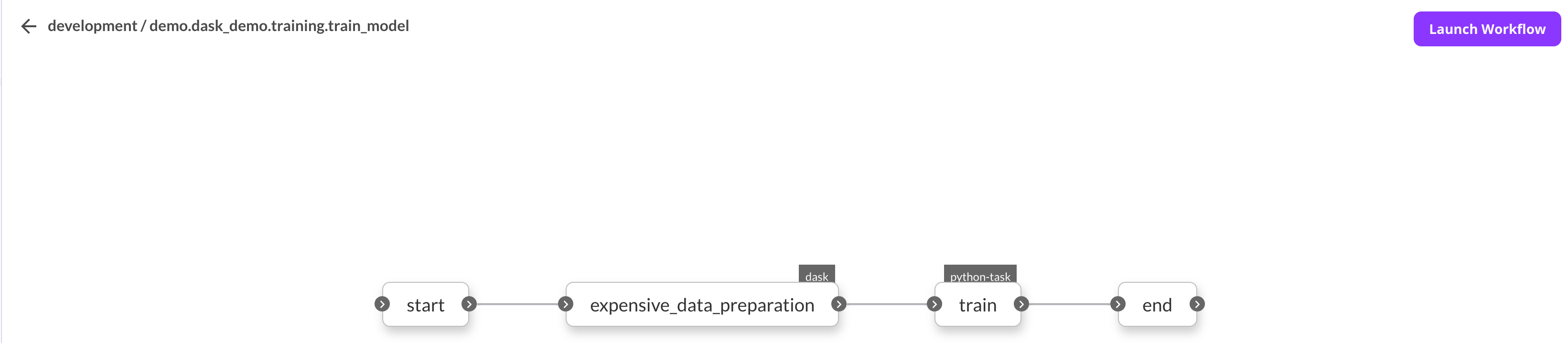
在上述示例中,expensive_data_preparation() 和 train() 都将在 Kubernetes 中各自的 Pod(s) 中运行,而 train_model() 工作流是一个 DSL,它创建了工作流的有向无环图 (DAG)。它将根据任务的输入和输出来确定任务的执行顺序。输入和输出类型(基于类型提示)将在注册时进行验证,以避免运行时出现意外。
在 Flyte 中注册后,可以从 UI 启动工作流。
为什么在 Flyte 中使用 dask 插件?
乍一看,Flyte 和 dask 在目标上有些相似,都能从用户函数创建 DAG,管理输入和输出等。然而,主要的理念差异在于它们的方法。虽然 dask 使用长期运行的工作节点来执行任务,但 Flyte 任务是一个指定的 Kubernetes Pod,这会在任务运行时产生显著的开销。
虽然 dask 任务的开销约为一毫秒(参见文档),但启动一个新的 Kubernetes Pod 需要几秒钟。 dask 工作节点的长期运行特性允许优化 DAG,将处理相同数据的任务安排在同一节点上运行,从而减少了工作节点间数据序列化(称为 shuffle)的需求。由于 Flyte 任务是临时的,这种优化无法实现,任务输出会序列化到 blob 存储中。
鉴于上述限制,为什么还要使用 Flyte?Flyte 的目的不是取代像 dask 或 Apache Spark 这样的工具,而是提供一个位于其上的编排层。虽然工作负载可以直接在 Flyte 中运行,例如训练单个 GPU 模型,但 Flyte 提供了与许多其他流行数据处理工具的丰富集成。
通过 Flyte 管理 dask 集群生命周期,每个 dask Flyte 任务都将在其独立的、由 Kubernetes pod 组成的 dask 集群上运行。当从 UI 触发 Flyte 任务时,Flyte 将启动一个为该任务量身定制的 dask 集群,然后用它来执行用户代码。这使得不同任务可以使用具有不同依赖项的 Docker 镜像,同时始终确保客户端、调度器和工作节点的依赖项一致。
在 Flyte 中运行 dask 任务需要哪些先决条件?
- Kubernetes 集群需要安装 dask operator。
- 需要 Flyte
1.3.0或更高版本。 - 需要在 Flyte propeller 配置中启用
dask插件。(参见文档) - 与任务关联的 Docker 镜像必须在其 Python 环境中安装
flytekitplugins-dask包。
内部原理是什么?
注意:以下内容仅供参考,对于仅使用插件的用户来说不是必需的。但是,它可能有助于更轻松地进行调试。
从高层面概述,在 Flyte 中启动 dask 任务时会发生以下步骤:
- 在 Kubernetes 中创建一个
FlyteWorkflow自定义资源 (CR)。 - Flyte Propeller (一个 Kubernetes Operator) 检测到工作流的创建。
- 该 operator 检查任务的 spec 并将其识别为
dask任务。它验证是否关联了所需的插件并找到dask插件。 - Flyte Propeller 中的
dask插件获取任务定义,并使用 dask-k8s-operator-go-client 创建一个DaskJob自定义资源。 - dask operator 获取
DaskJob资源并相应地运行任务。它启动一个 pod 运行 client/job-runner,一个 pod 运行调度器,以及在 Flyte 任务装饰器中指定的额外工作节点 pod。 - 在
dask任务运行期间,Flyte Propeller 持续监控DaskJob资源,等待它报告成功或失败。任务完成后或 Flyte 任务终止后,所有与dask相关的资源都将被清理。
有用链接
- Flyte 文档
- Flyte 社区
- flytekitplugins-dask 用户文档
- flytekitplugins-dask 部署文档
- dask-kubernetes 文档
- 关于 dask kubernetes operator 的博文
如果您有任何问题或疑虑,请随时联系。您可以通过 Flyte Slack 或 GitHub 联系 Bernhard Stadlbauer。
我要特别感谢 Jacob Tomlinson (Dask) 和 Dan Rammer (Flyte) 给予的所有帮助。没有你们的支持,这一切是不可能实现的!
博客评论由 Disqus 提供支持