Python 和 GPU:最新进展
作者:Matthew Rocklin
这篇博文是近期在 PASC 2019 大会上以讲座形式发表的。 讲座幻灯片在此。
执行摘要
我们正在改进 Python 中可伸缩 GPU 计算的现状。
本文介绍了当前的状态,并描述了未来的工作。它还总结并链接了近期发布的其他几篇深入探讨不同主题的博文,供感兴趣的读者参考。
概括来说,我们将简要介绍以下几个类别:
- 用 CUDA 编写的 Python 库,例如 CuPy 和 RAPIDS
- Python-CUDA 编译器,特别是 Numba
- 使用 Dask 对这些库进行扩展
- 使用 UCX 进行网络通信
- 使用 Conda 进行打包
GPU 加速 Python 库的性能
对于 Python 程序员来说,访问 GPU 性能的最简单方法可能是使用 GPU 加速的 Python 库。这些库提供了一系列常见的操作,这些操作经过精心调优,并且相互之间集成良好。
许多用户了解 PyTorch 和 TensorFlow 等深度学习库,但也有一些用于更通用计算的库。这些库倾向于模仿流行的 Python 项目的 API。
- GPU 上的 Numpy:CuPy
- GPU 上的 Numpy(续):Jax
- GPU 上的 Pandas:RAPIDS cuDF
- GPU 上的 Scikit-Learn:RAPIDS cuML
这些库构建了流行 Python 库(如 NumPy、Pandas 和 Scikit-Learn)的 GPU 加速变体。为了更好地理解相对性能差异,Peter Entschev 最近整理了一个 基准测试套件 来帮助进行比较。他生成了下图,显示了 GPU 和 CPU 之间的相对加速比。
其中有许多有趣的结果。Peter 在 他的博文 中对此进行了更深入的探讨。
更广泛地说,我们看到性能存在差异。我们在 CPU 上关于快慢的思维模式不一定适用于 GPU。幸运的是,由于一致的 API,熟悉 Python 的用户可以轻松尝试 GPU 加速,而无需学习 CUDA。
Numba:将 Python 编译到 CUDA
另请参阅这篇 关于 Numba stencils 的近期博文 以及随附的 GPU notebook
CuPy 和 RAPIDS 等 GPU 库中的内置操作涵盖了大多数常见操作。然而,在实际应用中,我们经常会遇到需要编写少量自定义代码的复杂情况。在这种情况下切换到 C/C++/CUDA 可能具有挑战性,特别是对于主要是 Python 开发人员的用户。这就是 Numba 发挥作用的地方。
Python 在 CPU 上也存在同样的问题。用户通常懒得学习 C/C++ 来编写快速的自定义代码。为了解决这个问题,出现了 Cython 或 Numba 等工具,它们让 Python 程序员无需学习 Python 语言以外的太多内容即可编写快速的数值代码。
例如,Numba 将下面的 for-loop 风格代码在 CPU 上加速了大约 500 倍,从缓慢的 Python 速度提升到快速的 C/Fortran 速度。
import numba # We added these two lines for a 500x speedup
@numba.jit # We added these two lines for a 500x speedup
def sum(x):
total = 0
for i in range(x.shape[0]):
total += x[i]
return total
能够在不切换 Python 上下文的情况下深入到低级高性能代码的能力非常有用,特别是如果你不了解 C/C++ 或没有为你设置好编译器链(这对大多数当前 Python 用户来说是事实)。
这一优势在 GPU 上更为显著。虽然许多 Python 程序员了解一点 C 语言,但很少有人了解 CUDA。即使他们了解,他们也可能在设置编译器工具和开发环境方面遇到困难。
介绍 numba.cuda.jit,Numba 的 CUDA 后端。Numba.cuda.jit 允许 Python 用户在不离开 Python 会话的情况下交互式地编写、编译和运行用 Python 编写的 CUDA 代码。下图展示了完全在 Jupyter Notebook 中编写一个用于平滑 2D 图像的 stencil 计算。
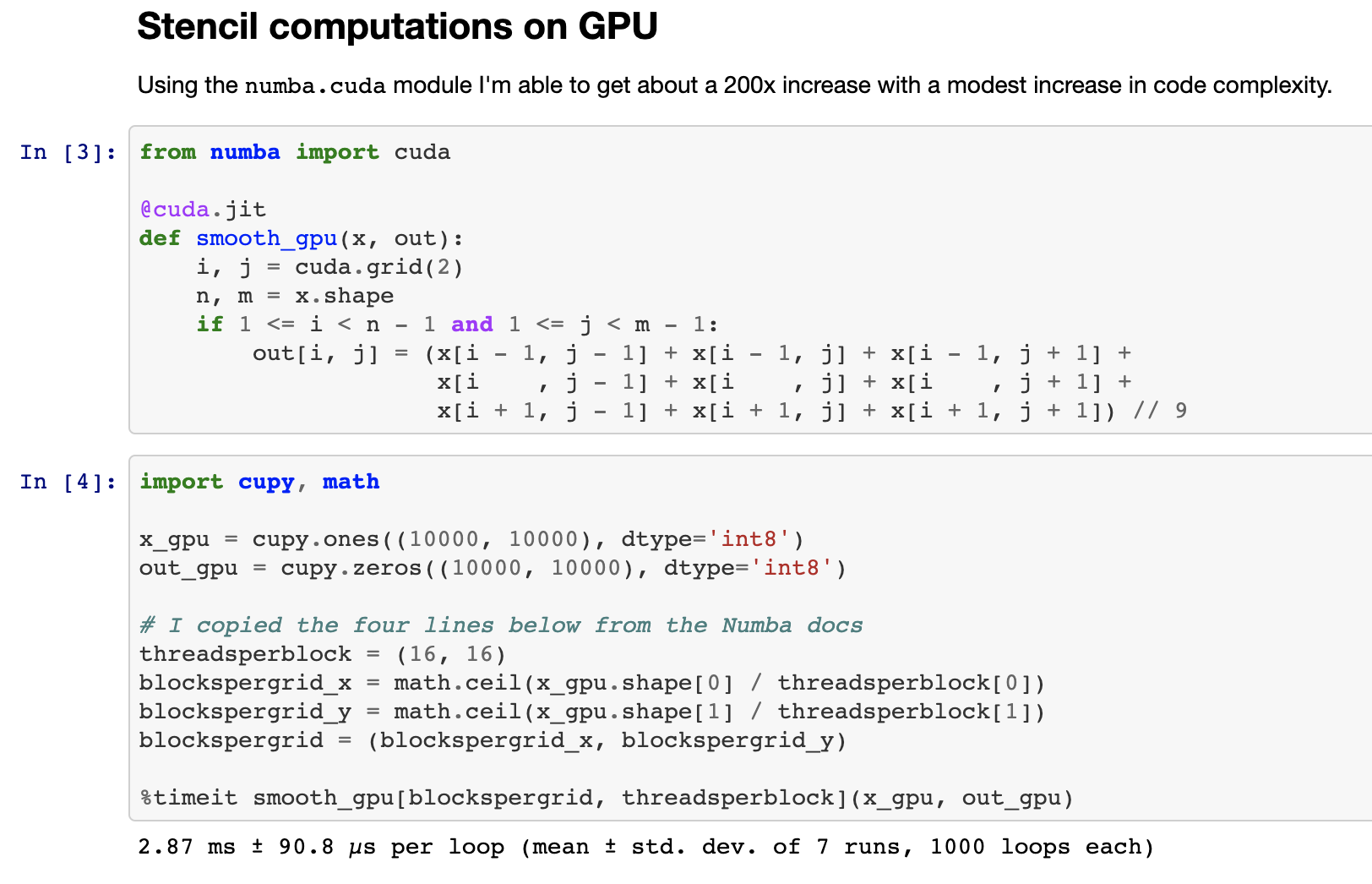
以下是 Numba CPU/GPU 代码的简化比较,以比较编程风格。GPU 代码比单个 CPU 核心快了 200 倍。
CPU – 600 毫秒
@numba.jit
def _smooth(x):
out = np.empty_like(x)
for i in range(1, x.shape[0] - 1):
for j in range(1, x.shape[1] - 1):
out[i, j] = x[i + -1, j + -1] + x[i + -1, j + 0] + x[i + -1, j + 1] +
x[i + 0, j + -1] + x[i + 0, j + 0] + x[i + 0, j + 1] +
x[i + 1, j + -1] + x[i + 1, j + 0] + x[i + 1, j + 1]) // 9
return out
或者如果我们使用更高级的 numba.stencil 装饰器……
@numba.stencil
def _smooth(x):
return (x[-1, -1] + x[-1, 0] + x[-1, 1] +
x[ 0, -1] + x[ 0, 0] + x[ 0, 1] +
x[ 1, -1] + x[ 1, 0] + x[ 1, 1]) // 9
GPU – 3 毫秒
@numba.cuda.jit
def smooth_gpu(x, out):
i, j = cuda.grid(2)
n, m = x.shape
if 1 <= i < n - 1 and 1 <= j < m - 1:
out[i, j] = (x[i - 1, j - 1] + x[i - 1, j] + x[i - 1, j + 1] +
x[i , j - 1] + x[i , j] + x[i , j + 1] +
x[i + 1, j - 1] + x[i + 1, j] + x[i + 1, j + 1]) // 9
Numba.cuda.jit 已经问世多年。它易于访问、成熟且有趣。如果你的机器中有 GPU 并且你对此感到好奇,我们强烈建议你尝试一下。
conda install numba
# or
pip install numba
>>> import numba.cuda
使用 Dask 进行扩展
如之前博文(1、2、3、4)所述,我们一直在泛化 Dask,使其不仅可以处理 Numpy 数组和 Pandas 数据帧,还可以处理任何看起来像 Numpy(例如 CuPy、Sparse 或 Jax)或像 Pandas(例如 RAPIDS cuDF)的对象,以便也能够对这些库进行扩展。这项工作进展顺利。这里有一个简短的视频,展示了 Dask 数组并行计算 SVD,并观察了当我们用 CuPy 替换 Numpy 库时会发生什么。
我们看到计算速度提高了大约 10 倍。最重要的是,我们只需进行一个小小的单行更改,就能够在 CPU 实现和 GPU 实现之间切换,同时仍然可以利用 Dask Array 的复杂算法,例如其并行 SVD 实现。
我们还看到了通信方面的相对减慢。总的来说,目前几乎所有非平凡的 Dask + GPU 工作都变得受限于通信。我们在计算方面已经足够快,以至于通信的相对重要性显著增加。我们正在通过下一个主题 UCX 来解决这个问题。
使用 UCX 进行通信
观看 Akshay Venkatesh 的这次讲座 或 查看幻灯片
另请参阅这篇 关于 UCX 和 Dask 的近期博文
我们一直在通过 UCX-Py 将 OpenUCX 库集成到 Python 中。UCX 提供了对 TCP、InfiniBand、共享内存和 NVLink 等传输机制的统一访问。UCX-Py 是首次使许多这些传输机制从 Python 语言中易于访问。
结合使用 UCX 和 Dask,我们能够获得显著的加速。以下是添加 UCX 前后的 SVD 计算跟踪图。
使用 UCX 前:
使用 UCX 后:
尽管如此,这里仍有很多工作要做(上面链接的博文在“未来工作”部分列出了几项)。
人们可以使用高度实验性的 conda 包来试用 UCX 和 UCX-Py
conda create -n ucx -c conda-forge -c jakirkham/label/ucx cudatoolkit=9.2 ucx-proc=*=gpu ucx ucx-py python=3.7
我们希望这项工作也能影响到使用 Infiniband 的 HPC 系统上的非 GPU 用户,甚至由于易于访问共享内存通信而影响到消费级硬件上的用户。
打包
在 之前的一篇博文 中,我们讨论了安装与系统上安装的 CUDA 驱动程序不匹配的 CUDA 启用软件包所面临的挑战。幸运的是,由于 Anaconda 的 Stan Seibert 和 Michael Sarahan 近期所做的工作,Conda 4.7 现在有一个特殊的 cuda 元软件包,其版本与安装的驱动程序版本一致。这将使将来用户更容易安装正确的软件包。
Conda 4.7 刚刚发布,除了 cuda 元软件包外,还附带了许多新功能。你可以在 此处 了解更多信息。
conda update conda
目前在打包领域仍有很多工作要做。每个构建 conda 包的人都有自己的方式,导致了令人头痛和异构性问题。这主要是由于缺乏像 Conda Forge 那样的集中式基础设施来构建和测试 CUDA 启用软件包。幸运的是,Conda Forge 社区正在与 Anaconda 和 NVIDIA 合作解决这个问题,尽管这可能需要一些时间。
总结
本文介绍了 Python 中 GPU 计算的一些工作进展。它还提供了一些供进一步阅读的链接。如果你想了解更多信息,我们将在下方列出这些链接:
- 幻灯片
- GPU 上的 Numpy:CuPy
- GPU 上的 Numpy(续):Jax
- GPU 上的 Pandas:RAPIDS cuDF
- GPU 上的 Scikit-Learn:RAPIDS cuML
- 基准测试套件
- Numba CUDA JIT notebook
- 关于 UCX 的讲座
- 关于 UCX 和 Dask 的博文
- Conda 4.7
博客评论由 Disqus 提供